C#处理大型JSON文件的策略:高效数据管理
发布时间: 2024-12-14 01:47:40 阅读量: 3 订阅数: 7 

node18-for windows
参考资源链接:[C#中Json序列化与反序列化的三种方法解析](https://wenku.csdn.net/doc/6v0yh74ypy?spm=1055.2635.3001.10343)
# 1. 大型JSON文件处理概述
处理大型JSON文件时,即便是经验丰富的开发者也会面临一系列的挑战。在这一章中,我们将探讨在大型JSON文件处理中需要考虑的一些核心概念和方法,为后续章节深入技术细节打下基础。
大型JSON文件在存储和传输大量数据时非常有用,例如在构建大数据应用或API服务时。随着数据量的增长,文件的处理、解析和分析变得更加复杂,特别是在内存和性能上可能成为瓶颈。
首先,我们要注意到文件的大小会直接影响处理性能。大型文件可能会消耗大量内存,导致应用运行缓慢甚至崩溃。其次,开发者需要理解数据流式处理的重要性,这是一种有效减少内存占用、提高性能的处理方式。本章将为读者提供关于如何有效处理大型JSON文件的概述和策略,为读者解决后续章节中的具体技术问题提供背景知识。
# 2. C#中的JSON处理基础
## 2.1 JSON数据格式简介
### 2.1.1 JSON的基本结构和语法
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,易于人阅读和编写,同时也易于机器解析和生成。它基于JavaScript的一个子集,但JSON是完全独立于语言的文本格式。JSON的结构可以概括为以下两种基本形式:
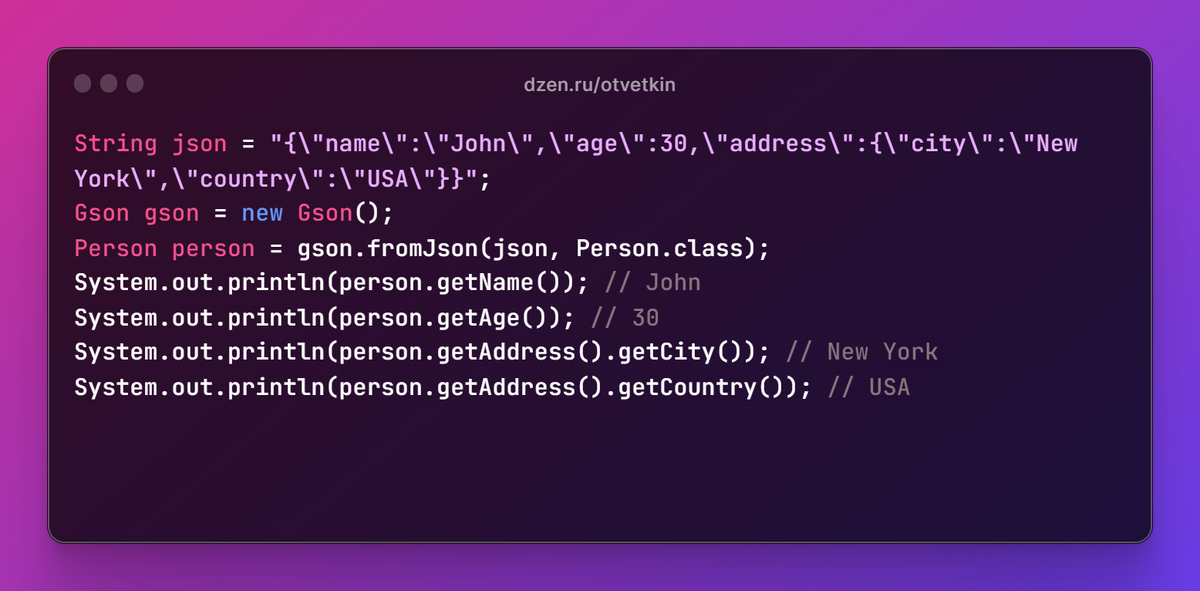
- **对象**:一组有序的键值对,使用大括号`{}`包围。键值对之间用逗号`,`分隔,键和值之间用冒号`:`连接。例如:`{"name": "John", "age": 30}`。
- **数组**:一组有序的值的列表,使用方括号`[]`包围。值之间用逗号`,`分隔。例如:`["apple", "banana", "cherry"]`。
JSON的基本数据类型包括:
- **字符串**:由双引号包围的任意文本,例如`"Hello World"`。
- **数字**:不带引号的数字,例如`12345`或`3.14159`。
- **布尔值**:`true`或`false`。
- **null**:表示空值。
- **对象**和**数组**。
JSON的数据结构和语法对开发者来说是非常直观的,它依靠结构化的方式存储数据,这使得它在数据交换时能够清晰地传达数据结构。
### 2.1.2 JSON与数据交换的关系
JSON是Web服务中常用的数据交换格式之一。相比于XML,它的优势在于简洁性和易于解析。在C#中,JSON广泛用于与前端JavaScript进行数据交互,尤其是在构建RESTful API时,JSON作为数据传输的媒介。在Web前端,JSON对象可以通过`JSON.parse()`方法转换为JavaScript对象;而在C#后端,通过JSON库可以将JSON字符串转换为.NET对象,反之亦然。
JSON格式的普及与跨平台兼容性,使得开发者可以利用它在多种编程语言间进行数据交换,无需担心编码和解码的兼容性问题。无论是Web应用、移动应用还是桌面应用,JSON都扮演着重要的角色。
## 2.2 C#中的JSON序列化与反序列化
### 2.2.1 使用System.Text.Json进行序列化和反序列化
`System.Text.Json`是.NET Core 3.0及以上版本中引入的库,用于处理JSON序列化和反序列化。它旨在提供一个轻量级、高性能的JSON处理库。
序列化是将对象转换为JSON格式的过程,而反序列化是将JSON字符串转换回对象的过程。`System.Text.Json`提供了`JsonSerializer`类用于这两个操作。
**示例代码:**
```csharp
var options = new JsonSerializerOptions { WriteIndented = true };
string jsonString = JsonSerializer.Serialize(myObject, options);
var deserializedObject = JsonSerializer.Deserialize<T>(jsonString);
```
在此代码中:
- `JsonSerializer.Serialize`方法用于序列化一个对象。
- `JsonSerializer.Deserialize`方法用于反序列化一个JSON字符串。
- `JsonSerializerOptions`类可以用来配置序列化的选项,例如`WriteIndented`用于美化输出的JSON字符串。
### 2.2.2 使用Newtonsoft.Json处理复杂场景
`Newtonsoft.Json`(通常称为Json.NET)是一个广泛使用的JSON处理库,提供了一套丰富的API来处理复杂的JSON序列化和反序列化场景。该库支持更复杂的对象图谱和自定义转换器,因此非常适合于处理需要高度定制化的JSON数据。
在使用`Newtonsoft.Json`进行序列化时,我们可以添加各种自定义规则来精确控制序列化过程。
**示例代码:**
```csharp
var settings = new JsonSerializerSettings
{
ContractResolver = new CamelCasePropertyNamesContractResolver(),
Formatting = Newtonsoft.Json.Formatting.Indented
};
string jsonString = JsonConvert.SerializeObject(myObject, settings);
```
在此代码中:
- `JsonSerializerSettings`类用于配置序列化选项,如`ContractResolver`用于指定如何命名属性,`Formatting`用于控制输出格式的可读性。
### 2.2.3 序列化选项和性能考量
在选择使用`System.Text.Json`还是`Newtonsoft.Json`时,性能是一个重要的考量因素。`System.Text.Json`在某些情况下可能会比`Newtonsoft.Json`快,但是`Newtonsoft.Json`提供了更多的定制选项。
开发者应该基于具体的业务场景和性能需求来选择合适的库。例如,如果应用程序需要处理大量的复杂数据模型,并且对序列化的性能要求不是特别严苛,那么`Newtonsoft.Json`可能是更好的选择。如果需要高吞吐量和低延迟的应用场景,`System.Text.Json`可能是更合适的选择。
## 2.3 处理大型JSON文件的挑战
### 2.3.1 文件大小对性能的影响
处理大型JSON文件时,性能是一个重要的考虑因素。大型文件意味着更多的数据需要被加载到内存中进行解析。对于C#程序来说,这意味着可能需要大量的堆内存,这可能会导致内存溢出或垃圾回收延迟。
### 2.3.2 内存限制和数据流式处理
为了有效地处理大型JSON文件,开发者通常会采取流式处理的方法。流式处理意味着数据在读取时逐步解析,而不是一次性加载整个文件到内存中。
在C#中,可以使用流式API来逐步读取和解析JSON文件。这样可以显著减少内存的使用,并且允许开发者以更细粒度的方式处理数据。例如,可以在读取到JSON对象时立即对其进行处理,而无需等待整个文件被解析。
**示例代码:**
```csharp
using (JsonDocument doc = JsonDocument.Parse(jsonString))
{
// 对JSON文档进行逐部分处理
}
```
在此代码中:
- `JsonDocument.Parse`方法用于解析JSON字符串,它允许逐部分读取和处理JSON文档,而不是一次性加载整个文档。
# 3. 高效处理大型JSON文件的策略
## 3.1 分块处理和流式读取
### 3.1.1 实现JSON流式读取的方法
流式读取大型JSON文件是一种有效避免内存溢出的处理方式,它允许程序边读取边处理数据,而不是一次性将整个文件加载到内存中。在C#中,`System.IO.Stream` 类提供了一种抽象,用于表示连续的数据流,它是实现JSON流式读取的基础。
例如,使用`StreamReader`类来逐行读取一个JSON文件,可以有效地将文件的各个部分逐一处理:
```csharp
using System.IO;
using System.Text.Json;
public void ProcessJsonStream(Stream stream)
{
using (StreamReader reader = new StreamReader(stream))
{
string jsonLine;
while ((jsonLine = reader.ReadLine()) != null)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
计算机组成原理:总线系统、虚拟存储与中断机制精讲

参考资源链接:[计算机组成原理课后习题及答案-唐朔飞(完整版).ppt](https://wenku.csdn.net/doc/645f3404543f8444888ac128?spm=1055.2635.3001.10343)
# 1. 计算机组成原理概述
计算机组成原理是理解计算机系统如何运作的基础。本章我们将从最基本的组成部分开始,探索构成现代计算机的核心要素。
## 1.1 计算机系统的层次结构
计算机
鸿蒙 HarmonyOS Linux 镜像定制实战:创建个性化操作系统(镜像定制指南)

参考资源链接:[鸿蒙HarmonyOS Linux系统镜像ISO与VMware使用教程](https://wenku.csdn.net/doc/rz1sdh4vtt?spm=1055.2635.3001.10343)
# 1. 鸿蒙 HarmonyOS Linux 镜像定制概述
在当前的IT行业中,鸿蒙HarmonyOS以其独特的微内核设计、全场景分布式能力和模块化能力,受到广泛关注。其中,Linux镜像定制是深入了解和
【VC++ 6.0在Win10的性能优化秘籍】:效率提升不是梦
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/8/v/dscSt1S7GuYFTJNrIH0g/2017-03-01-limpa-2.png)
参考资源链接:[Win10安装VC++6.0详解:解决兼容性
HiSPi协议性能优化大全:v1.60.00版提升技巧与实战演练

参考资源链接:[HiSPi协议v1.60.00:高速图像传感器接口详解](https://wenku.csdn.net/doc/7yyghxcs6p?spm=1055.2635.3001.10343)
# 1. HiSPi协议基础与应用场景
##
GMS软件操作深度解析:地质三维建模新手入门至专家教程
参考资源链接:[GMS地层三维建模教程:利用钻孔数据创建横截面](https://wenku.csdn.net/doc/6412b783be7fbd1778d4a90d?spm=1055.2635.3001.10343)
# 1. GMS软件操作简介
GMS(Groundwater Modeling System)软件是针对地下水模拟的专业软件,其设计目标是为地质工程师、水文地质专家和环境科学家提供一套集成的地下水模拟工具。本章将简
【Sentaurus 初学者必读】:0基础起步,掌握仿真操作的5大绝招

参考资源链接:[Sentaurus TCAD 培训教程:从入门到实践](https://wenku.csdn.net/doc/4b4qf1so9u?spm=1055.2635.3001.
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )