Python数据清洗指南:打造社交媒体分析的完美准备
发布时间: 2024-12-06 22:13:20 阅读量: 14 订阅数: 12 

数据分析实战指南:技巧、案例、代码与工具深度剖析.pdf
# 1. 数据清洗在社交媒体分析中的重要性
随着社交媒体平台的兴起,大量的用户数据生成,这些数据蕴含着丰富的信息,但同时也充满了噪音和不一致性。数据清洗,作为数据预处理的关键步骤,对于提高社交媒体分析的准确性和有效性至关重要。在这一章节中,我们将探讨数据清洗对社交媒体分析的重要性,了解它是如何帮助我们提升数据质量,从而得出更有价值的见解和结论的。
## 1.1 数据清洗的作用和目的
在社交媒体分析的背景下,数据清洗的主要作用是消除无关数据、纠正错误、填补缺失值、标准化数据格式,以及识别并处理异常值。通过这些操作,数据清洗确保了分析结果的可信度,减少了误导性结论的风险,为后续的数据挖掘和机器学习算法提供了更加可靠的输入。
## 1.2 挑战与机遇
社交媒体数据清洗面临着一些挑战,如文本数据的非结构化、用户行为的多变性、以及数据量的庞大等。然而,通过采用正确的策略和工具,我们可以将这些挑战转化为机遇,从而获得更深层次的用户洞察,增强社交媒体策略的有效性。
在第二章节中,我们将详细探讨Python在数据清洗中的作用,包括基础的数据类型操作和处理库的使用。这将为读者在社交媒体数据清洗中应用Python提供坚实的基础。
# 2. Python数据清洗基础
### 2.1 Python数据类型和结构
#### 2.1.1 理解Python中的数据类型
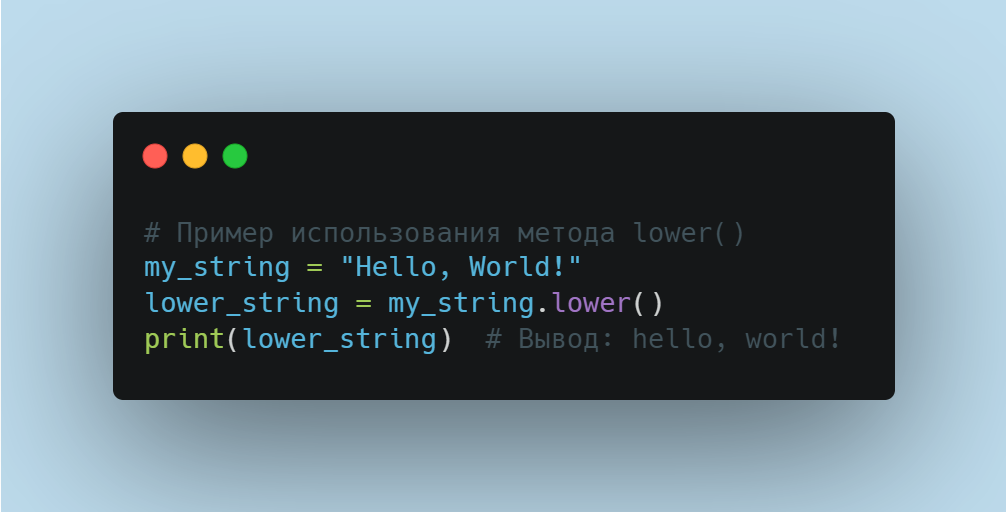
Python作为一门高级编程语言,其内置的数据类型是进行数据处理和清洗的基础。基本数据类型包括了整数(int)、浮点数(float)、字符串(str)、布尔值(bool)和NoneType。这些数据类型在数据清洗中有着不同的应用场景:
- **整数和浮点数** 通常用于表示数值数据,它们在进行数学运算时非常直接。
- **字符串** 用于文本数据,需要进行诸如分割、替换等操作。
- **布尔值** 表示True或False,常用于条件判断。
- **NoneType** 是一个特殊的类型,仅有一个值None,表示无值。
理解这些基础数据类型有助于选择适当的操作来清洗和处理数据。
#### 2.1.2 探索Python的集合类型:列表、元组、字典、集合
Python中的集合类型为数据提供了组织结构,它们分别是列表(list)、元组(tuple)、字典(dict)和集合(set)。这些集合类型在数据清洗时各有妙用:
- **列表** 是一个有序集合,可以随时添加和删除其中的元素。
- **元组** 也是一个有序集合,但不可变,适合用于存储固定的数据。
- **字典** 是一种无序集合,通过键-值对存储数据,非常适合表示关系数据。
- **集合** 是无序且元素唯一的集合,可用于去重和进行集合运算。
下面通过代码示例来展示这些数据结构的应用:
```python
# 列表示例
fruits_list = ["apple", "banana", "cherry"]
# 元组示例
coordinates_tuple = (10.0, 20.0)
# 字典示例
person_dict = {"name": "Alice", "age": 25, "city": "New York"}
# 集合示例
unique_numbers = set([1, 2, 3, 4, 5])
```
### 2.2 Python中的数据操作
#### 2.2.1 数据选择和访问技术
在数据清洗中,我们经常需要访问数据集中的特定元素或元素集合。这可以通过索引和切片来完成:
- **索引** 通过指定位置来访问元素,Python支持负索引从列表或字符串的末尾开始。
- **切片** 通过指定开始、结束和步长来获取元素的子集。
```python
# 通过索引访问字符串中的字符
first_char = fruits_list[0]
# 通过切片获取列表中的子集
subset_fruits = fruits_list[1:3]
```
#### 2.2.2 数据切片和索引的应用
切片和索引技术在数据清洗过程中非常有用,例如,删除列表中的一个元素,或者提取字符串中的一个特定部分。下面的代码展示了如何使用切片和索引来操作数据:
```python
# 删除列表中的第二个元素
del fruits_list[1]
# 提取字符串中的第二个到倒数第二个字符
substring = fruits_list[0][1:-1]
```
#### 2.2.3 常用的数据操作函数和方法
Python提供了丰富的内置函数和方法来操作数据。例如,`len()` 函数可以返回列表的长度,`sorted()` 函数可以对列表进行排序等。
```python
# 获取列表长度
fruits_list_length = len(fruits_list)
# 对列表进行排序
sorted_fruits = sorted(fruits_list)
```
### 2.3 Python的数据处理库
#### 2.3.1 NumPy库的介绍和应用
NumPy是一个用于科学计算的Python库,它提供了一个强大的N维数组对象和众多操作这些数组的函数。在数据清洗中,NumPy可以快速处理大规模数值数据。
```python
import numpy as np
# 创建NumPy数组
fruits_array = np.array(fruits_list)
# 对数组进行排序
sorted_array = np.sort(fruits_array)
```
#### 2.3.2 Pandas库的介绍和应用
Pandas是另一个强大的数据处理库,它提供了DataFrame和Series对象,非常适合处理表格数据。Pandas内置了各种数据清洗功能,例如缺失值填充、数据过滤等。
```python
import pandas as pd
# 创建DataFrame
fruits_df = pd.DataFrame(fruits_list, columns=['Fruit'])
# 删除包含空值的行
fruits_df_cleaned = fruits_df.dropna()
```
以上章节详细介绍了Python在数据清洗方面的基础知识点,为后续的高级数据清洗技术打下了扎实的基础。通过理解Python的数据类型和结构,掌握数据操作技术,以及学会运用NumPy和Pandas数据处理库,可以有效地进行初步的数据清洗工作。在下一章节中,我们将探索数据清洗的高级技术。
# 3. 数据清洗的高级技术
在数据科学的实践中,数据清洗是确保数据质量和准确性的关键步骤。随着数据复杂性的增加,仅仅使用基本的数据清洗技术已经不足以应对挑战。本章节将探讨数据清洗的高级技术,包括处理缺失数据、异常值检测与处理,以及数据规范化和标准化的方法。
## 3.1 缺失数据的处理
### 3.1.1 检测和识别缺失数据
在处理缺失数据之前,

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 在社交媒体分析中的强大应用。从数据采集、文本分析到情感分析和网络爬虫,专栏提供了全面的指南,帮助数据分析师充分利用社交媒体数据。文章还涵盖了趋势预测、数据可视化、图论和机器学习等高级技术,使读者能够从社交媒体中提取有价值的见解。此外,专栏还介绍了脚本自动化、NLP 和群体行为分析等实用技巧,帮助分析师提高效率并深入了解社交媒体动态。通过提供这些技巧和见解,本专栏旨在帮助读者成为社交媒体分析领域的专家,并利用 Python 的强大功能做出明智的决策。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【从零开始】:Rufus安装教程及环境准备
参考资源链接:[Rufus-3.8:快速制作U盘安装Windows Server 2019教程](https://wenku.csdn.net/doc/20fp4o7omz?spm=1055.2635.3001.10343)
# 1. Rufus简介与应用背景
## 1.1 Rufus的定义
Rufus是一个免费的开源软件,它主要的作用是帮助用户快速地制作启动盘,尤其
【PLC通信高级技巧】:FX3U MODBUS性能优化与故障解决
参考资源链接:[FX3S·FX3G·FX3GC·FX3U·FX3UC 用户手册 MODBUS通信篇.pdf](https://wenku.csdn.net/doc/646186fa543f844488933e8f?spm=1055.2635.3001.10343)
# 1. MODBUS协议概述及其在
【IPD产品开发流程速成课】:12个关键角色的职责全解析与实用指南
参考资源链接:[IPD产品开发流程中各角色及其关键职责解析](https://wenku.csdn.net/doc/4pdguiu8sh?spm=1055.2635.3001.10343)
# 1. IPD产品开发流程概述
## IPD产品开发流程简介
集成产品开发(Integrated Product Development,IPD)是一种将产品开发过程中的各环节整合起
MAX96722内部机制揭秘
参考资源链接:[MAX96722:高速GMSL接口转换器开发指南](https://wenku.csdn.net/doc/84z480zzrt?spm=1055.2635.3001.10343)
# 1. MAX96722产品概述
## 简介
MAX96722是Maxim公司推出的一款高性能数据采集与传输设备,以其卓越的图像处理能力、稳定的通信接
Patran Sec05视图与PCL脚本:自动化流程,效率提升新境界
参考资源链接:[Patran第5部分:视图和显示操作指南](https://wenku.csdn.net/doc/35es7kxnb2?spm=1055.2635.3001.10343)
# 1. Patran和PCL脚本概述
在当今高度自动化的工程设计领域,Patra
PMP项目质量管理:交付卓越项目的策略与工具

参考资源链接:[PMP项目管理培训课件PPT版(完整版).ppt](https://wenku.csdn.net/doc/6401acebcce7214c316ed9f8?spm=1055.2635.3001.10343)
# 1. 项目质量管理概述
项目质量管理是确保项目产出满足预定需求的关键过程。它涉及到一系列的计划、监控和改进活动,其目的是确保项目团队以最小的资源投入,达到尽可能高的产品和服务质量。
Kingbase性能升级秘籍:案例分析与调优技巧精讲
参考资源链接:[人大金仓 JDBC 连接驱动KingbaseV8 JDBC Jar包下载](https://wenku.csdn.net/doc/6ekiwsdst
【运算放大器反馈:正负反馈的实战分析】:提升性能的秘诀

参考资源链接:[三级运放架构解析:SMC、SMCNR与NMC的极零点补偿策略](https://wenku.csdn.net/doc/1c6bnjtops?spm=1055.2635.3001.10343)
# 1. 运算放大器基础知识回顾
在深入了解运算放大器的正反馈与负反馈理论之前,我们需要先回顾一下运算放大器(Op-Amp)的基础知识。运算放大器是一种高增益的直流耦合放大器,它能够执行多种信号
铁路电报码的国际舞台:全球铁路通信标准的对比分析

参考资源链接:[中国铁路电报码完整列表](https://wenku.csdn.net/doc/1ep2j13327?spm=1055.2635.3001.10343)
# 1. 铁路电报码的起源与历史演进
## 1.1 早期的铁路通信技术
在铁路的早期,为了避免碰撞和提高运输效率,铁路公司开始寻找一种可靠且有效的沟通方式。1830年,第一条商业铁路——利物浦
DX12的跨平台策略:一文掌握DX12在不同平台的成功秘诀

参考资源链接:[龙书DX12版:入门指南与差异化阅读策略](https://wenku.csdn.net/doc/64643a7d5928463033c1d601?spm=1055.2635.3001.10343)
# 1. DirectX 12跨平台概述
DirectX 12作为微软推出的图形API,自从2015年首次发布以来,已经成为了游戏开发者和硬
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )