使用Python进行文档摘要:自动提取关键信息,文本精简艺术
发布时间: 2024-12-07 07:43:59 阅读量: 16 订阅数: 16 

README_hee77_python文字提取_用python提取图片中文字_图片文字提取_

# 1. 文档摘要的重要性与应用场景
## 1.1 文档摘要简介
文档摘要,是指从一篇较长的文档中,自动或手动提取出一段简短且能代表原文主要信息的文本。这种技术在信息爆炸的时代变得尤为重要,它能帮助人们快速获取关键信息,节省阅读时间,提高效率。
## 1.2 文档摘要的应用场景
文档摘要技术广泛应用于新闻媒体、学术研究、企业报告、电子邮件管理等场景。比如,在新闻网站,它可以为读者提供快速阅读摘要,了解新闻要点;在学术研究中,它可以帮助研究人员快速获取大量文献的核心内容;在企业中,它可以对报告进行自动摘要,帮助管理层快速了解情况。
## 1.3 文档摘要的重要性
文档摘要技术不仅提高人们的信息处理效率,还能促进信息的公平获取。对于视觉障碍者,高质量的文本摘要可以帮助他们理解和获取信息。同时,它也是人工智能领域的重要研究课题,涉及到自然语言处理、机器学习等前沿技术。
# 2. Python文本处理基础
## 2.1 Python语言概述
### 2.1.1 Python的基本语法结构
Python以其简洁明了的语法和强大的功能广泛应用于文本处理领域。它的代码可读性强,强调代码的表达力和简洁性,非常适合快速开发和文本处理任务。
一个基本的Python脚本通常包含变量声明、函数定义、控制流语句(如if-else和for循环)、类定义以及模块导入等基本元素。了解并熟悉这些基本语法结构是进行有效Python文本处理的第一步。
下面是一个简单的Python语法结构示例:
```python
# 变量赋值
text = "Hello, World!"
# 函数定义
def greet(name):
return f"Hello, {name}!"
# 控制流语句
for i in range(5):
print(i, " - ", greet(text))
# 类定义
class Greeter:
def __init__(self, greeting):
self.greeting = greeting
def greet(self, name):
return f"{self.greeting} {name}!"
# 模块导入
import math
print(math.sqrt(16)) # 输出: 4.0
```
在上述代码中,我们定义了一个变量`text`,创建了一个`greet`函数用于生成问候语,使用了for循环来打印数字和问候语,定义了一个`Greeter`类,并导入了`math`模块来计算平方根。这些是Python中最基本的语法结构,对于文本处理至关重要。
### 2.1.2 Python的字符串操作
Python对字符串的处理非常强大,提供了多种内建方法来处理字符串,例如:`upper()`, `lower()`, `split()`, `join()`, `strip()`, `replace()`, `find()`, `count()`等。
字符串是文本处理的核心,我们经常需要进行如大小写转换、分割、合并、去除空白字符、替换等操作。
```python
original_text = " Hello World! "
text_without_spaces = original_text.strip() # 移除首尾空格
upper_text = original_text.upper() # 转换为大写
words = original_text.split() # 分割为单词列表
joined_text = " ".join(words) # 重新组合为一个字符串
print(original_text) # 输出原始字符串
print(text_without_spaces) # 输出: Hello World!
print(upper_text) # 输出: HELLO WORLD!
print(words) # 输出: ['Hello', 'World!']
print(joined_text) # 输出: Hello World!
```
在这个例子中,`strip()`方法用于去除字符串两端的空格,`upper()`方法用于将字符串转换成大写形式,`split()`方法将字符串按空格分割成单词列表,而`join()`方法则可以将单词列表合并成一个字符串。
## 2.2 Python中的文本分析库
### 2.2.1 NLTK库简介
自然语言处理工具包(NLTK)是Python中用于文本处理的一个流行库,它提供了丰富的工具和资源来处理文本数据。NLTK支持一系列文本处理任务,包括分词、标注、解析、分类、词干提取、语义推理等。
使用NLTK进行文本分析通常涉及以下步骤:导入NLTK库,下载需要的数据集和模型,然后使用相应的方法进行分析。
```python
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
# 下载NLTK数据包
nltk.download('punkt')
nltk.download('stopwords')
# 示例文本
text = "NLTK is a leading platform for building Python programs to work with human language data."
# 分词
tokens = word_tokenize(text)
# 移除停用词
filtered_tokens = [word for word in tokens if word.lower() not in stopwords.words('english')]
print(tokens) # 输出: ['NLTK', 'is', 'a', 'leading', 'platform', 'for', 'building', 'Python', 'programs', 'to', 'work', 'with', 'human', 'language', 'data', '.']
print(filtered_tokens) # 输出: ['NLTK', 'leading', 'platform', 'building', 'Python', 'programs', 'work', 'human', 'language', 'data', '.']
```
上述代码展示了如何使用NLTK进行文本分词,并移除英文文本中的常见停用词。
### 2.2.2 其他文本处理库(SpaCy, TextBlob等)
除了NLTK之外,还有其他许多文本处理库,例如SpaCy和TextBlob,它们各有特点,为不同的文本处理需求提供了便利。
- **SpaCy** 是一个用于高级自然语言处理的库,它提供了更快的性能和更现代的接口,适合需要处理大规模文本数据和进行复杂文本分析的场景。
- **TextBlob** 提供了一个简单的接口来完成许多常见的文本处理任务。它易于使用,并且非常适合初学者。
SpaCy和TextBlob的引入,使得Python在文本处理领域的应用更加广泛。
```python
import spacy
from textblob import TextBlob
# 加载SpaCy英文模型
nlp = spacy.load('en_core_web_sm')
text = "spaCy is an open-source software library for advanced natural language processing in Python."
doc = nlp(text)
# 使用SpaCy提取名词短语
noun_phrases = [chunk.text for chunk in doc.noun_chunks]
print(noun_phrases) # 输出: ['spaCy', 'software library', 'natural language processing', 'Python']
# 使用TextBlob获取文本的情感极性
blob = TextBlob(text)
polarity = blob.sentiment.polarity
print(polarity) # 输出: 0.2 # 表示正面情感
```
在上面的例子中,我们使用了SpaCy来提取文本中的名词短语,并使用TextBlob分析了文本的情感极性。
## 2.3 Python中正则表达式的运用
### 2.3.1 正则表达式的构造与匹配
正则表达式是一种用于匹配字符串中字符组合的模式。在Python中,`re`模块提供了对正则表达式的支持。正则表达式非常强大,可用于搜索、替换和提取字符串中的特定信息。
正则表达式通常包括普通字符(如字母和数字)和特殊字符(称为"元字符")。例如,`.`匹配除换行符之外的任何单个字符;`*`匹配前面的子表达式零次或多次;`+`匹配前面的子表达式一次或多次;`?`匹配前面的子表达式零次或一次;等等。
```python
import re
text = "Email: example@example.com, Phone: +1-555-1234"
# 构造正则表达式来匹配电子邮件地址
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
matches = re.findall(email_pattern, text)
# 构造正则表达式来匹配电话号码
phone_pattern = r'\+\d{1,3}-\d{3}-\d{4}'
phone_match = re.search(phone_pattern, text)
print(matches) # 输出: ['example@example.com']
print(phone_match.group()) # 输出: +1-555-1234
```
在这段代码中,我们首先使用了正则表达式匹配电子邮件地址,然后匹配电话号码格式。
### 2.3.2 正则表达式在文本提取中的高级应用
在文本提取的高级应用中,正则表达式能够帮助我们提取结构化数据,如日期、时间、特定格式的数字等。正则表达式可以非常灵活地构造,以适应复杂的文本模式匹配需求。
```python
import re
# 示例文本
text = "Meeting scheduled for 2023-04-15 at 10:30 AM in room 101."
# 构造正则表达式提取日期
date_pattern = r'\d{4}-\d{2}-\d{2}'
date_match = re.search(date_pattern, text)
# 构造正则表达式提取时间
time_pattern = r'\d{2}:\d{2} [AP]M'
time_match = re.search(time_pattern, text)
# 构造正则表达式提取会议室号
room_pattern = r'room (\d+)'
room_match = re.search(room_pattern, text)
print(date_match.group()) # 输出: 2023-04-15
print(time_match.group()) # 输出: 10:30 AM
print(room_match.group(1)) # 输出: 101
```
这段代码展示了如何使用正则表达式在文本中提取日期、时间和会议室号。每个正则表达式都被特别设计来匹配相应的文本格式,并成功提取出所需信息。
在本章节中,我们了解了Python在文本处理领域中的基础应用。从基本语法结构到字符串操作,再到文本分析库的介绍,我们奠定了在Python中进行文本处理的基础。接下来,我们将进一步深入探讨文档摘要的理论基础以及使用Python实现文档摘要的实践案例。
# 3. 文档摘要算法介绍
## 3.1 文档摘要的理论基础
### 3.1.1 摘要的类型与目的
文档摘要是一种将长篇文本信息压缩成简短概述的技术,其目的是为了让读者快速获得文档的核心信息和主题。摘要有两种主要类型:抽取式摘要和生成式摘要。
- **抽取式摘要**(Extractive Summary):通过分析原文中的重要句子或短语,并将它们直接抽取出来构成摘要。其核心在于确定哪些部分对于传达文档的主旨最为重要。此类方法倾向于保留原文的原话或近似表达,易于保持信息的准确性,但可能缺乏流畅性和连贯性。
- **生成式摘要**(Generative Summary):通过学习文档内容,生成全新的句子来表述文档的核心信息。这种摘要方式更加注重语句的连贯性和自然性,能够提供更加简洁、流畅的摘要内容。但是,生成式摘要面临更大的挑战,因为它需要生成不直接来自原文的文本,对模型的语义理解能力有较高的要求。
### 3.1.2 摘要算法的分类(抽取式和生成式)
摘要算法主要分为两大类:抽取式算法和生成式算法。这两种方法各有优势和局限性,不同的应用场景下,选择合适的摘要技术至关重要。
抽取式算法适合于内容结构化和目标文本较短的场景,如新闻文章或技术报告。其优势在于实现简单、效率高、易于理解和控制,但可能缺乏创造力和连贯性。生成式摘要算法在处理长篇、结构复杂的文档时表现更佳,它可以捕捉更多的语义信息,并生成连贯的叙述性文本,但其计算成本较高,模型训练需要更多的数据和计算资源。
在选择摘要技术时,需要考虑文档的长度、复杂性、预期摘要的长度、信息保留的完整性以及用户的使用场景。下面详细探讨抽取式和生成式摘要的具体实现方法和技术细节。
## 3.2 抽取式摘要方法
### 3.2.1 基于TF-IDF的摘要方法
基于TF-IDF(Term Frequency-Inverse Document Frequency)的抽取式摘要方法是最早期也是较为简单的文本摘要技术之一。该方法的核心在于衡量词项的重要程度。
**算法步骤如下:**
1. **词频(TF)的计算**:统计文本中每个词项的出现频率。
2. **逆文档频率(IDF)的计算**:计算每个词项在整个文档集合中的罕见程度。
3. **权重的计算**:将TF和IDF结合起来,为每个词项计算一个权重。
4. **句子的评分**:根据句子中包含的词项权重,计算句子的重要性分数。
5. **句子的选择**:选择得分最高的N个句子构成文档的摘要。
**代码实现示例:**
```python
from sklearn.feature_extraction.text import TfidfVectorizer
from collections import defaultdict
import nu
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 在自然语言处理 (NLP) 领域的广泛应用。从社交媒体情感分析到主题建模、自然语言生成、机器翻译、知识图谱构建、语音识别和文本聚类,该专栏提供了深入的教程和实践指南,帮助读者掌握 NLP 的关键技术。专栏还涵盖了大规模文本处理技术,包括文本清洗和预处理,以确保数据质量和效率。通过这些文章,读者将了解 Python 在 NLP 中的强大功能,并获得在现实世界项目中应用这些技术的实际技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
精通VW 80808-2 OCR错误诊断:快速解决问题的7种方法

参考资源链接:[Volkswagen标准VW 80808-2(OCR)2017:电子元件与装配技术详细指南](https://wenku.csdn.net/doc/3y3gykjr27?spm=1055.2635.3001.10343)
# 1. VW 80808-2 OCR错误诊断概述
在数字化时代,光学字符识别(
LIFBASE性能调优秘笈:9个步骤提升系统响应速度
参考资源链接:[LIFBASE帮助文件](https://wenku.csdn.net/doc/646da1b5543f844488d79f20?spm=1055.2635.3001.10343)
# 1. LIFBASE系统性能调优概述
在IT领域,随着技术的发展和业务需求的增长,系统性能调优逐渐成为保障业务连续性和用户满意度的关键环节。LIFBASE系统作为
【XILINX 7代XADC进阶手册】:深度剖析数据采集系统设计的7个关键点

参考资源链接:[Xilinx 7系列FPGA XADC模块详解与应用](https://wenku.csdn.net/doc/6412
OV426功耗管理指南:打造绿色计算的终极武器
参考资源链接:[OV426传感器详解:医疗影像前端解决方案](https://wenku.csdn.net/doc/61pvjv8si4?spm=1055.2635.3001.10343)
# 1. OV426功耗管理概述
在当今数字化时代,信息技术设备的普及导致了能源消耗的剧增。随着对节能减排的全球性重视,如何有效地管理电子设备的功耗成为了IT行业关注的焦点之一。特别是对于高性能计算设备和嵌入式系统,合理的功耗管理不仅能够降低能源消耗,还能延长设备的使用寿命,提高系统的稳定性和响应速度。OV426作为一款先进的处理器,其功耗管理能力直接影响到整个系统的性能与效率。接下来的章节中,我们将深入
深入探讨:银行储蓄系统中的交易并发控制
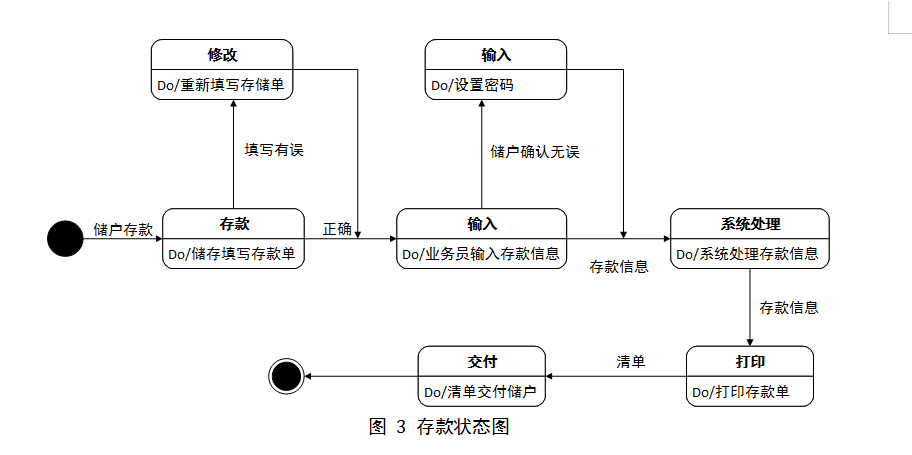
参考资源链接:[银行储蓄系统设计与实现:高效精准的银行业务管理](https://wenku.csdn.net/doc/75uujt5r53?spm=1055.2635.3001.10343)
# 1. 银行储蓄系统的并发问题概述
## 1.1 并发访问的必要性
在现代银行业务中,储蓄系统的并发处理是提高交易效率和用户体验的关键。随着在线交易量的增加,系统需要同时处理来自不同客户和分支机构的请求。并发访问确保了系统能够快速响应,但同时也带来了数
【HyperMesh材料属性至边界条件】:打造精准仿真模型的全路径指南

参考资源链接:[Hypermesh基础操作指南:重力与外力加载](https://wenku.csdn.net/doc/mm2ex8rjsv?spm=105
【热管理高手进阶】:Android平台下高通与MTK热功耗深入分析及优化
参考资源链接:[Android高通与MTK平台热管理详解:定制Thermal与架构解析](https://wenku.csdn.net/doc/6412b72dbe7fbd1778d495e3?spm=1055.2635.3001.10343)
# 1. Android热管理基础与挑战
在当今的移动设备领域,Andr
【DS-K1T673误识率克星】:揭秘误差分析及改善策略

参考资源链接:[海康威视DS-K1T673系列人脸识别终端用户指南](https://wenku.csdn.net/doc/5swruw1zpd?spm=1055.2635.3001.10343)
# 1. 误差分析与改善策略的重要性
## 1.1 误差在IT领域的普遍性
在IT行业,数据和系统准确性至关重要。误差,无论是人为的还是技术上的,都可能导致重大的问题,如系统故障、数据失真和决策
【PADS Layout专家速成】:7步掌握覆铜技术,优化电路板设计
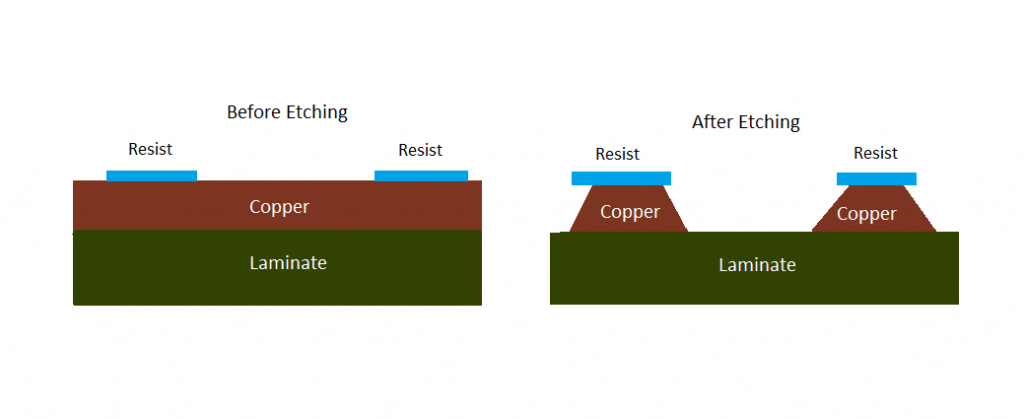
参考资源链接:[PADS LAYOUT 覆铜操作详解:从边框到填充](https://wenku.csdn.net/doc/69kdntug90?spm=1055.2635.3001.10343)
# 1. 覆铜技术概述
在现代电子设计制造中,覆铜技术是构建电路板核心的一环,它不仅涉及基础的电气连接,还包括了信号完整性、热管理以及结构稳定性等多方面考量
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )