【文本生成中的数据增强】:PyTorch训练集强化实战技巧
发布时间: 2024-12-11 16:34:19 阅读量: 6 订阅数: 11 

人脸图像生成-基于Pytorch实现的人脸图像生成StarGAN算法-附项目源码+流程教程-优质项目实战.zip

# 1. 文本生成与数据增强的基础概念
## 1.1 什么是文本生成与数据增强?
在人工智能领域,尤其是自然语言处理(NLP)领域,文本生成指的是利用算法自动化生成自然语言文本的技术。与传统的数据增强相比,数据增强在文本生成中扮演的角色是通过一系列策略和技术扩充训练数据集,提高模型泛化能力和性能。
## 1.2 数据增强的重要性
数据增强技术对于提高文本生成模型的鲁棒性和多样性至关重要。由于文本数据的多样性和复杂性,数据增强可以在不增加额外数据收集成本的情况下,通过变换现有数据来模拟新的训练样本,帮助模型更好地理解和生成语言。
## 1.3 常见文本数据增强技术
文本数据增强的方法多种多样,包括但不限于同义词替换、随机插入、删除或交换句子中的词、回译等。这些方法有助于提升模型在各种不同语言使用场景下的表现。
```python
# 示例代码:同义词替换
import nltk
from nltk.corpus import wordnet
def get_synonyms(word):
synonyms = set()
for syn in wordnet.synsets(word):
for lemma in syn.lemmas():
synonyms.add(lemma.name())
return list(synonyms)
# 用同义词替换原文中的单词
original_text = "The cat is on the mat."
words = original_text.split()
for i, word in enumerate(words):
synonyms = get_synonyms(word)
if synonyms:
words[i] = synonyms[0] # 简单地替换为第一个同义词
new_text = " ".join(words)
```
在上述代码片段中,我们使用了NLTK库来查找和替换文本中的同义词。这只是文本增强中的一种基本技术,实际应用中需要根据具体情况进行更复杂的处理。
# 2. PyTorch中的数据增强技术
在现代机器学习和深度学习实践中,数据增强是一种提高模型泛化能力的常见技术。PyTorch作为流行的研究和开发工具,提供了丰富的数据处理和增强功能。接下来,我们将深入探讨在PyTorch中实现数据增强的技术细节。
## 2.1 PyTorch数据加载与预处理
PyTorch提供了一个高效的接口,用于加载和处理数据集,这在数据增强过程中尤为重要。我们首先需要掌握如何使用Dataset与DataLoader类。
### 2.1.1 Dataset与DataLoader的使用
`Dataset`类是所有数据集的基类,其子类必须实现`__len__`和`__getitem__`两个方法,以分别返回数据集的大小和索引到的具体数据项。
```python
import torch
from torch.utils.data import Dataset, DataLoader
class CustomDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
# 实例化数据集
dataset = CustomDataset(data_list)
# 使用DataLoader来包装Dataset对象,并设置批次大小和是否打乱数据
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
```
通过`DataLoader`,我们可以轻松地批量获取数据,并且还能在训练过程中对数据进行洗牌以增加随机性。
### 2.1.2 数据增强中的基本变换技术
在加载数据后,通常会对其执行一系列变换,以增强数据的多样性。PyTorch提供了`transforms`模块,支持各种图像变换操作,虽然它是为图像设计的,但我们也可以借鉴其思想应用到文本数据增强中。
```python
from torchvision import transforms
# 定义一个数据变换流水线
transform_pipeline = transforms.Compose([
transforms.RandomRotation(degrees=(0, 90)), # 随机旋转
transforms.ColorJitter(brightness=0.1, contrast=0.1), # 随机调整亮度和对比度
transforms.RandomGrayscale(p=0.05), # 随机转换为灰度图像
])
# 应用流水线到一个图像数据集
transformed_dataset = CustomDataset([transform_pipeline(item) for item in data_list])
```
`transforms`模块虽然不能直接用于文本数据,但展示了如何组合多个变换操作来增强数据集。
## 2.2 实用的数据增强方法
在文本处理领域,数据增强的策略与图像略有不同,更多的是依赖于文本本身的特性和语言学原理。
### 2.2.1 随机变换
在文本增强中,随机变换可以通过随机替换单词、调整句子结构等方式实现。
```python
import random
def random_swap(sentence, max_swap=3):
words = sentence.split()
for _ in range(random.randint(1, max_swap)):
i, j = random.sample(range(len(words)), 2)
words[i], words[j] = words[j], words[i]
return ' '.join(words)
# 对句子进行随机变换
swapped_sentence = random_swap("This is a simple example.")
```
### 2.2.2 同义词替换
同义词替换是将句子中的单词用它们的同义词替换,这不仅能够增加数据多样性,还能保持句子的语义一致性。
```python
from nltk.corpus import wordnet
import nltk
nltk.download('wordnet')
nltk.download('averaged_perceptron_tagger')
def synonym_swap(sentence, n=2):
tokens = nltk.word_tokenize(sentence)
tagged = nltk.pos_tag(tokens)
synonyms = {}
for word, tag in tagged:
syns = []
for syn in wordnet.synsets(word):
for lemma in syn.lemmas():
syns.append(lemma.name())
synonyms[word] = syns
swapped_sentence = sentence
for _ in range(n):
word = random.choice(list(synonyms.keys()))
synonym = random.choice(synonyms[word])
swapped_sentence = swapped_sentence.replace(word, synonym)
return swapped_sentence
# 对句子进行同义词替换
swapped_sentence = synonym_swap("This is a simple example.")
```
### 2.2.3 长文本截断与序列填充
在处理长文本时,我们可能需要截断超出一定长度的文本或进行序列填充,以适配模型输入。
```python
def truncate_or_pad(text, length=512):
words = text.split()
if len(words) > length:
return ' '.join(words[:length])
else:
return text + ' ' + ' '.join(['<pad>'] * (length - len(words)))
# 处理句子长度
processed_sentence = truncate_or_pad("This is a long text that needs truncat
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从零开始的Ubuntu系统安全加固指南:让系统固若金汤

# 1. Ubuntu系统安全加固概述
在当今的数字化时代,随着网络攻击的日渐频繁和多样化,确保操作系统的安全性变得尤为重要。Ubuntu,作为广泛使用的Linux发行版之一,其安全性自然不容忽视。系统安全加固是防御网络威胁的关键步骤,涉及从基础的权限配置到高级的加密技术的
【C语言性能提升】:掌握函数内联机制,提高程序性能

# 1. 函数内联的概念与重要性
内联函数是优化程序性能的重要技术之一,它在编译阶段将函数调用替换为函数体本身,避免了传统的调用开销。这种技术在许多情况下能够显著提高程序的执行效率,尤其是对于频繁调用的小型函数。然而,内联也是一把双刃剑,不当使用可能会导致目标代码体积的急剧膨胀,从而影响整个程序的性能。
对于IT行业的专业人员来说,理解内联函数的工作原理和应用场景是十
YOLOv8模型调优秘籍:检测精度与速度提升的终极指南

# 1. YOLOv8模型概述
YOLOv8是最新一代的实时目标检测模型,继承并改进了YOLO系列算法的核心优势,旨在提供更准确、更快速的目标检测解决方案。本章将对YOLOv8模型进行基础性介绍,为读者理解后续章节内容打下基础。
## 1.1 YOLOv8的诞生背景
YOLOv8的出现是随着计算机视觉
【VSCode高级技巧】:20分钟掌握编译器插件,打造开发利器

# 1. VSCode插件基础
## 1.1 了解VSCode插件的必要性
Visual Studio Code (VSCode) 是一款流行的源代码编辑器,它通过插件系统极大的扩展了其核心功能。了解如何安装和使用VSCode插件对于提高日常开发的效率至关重要。开发者可以通过插件获得语言特定的支持、工具集成以及个人化的工作流程优化等功能
Linux文件压缩:五种方法助你效率翻倍
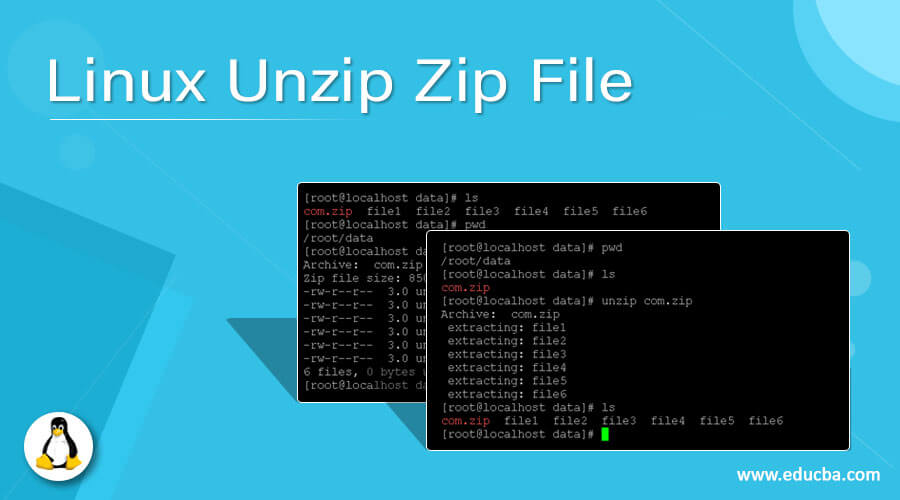
# 1. Linux文件压缩概述
Linux文件压缩是系统管理和数据传输中常见的操作,旨在减少文件或文件集合的大小,以便于存储和网络传输。压缩技术可以提高存储利用率、减少备份时间,并通过优化数据传输效率来降低通信成本。本章节将介绍Linux环境中文件压缩的基本概念,为深入理解后续章节中的技术细节和操作指南打下基础。
# 2. ```
# 第二章:理论基础与压缩工具介绍
## 2.1 压缩技
【PyCharm图像转换与色彩空间】:深入理解背后的科学(4个关键操作)

# 1. PyCharm环境下的图像处理基础
在进行图像处理项目时,一个稳定且功能强大的开发环境是必不可少的。PyCharm作为一款专业的Python IDE,为开发者提供了诸多便利,尤其在图像处理领域,它能够借助丰富的插件和库,简化开发流程并提高开发效率。本章节将重点介绍如何在PyCharm环境中建立图像处理项目的基础,并为后续章节的学习打下坚实的基础。
VSCode快捷键案例解析:日常开发中的快捷操作实例,专家级的实践
# 1. VSCode快捷键的概览与优势
在现代软件开发的快节奏中,提高
YOLOv8训练速度与精度双赢策略:实用技巧大公开

# 1. YOLOv8简介与背景知识
## YOLOv8简介
YOLOv8,作为You Only Look Once系列的最新成员,继承并发扬了YOLO家族在实时目标检测领域的领先地位。YOLOv8引入了多项改进,旨在提高检测精度,同时优化速度以适应不同的应用场景,例如自动驾驶、安防监控、工业检测等。
## YOLO系列模型的发展历程
YOLOv8的出现并不是孤立的,它是在YOLOv1至YOLOv7
【PyCharm中的异常处理】:专家教你如何捕获和分析异常
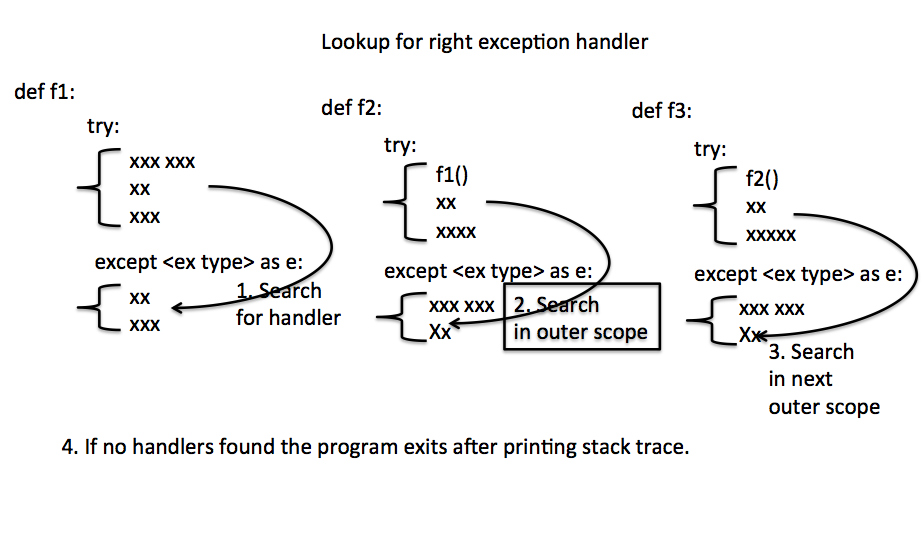
# 1. PyCharm与Python异常处理基础
在编写代码的过程中,异常处理是确保程序鲁棒性的重要部分。本章将介绍在使用PyCharm作为开发IDE时,如何理解和处理Python中的异常。我们将从异常处理的基础知识开始,逐步深入探讨更高级的异常管理技巧及其在日常开发中的应用。通过本章的学习,你将能够更好地理解Python异常处理机制,以及如何利用PyCharm提供的工具来提高开发效率。
在开始之前,让我们首先明确异常
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )