【Python编程实战】:构建无内存泄漏应用的7个关键步骤
发布时间: 2024-09-29 18:24:52 阅读量: 33 订阅数: 17 

# 1. 内存泄漏的概念和影响
## 1.1 内存泄漏定义
内存泄漏是指程序在分配和使用内存过程中,未能正确释放不再需要的内存,导致可用内存逐渐减少的现象。这种问题常在程序运行时间长、内存需求量大的应用中发生,对性能产生负面影响。
## 1.2 内存泄漏的影响
内存泄漏对系统性能有着直接的负面影响,包括程序响应变慢、系统可用内存减少、甚至可能导致程序崩溃。对于长期运行的服务,这种问题会不断累积,严重影响系统的稳定性。
## 1.3 识别内存泄漏
通过监控系统的内存使用情况,观察到内存消耗呈上升趋势且无法正常释放,这通常是内存泄漏的表现。在应用层面上,可通过内存分析工具发现泄漏点,确定泄漏原因,从而实施解决方案。
```python
# 示例代码:一段可能引起内存泄漏的Python代码
import weakref
class Node:
def __init__(self, value):
self.value = value
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def append(self, value):
new_node = Node(value)
if not self.head:
self.head = new_node
else:
current = self.head
while current.next:
current = current.next
current.next = new_node
ll = LinkedList()
for i in range(10000):
ll.append(i)
# 这里并没有释放LinkedList的引用,导致内存泄漏
```
以上代码段中,没有显示地释放LinkedList实例,可能会导致内存泄漏,因为即便退出了该代码块的上下文,LinkedList仍然在全局变量作用域中保持活跃状态。
# 2. Python内存管理机制
## 2.1 Python中的内存分配
### 2.1.1 对象的创建和存储
Python是一种高级编程语言,它为我们提供了抽象的数据类型。当在Python中创建一个对象时,解释器负责为该对象分配内存。对象的内存分配过程涉及以下几个关键步骤:
1. **对象类型确定**:Python解释器会根据对象的类型(如整数、浮点数、字符串等)来确定需要分配多少内存。
2. **内存空间分配**:Python具有自己的内存管理器,该管理器会负责查找足够大的内存块以容纳新对象。
3. **对象初始化**:内存分配后,对象会被初始化。例如,对于整数,其值会被设置为0;对于字符串,则初始化为空字符串。
Python中,每个对象都有一个与之关联的内存大小,它可以通过内置的`sys.getsizeof()`函数进行查询。例如:
```python
import sys
# 创建一个整数对象
i = 10
# 获取对象的大小(不包括对象容器自身的开销)
print(sys.getsizeof(i))
```
### 2.1.2 引用计数与垃圾回收
Python使用引用计数机制来跟踪和管理内存。每个对象都会记录有多少引用指向它,当引用计数降到零时,意味着没有任何引用指向该对象,对象就可以被垃圾回收器回收。
引用计数的工作原理如下:
- 当创建一个对象时,它的引用计数初始化为1。
- 当一个引用指向该对象时,它的引用计数增加。
- 当一个引用离开其作用域或被显式删除时,它的引用计数减少。
- 如果对象的引用计数变为0,内存会被回收。
Python还拥有循环垃圾收集器以处理循环引用的情况。循环垃圾收集器使用一种称为"标记-清除"和"分代收集"的技术来检测和解决循环引用问题。这意味着即使存在循环引用,只要它们是不可达的,Python解释器最终也能回收它们所占用的内存。
### 2.2 内存泄漏的常见原因
内存泄漏在Python中虽然不像在C或C++中那样常见,但如果不注意,还是有可能出现内存泄漏问题。
#### 2.2.1 全局变量和闭包陷阱
使用全局变量时,因为全局变量存在于整个程序的生命周期中,如果无意中修改了全局变量,可能会导致不需要的对象保持在内存中。闭包中的未绑定的局部变量同样会保持引用到外部作用域中的对象。
```python
# 全局变量导致内存泄漏
global_var = [1, 2, 3]
def foo():
return global_var
# 闭包中的未绑定局部变量
def make_multiplier(x):
def multiplier(n):
return n * x
return multiplier
multiplier = make_multiplier(2)
```
#### 2.2.2 循环引用和类实例属性
当两个或多个对象相互引用时,如果没有其他外部引用指向这些对象,就会产生循环引用。在类的实例中,如果实例属性包含实例本身或其他实例的引用,也会形成循环引用。
```python
class A:
def __init__(self):
self.b = B()
class B:
def __init__(self):
self.a = A()
a = A()
```
在这个例子中,A的实例和B的实例相互引用,形成一个循环,它们的引用计数始终大于零,导致内存泄漏。
### 2.3 内存泄漏诊断工具
#### 2.3.1 使用对象浏览器
Python提供了一些工具来帮助开发者诊断内存泄漏,例如`objgraph`模块可以用来可视化对象之间的引用关系,从而帮助识别潜在的内存泄漏。
```python
import objgraph
# 示例代码,对象间引用关系可视化
a = [1, 2, 3]
b = {'x': a, 'y': [4, 5]}
objgraph.show_backrefs([a], filename='backrefs_a.png', max_depth=2)
```
#### 2.3.2 分析内存使用模式
`memory_profiler`模块允许我们监控程序运行期间的内存使用情况。它可以帮助我们观察到内存使用情况的变化趋势,从而识别出内存使用异常的部分。
```python
# 示例代码,使用memory_profiler来监控内存使用情况
from memory_profiler import memory_usage
# 运行某个函数并监控其内存使用情况
def sample_function():
# 这里填入需要测试的代码片段
pass
mem_usage = memory_usage((sample_function, ()))
print(mem_usage)
```
### 总结
在本章中,我们介绍了Python中的内存管理机制,包括对象的创建和存储、引用计数以及垃圾回收。同时,我们也探讨了内存泄漏的常见原因,例如全局变量的不当使用、循环引用问题以及类实例属性的循环引用。此外,我们还了解了如何使用`objgraph`和`memory_profiler`等工具来诊断内存泄漏问题。
本章节的知识点不仅帮助我们深入理解了Python内存管理机制,而且为我们提供了实用的工具和方法来诊断和解决内存泄漏问题。掌握这些知识对于开发高性能和高稳定性的Python应用至关重要。
# 3. 识别和预防内存泄漏
## 代码审查与分析
### 编写可读性强的代码
在编写代码的过程中,良好的编程习惯可以减少内存泄漏的风险。可读性强的代码易于理解和维护,这直接关联到内存泄漏的预防。当代码足够清晰,每个函数和变量的作用都明确无误时,开发者更容易注意到哪些代码可能会导致内存泄露。
例如,命名函数和变量时应反映出其功能和作用域,这样能够快速理解其在程序中的生命周期,从而识别出潜在的循环引用和无用对象。此外,注释的添加也是不可缺少的,尤其是对于那些复杂或者难以理解的代码块。
```python
# 示例:良好的命名习惯和代码注释
def calculate_discount(prices, discount_rate):
"""
计算打折后的价格列表
:param prices: 原始价格列表
:param discount_rate: 打折比例,例如 0.9 表示打九折
:return: 打折后的价格列表
"""
return [price * discount_rate for price in prices]
# 使用可读性强的变量名和明确的函数注释
```
### 静态代码分析工具
静态代码分析工具可以自动化地对代码进行检

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Java热部署神器:Javassist在热部署中的应用与原理
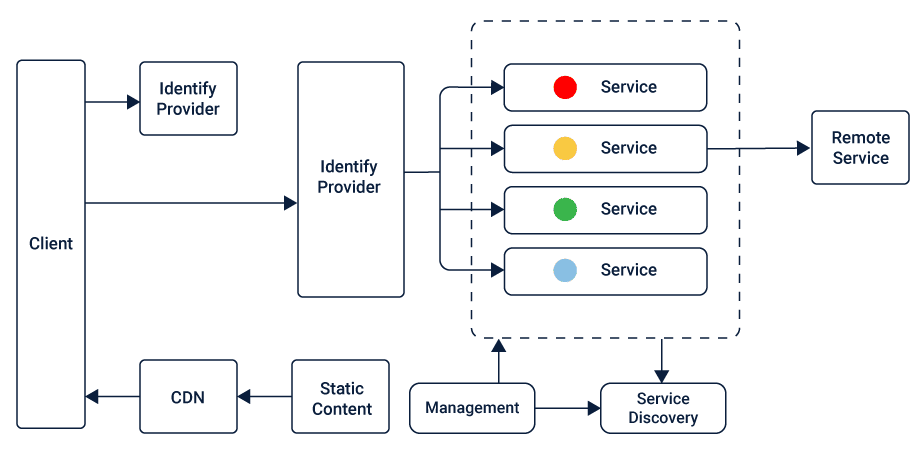
# 1. Javassist概述
在Java开发中,动态修改字节码是高级编程技巧之一,也是许多框架和库的基础技术,比如Spring的AOP、Hibernate的ORM等。Javassist是一个开源的Java字节码操作框架,其最大的特点是能够直接编辑Java的字节码文件,实现动态修改类的结构和行为。与Java反射机制相比,Javassist在操作
【大数据处理】:UserDict在内存高效管理中的角色

# 1. 大数据处理与内存管理基础
## 1.1 大数据处理的重要性
随着技术的快速发展,企业产生了海量的数据,而大数据处理成为了IT行业的核心任务。高效的数据处理不仅能帮助企业做出快速决策,还能在激烈的市场竞争中保持优势地位。在大数据的处理过程中,内存管理是关键因素之一,它直接影响着数据处理的速度和效率。
## 1.
邮件功能测试策略:django.core.mail的单元测试与集成测试指南
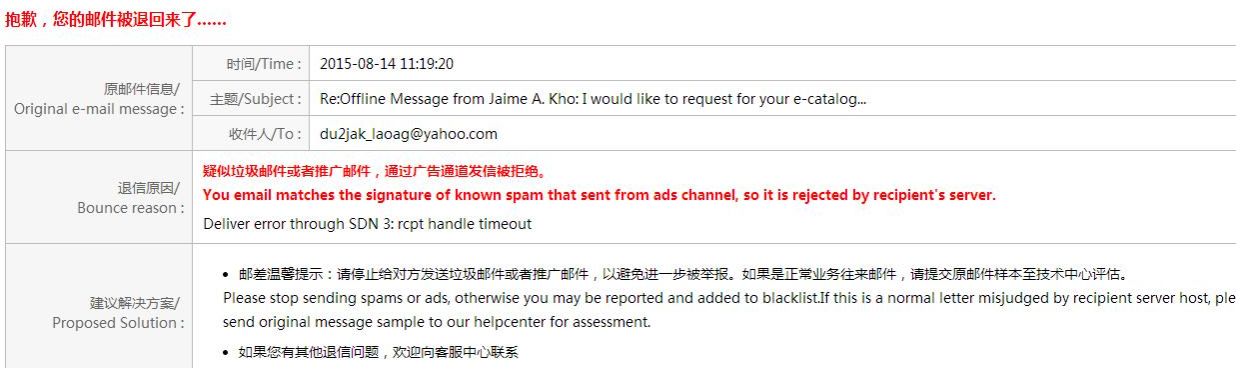
# 1. 邮件功能测试的基础概念
在当今数字化工作环境中,邮件功能测试是确保通信系统稳定性和可靠性的关键步骤。邮件功能测试通常涉及多个方面,从基本的发送和接收,到邮件内容解析、附件处理、垃圾邮件识别等高级功能。本章节将深入探讨邮件功能测试的基础概念,为后续章节中更高级的测试技巧和优化策略打下坚实的基础。
## 1.1 邮件功能测试的目标与意义
邮件功能测
字节码库提升缓存效率:应用缓存策略的秘密武器
# 1. 缓存策略的理论基础
缓存策略是提高系统性能的关键技术之一。在IT行业中,几乎所有的高性能系统都依赖于有效的缓存策略来减少延迟,提高吞吐量。缓存策略可以简单分为两大类:预取策略和替换策略。
## 1.1 缓存预取策略
预取策略关注于预测接下来最可能被访问的数据,并提前加载到缓存中。这种方法的有效性依赖于准确的预测算法。常见的预取策略包括顺序预取、时间相关预取和依赖性预取。它们各有优劣,适用不同的场景和需求。
## 1.2 缓存替换策略
替换策略则决定了当缓存满了之后,哪些数据应该被保留,哪些应该被替换出去。常见的替换策略包括最近最少使用(LRU),最不经常使用(LFU),以及先进
大数据分析实战案例:Dask在数据处理中的应用深度解析
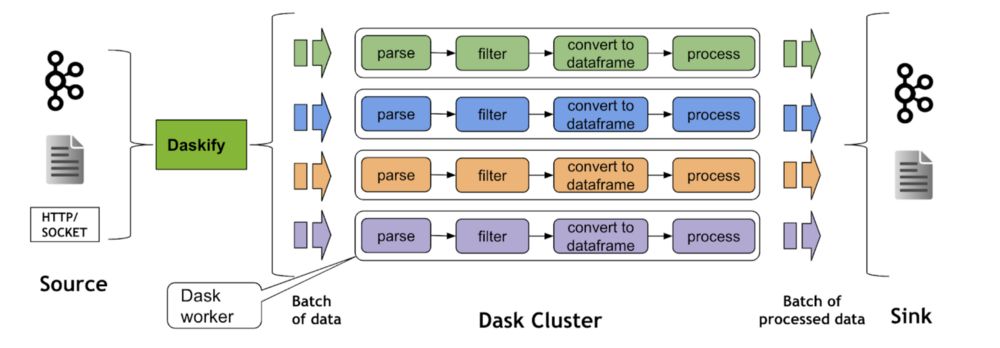
# 1. Dask基础知识介绍
Dask 是一个用于并行计算的 Python 库,特别适合处理大规模数据集和进行复杂的数据分析。它与 NumPy 和 Pandas 等数据处理库紧密集成,从而扩展了这些库的功能,使其能够处理超过单机内存限制的数据。Dask 采用延迟执行(lazy evaluation)策略,只有在明确需要结果时,才会进行计算,这使得它在资
【Python Unicode数学和货币符号处理】:unicodedata库,特殊字符集的处理专家

# 1. Python中Unicode的基础知识
Unicode是一个为世界上每一个字符分配一个唯一代码的标准,它被设计来覆盖世界上所有语言的文字系统。在Python中,Unicode支持是作为内建功能提供的,这一点对于处理国际化文本、网络编程和数据存储尤为重要。
## Unicode的历史和设计哲学
Unicode的历史始于1988年,起初是为了简化字
【Pandas在金融数据分析中的应用】:挖掘隐藏数据价值的秘密武器

# 1. Pandas基础与金融数据处理
在金融行业中,数据处理是日常工作的核心。利用Python强大的数据分析库Pandas,可以有效地处理和分析金融数据。本章将带你入门Pandas库的基本使用,并介绍如何将Pandas应用到金融数据处理中。
## 1.1 安装和导入Pandas库
首先,确保你的Python环境中已经安装了Pandas库。如果你还没有安装,
【SteamOS游戏兼容性指南】:确保游戏运行无忧的关键测试方法

# 1. SteamOS游戏兼容性基础
## 1.1 什么是SteamOS
SteamOS是由Valve公司基于Debian开发的一个专门为游戏而优化的操作系统。它是Linux的一个变种,专为大屏幕和游戏手柄设计,旨在为玩家提供一个无缝的游戏体验。由于Linux系统的开放性和开源性,SteamOS为游戏开发者提供了一个理想的平台,可以更直接地控制游戏运行环境,从而可能获得更好的性能和稳定性。
## 1.2 SteamOS与传统操作
【时间管理新境界】:如何运用Obsidian规划你的生活

# 1. 时间管理与生产力提升
在当今快节奏的IT行业中,有效的时间管理和生产力提升是专业人员成功的关键。本章旨在为读者提供深入理解和实践时间管理技巧,以及如何利用这些技巧来增强个人的生产力。
## 1.1 时间管理的重要性
时间管理是自我管理的重要组成部分。有效的规划和管理时间,不仅可以帮助你完成更多的工作,还能提升工作质量,减少压
ODE求解器深度解析:Scipy中的常微分方程求解器技巧
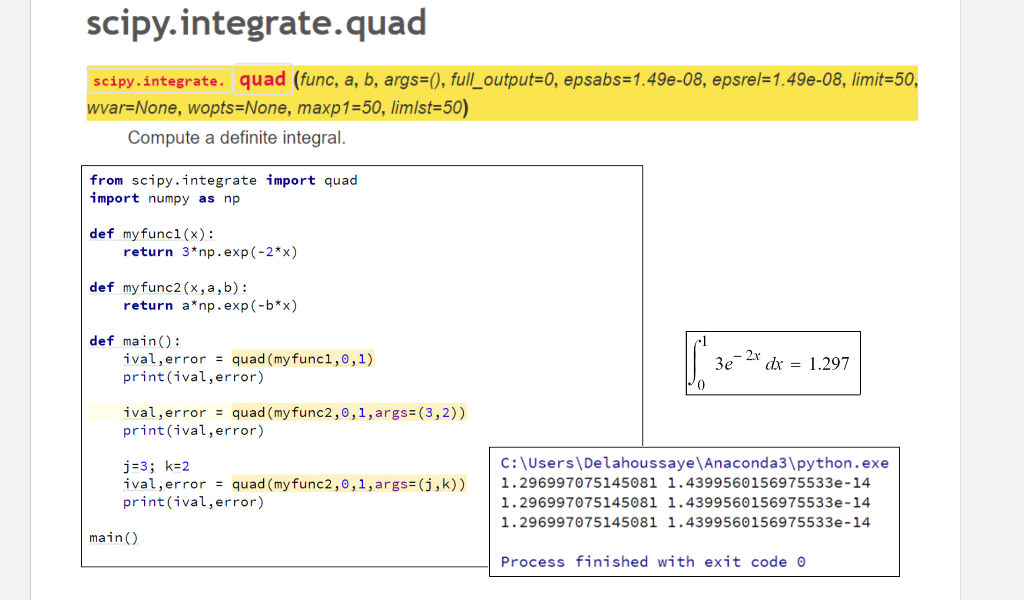
# 1. 常微分方程(ODE)基础与求解概述
微分方程是数学和物理学中的基础工具,它描述了自然界中的动态变化过程。常微分方程(ODE)作为其中的一类,专门处理只涉及一个独立变量(通常是时间)的函数及其导数之间的关系。通过求解ODE,我们可以预测各种系统随时间的演化,例如人口增长模型、化学反应速率、天体运动等。
## 1.1 数学表示与分类
常微分方程通常写作如下形式:
\[ \fr
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )