【MySQL性能优化秘籍】:从业务角度透视数据库优化实践
发布时间: 2024-12-07 09:37:45 阅读量: 13 订阅数: 12 

MySQL性能优化秘籍:EXPLAIN深度解析与应用实战
# 1. MySQL性能优化概述
## 为什么性能优化是必要的
数据库系统作为信息管理的核心组件,其性能直接关系到整个应用程序的响应速度和处理能力。性能优化不仅是为了提高用户体验和业务效率,更是在资源有限的条件下,挖掘系统潜力,确保业务的可持续发展。
## 性能优化的目标与原则
性能优化的目标通常是对速度、稳定性、可靠性和可扩展性等方面的提升。在优化过程中,需要遵循一些基本原则,例如“避免过早优化”,“优化可度量的瓶颈”和“优化的可持续性”,确保每一步优化工作都是有目的且高效的。
## 性能优化的范围
性能优化可以涵盖多个层面,包括但不限于硬件资源、系统架构、数据库配置、SQL语句和应用程序设计。理解这些不同层面之间的相互影响是进行有效优化的关键。
在这一章中,我们将概述MySQL性能优化的必要性、目标与原则以及优化范围,为读者提供一个清晰的优化框架和思想基础。接下来的章节中,我们将逐步深入探讨MySQL架构与性能指标、优化策略与实践,以及高级优化技巧和案例分析。
# 2. MySQL基础架构与性能指标
## 2.1 MySQL架构组件解析
### 2.1.1 连接层的工作机制
MySQL的连接层位于架构的最顶层,负责接收客户端的连接请求并进行处理。其工作机制涉及到多种连接方式,包括但不限于TCP/IP套接字、命名管道、共享内存等。在这一层,MySQL主要执行以下功能:
- 客户端认证:通过用户名和密码进行用户权限验证。
- 线程管理:为每个客户端连接创建并维护线程。
```sql
-- 示例:使用mysqladmin命令检查服务器上的连接数
mysqladmin -u [username] -p status | grep 'Threads'
```
执行上述命令将输出当前活动连接数,其中显示的Threads值表示活跃线程数。
### 2.1.2 服务层的关键组件
服务层包含多个组件,主要负责MySQL的核心功能,如查询解析、优化和缓存等。
- 查询解析器:负责将SQL语句转换成解析树。
- 查询优化器:分析查询语句,并选择最有效的查询路径。
- 缓存器:缓存查询结果,减少数据库的I/O操作。
在进行查询优化时,可通过查看MySQL的缓存命中率来评估查询缓存的效果:
```sql
-- 示例:查看MySQL缓存命中率
SHOW STATUS LIKE 'Qcache_%';
```
这里`Qcache_inserts`表示插入缓存的查询数,`Qcache_hits`表示缓存命中次数。通过这两个值可以计算出缓存的命中率。
### 2.1.3 引擎层与存储层的区别
MySQL的引擎层和存储层是负责数据存储和检索的两大核心部分。不同的存储引擎在MySQL架构中扮演不同的角色。
- 引擎层:负责管理表的创建、查询、更新等操作。
- 存储层:负责数据的存储和索引的建立。
存储引擎的选择对性能有着显著的影响。例如,InnoDB支持事务处理,适合需要事务支持的应用;而MyISAM在读写性能上表现更佳,适合于读操作多的场景。
```sql
-- 示例:查看当前数据库使用的存储引擎
SHOW TABLE STATUS LIKE 'your_table_name';
```
通过查看表的状态信息,我们可以了解当前表使用的存储引擎类型。
## 2.2 关键性能指标理解
### 2.2.1 事务处理能力
事务处理能力是指数据库管理系统处理事务的能力,是衡量数据库性能的重要指标。事务具有ACID属性,分别代表原子性、一致性、隔离性、持久性。
衡量事务处理能力的两个关键指标是:
- 吞吐量:单位时间内可以处理的事务数量。
- 响应时间:事务提交所需的时间。
### 2.2.2 系统并发能力
系统并发能力指的是数据库在单位时间内处理并发事务的能力。并发事务处理性能的高低直接影响数据库的整体性能。
提高并发性能的常见做法包括:
- 锁优化:减少锁的粒度,使用更细的锁级别,如行级锁。
- 事务大小:控制事务的大小,避免长事务。
```sql
-- 示例:查看当前锁的等待情况
SHOW ENGINE INNODB STATUS;
```
通过分析InnoDB的监控信息,我们可以获知锁等待的次数和等待时间,进而优化并发处理。
### 2.2.3 磁盘I/O性能
磁盘I/O是影响数据库性能的主要因素之一。磁盘I/O性能与数据存储、索引、缓冲池等多个方面相关。
评估磁盘I/O性能的指标主要包括:
- IOPS:每秒操作次数,指的是每秒钟可以完成多少次I/O请求。
- 吞吐量:指每秒可以读写的磁盘数据量。
针对磁盘I/O的优化,通常的做法有:
- 使用更快的磁盘(如SSD)。
- 优化数据文件的存储和索引。
- 调整缓冲池的大小。
```bash
# 示例:使用iostat监控磁盘I/O性能
iostat -dx 1
```
执行上述命令将显示磁盘的读写情况,包括每秒I/O请求次数(r/s, w/s)和数据吞吐量(rkB/s, wkB/s),从而辅助我们判断磁盘I/O性能。
总结以上内容,我们详细介绍了MySQL的基础架构组件以及关键性能指标,为后续的优化策略提供了理论基础。在下一章节中,我们将深入探讨SQL语句调优以及索引管理等关键性能优化实践。
# 3. 优化策略与实践
## 3.1 SQL语句的调优
### 3.1.1 理解EXPLAIN的输出
为了有效地调优SQL语句,我们需要理解MySQL如何执行查询以及如何使用索引。`EXPLAIN`是一个强大的工具,它可以提供查询执行计划的详细信息,从而帮助开发者理解查询的执行流程。以下是使用`EXPLAIN`的示例:
```sql
EXPLAIN SELECT * FROM employees WHERE age > 30 AND department = 'IT';
```
执行上述查询后,我们得到类似下面的输出:
```
+----+-------------+-----------+------------+-------+---------------+----------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+-------+---------------+----------+---------+-------+------+----------+-------+
| 1 | SIMPLE | employees | NULL | index | age,department| age | 4 | NULL | 250 | 30.00 | Using where |
+----+-------------+-----------+------------+-------+---------------+----------+---------+-------+------+----------+-------+
```
解释:
- `select_type`: 查询类型,如`SIMPLE`表示没有子查询或UNION。
- `table`: 输出结果对应的表名。
- `type`: 访问类型,如`index`表示全索引扫描。
- `possible_keys`: 可能用到的索引。
- `key`: 实际使用的索引。
- `key_len`: 使用索引的长度。
- `ref`: 显示索引的哪一列被使用了。
- `rows`: 估计要检查的行数。
- `filtered`: 按表条件过滤的行百分比。
- `Extra`: 包含不适合其他列的额外信息。
通过分析`EXPLAIN`的输出,我们可以发现查询的性能瓶颈,例如是否使用了正确的索引,是否进行了全表扫描等。
### 3.1.2 索引的合理使用与优化
索引是数据库中用来提高查询速度的重要机制。合理创建和使用索引对于数据库性能至关重要。以下是一些优化索引的建议:
- 创建适当的索引以匹配查询模式。使用`EXPLAIN`分析查询,看看是否使用了合适的索引。
- 避免在经常更新的列上创建索引,因为索引的维护会增加额外的开销。
- 使用复合索引以支持多个列上的查询条件。
- 删除不再使用或者性能收益甚微的索引。
### 3.1.3 SQL语句重写技巧
重写SQL语句不仅可以提高性能,还有助于代码的可读性和可维护性。以下是一些常见的SQL优化技巧:
- 避免使用SELECT *,只选择需要的列。
- 减少子查询的使用,尤其是在WHERE子句中,因为它们会增加查询成本。
- 使用JOIN代替子查询,以获得更好的性能。
- 在WHERE子句中使用UNION ALL代替OR。
- 使用LIMIT来限制查询结果的数量,尤其是在处理大量数据时。
## 3.2 索引管理与性能调优
### 3.2.1 索引类型与选择
在选择索引类型时,需要考虑不同索引类型的特点和适用场景:
- B-Tree索引是大多数情况下最适合的索引类型,因为它可以优化比较操作,适用于全键值、键值范围或键值前缀查找。
- 哈希索引适合用于等值比较操作,但不支持范围查找。
- R-Tree索引适用于空间数据类型的字段。
### 3.2.2 索引碎片整理
随着时间的推移,数据库中的索引可能会变得碎片化,这会影响性能。为了保持性能,建议定期进行索引碎片整理:
```sql
ALTER TABLE table_name REPAIR TABLE;
```
这个命令可以修复表中的索引和数据碎片。不过,需要注意的是,`REPAIR TABLE`在某些情况下可能需要锁表。
### 3.2.3 覆盖索引与查询优化
覆盖索引是指一个索引包含所有需要查询的字段数据。使用覆盖索引可以避免读取数据行,从而显著提升查询性能。
例如,如果我们的查询是:
```sql
SELECT age, department FROM employees WHERE age > 30;
```
确保`age`和`department`字段在索引中,我们就可以避免访问数据表来获取这些列的值。
## 3.3 查询缓存的利用与限制
### 3.3.1 查询缓存的工作原理
MySQL使用查询缓存来存储之前执行过的查询结果,以避免重复解析和执行相同查询。当新的查询提交到MySQL时,它首先检查查询缓存:
- 如果缓存命中,则直接返回结果。
- 如果缓存未命中,则执行查询,并将结果存储到缓存中。
### 3.3.2 查询缓存的优化策略
为了充分利用查询缓存,可以考虑以下策略:
- 确保`query_cache_type`配置正确。
- 使用`SQL_CACHE`提示来明确请求缓存查询结果。
- 避免缓存大结果集,因为它们会占用大量缓存空间。
- 定期清理缓存,使用如下命令:
```sql
FLUSH QUERY CACHE;
```
### 3.3.3 缓存失效与容量管理
查询缓存不是万能的,以下情况会导致缓存失效:
- 表数据发生变化。
- 查询依赖的数据库对象发生变化。
- MySQL服务器重启。
为了避免缓存失效对性能的负面影响,可以采取以下措施:
- 减少写操作频率。
- 适当调整缓存大小。
- 监控缓存使用情况并适时增加缓存容量。
通过合理配置和监控查询缓存,可以显著提高数据库的性能。
# 4. MySQL高级优化技巧
## 4.1 高可用架构优化
### 4.1.1 读写分离的实现与优化
读写分离是提高MySQL数据库高可用性的重要手段之一。它能够将读操作和写操作分散到不同的服务器上,从而实现负载均衡和性能提升。
#### 4.1.1.1 读写分离架构原理
在读写分离架构中,主服务器处理所有的写操作以及关键的读操作,而从服务器则负责处理其他读操作。写操作之后,数据需要通过日志复制到从服务器,保证数据的一致性。通过这种方式,主服务器的读取负载被从服务器分担,系统整体性能得以提升。
#### 4.1.1.2 实现方式
读写分离的实现可以有多种方式,例如使用MySQL内置的复制功能或者使用第三方的代理软件。MySQL复制利用二进制日志文件(binlog)将主服务器上的数据变更同步到从服务器。
#### 4.1.1.3 优化策略
- **监控与故障转移**:确保读写分离架构中的主服务器和从服务器状态能够被实时监控,并且快速地实现故障转移。
- **读写负载均衡**:通过代理层或者DNS轮询实现读写请求的智能路由,提高整体的数据库服务能力。
- **从服务器的健康检查**:定期检查从服务器的状态,确保从服务器能够随时接管主服务器的工作。
#### 4.1.1.4 代码块示例
```sql
-- 在主服务器上配置复制
CHANGE MASTER TO
MASTER_HOST='master_host_name',
MASTER_USER='replication_user_name',
MASTER_PASSWORD='replication_password',
MASTER_LOG_FILE='recorded_log_file_name',
MASTER_LOG_POS=recorded_log_position;
-- 在从服务器上启动复制进程
START SLAVE;
```
上述代码块展示了如何在MySQL中设置主从复制,从而实现读写分离。配置主服务器的复制信息后,在从服务器上运行`START SLAVE`命令开始复制过程。
### 4.1.2 分区表的应用场景与优势
分区表是将一个大表分解为多个较小的、更易于管理的逻辑部分的技术,可以提高数据访问的效率。
#### 4.1.2.1 分区表的优势
- **提高查询效率**:查询可以只扫描部分分区而非整个表。
- **优化数据维护**:分区表的数据管理更加灵活,例如进行数据归档。
- **增强可用性**:可以单独对一个分区进行备份或修复,而不影响整个表。
#### 4.1.2.2 分区策略
分区策略包括范围分区、列表分区、哈希分区等,每种策略适用于不同的场景。
- **范围分区**:适用于数据能够按照一定范围划分的场景。
- **列表分区**:适用于数据有明确的分类,并且各分类数据量相等的情况。
- **哈希分区**:适用于分布访问较为均匀的情况。
### 4.1.3 复制的配置与监控
复制是MySQL数据库高可用架构中的核心组件,合理的配置与监控是确保复制稳定性和效率的关键。
#### 4.1.3.1 复制的基本配置
MySQL复制的基本配置涉及二进制日志的启用和配置、复制账户的创建和权限分配,以及复制过程的启动。
```sql
-- 启用二进制日志
SET @@global.log_bin = 'mysql-bin';
-- 创建复制用户
CREATE USER 'replicator'@'%' IDENTIFIED BY 'replicator_password';
GRANT REPLICATION SLAVE ON *.* TO 'replicator'@'%';
-- 获取主服务器状态信息
SHOW MASTER STATUS;
-- 在从服务器上配置复制
CHANGE MASTER TO
MASTER_HOST='master_host_name',
MASTER_USER='replicator',
MASTER_PASSWORD='replicator_password',
MASTER_LOG_FILE='log-file-name',
MASTER_LOG_POS=log-file-position;
```
#### 4.1.3.2 复制的监控
复制监控关注复制延迟、复制错误及主从服务器状态等。可以通过一些专门的工具,如Percona Monitoring and Management(PMM)进行实时监控。
## 4.2 数据库参数调优
### 4.2.1 关键数据库变量的调整
数据库的性能调优往往需要对关键参数进行细致的调整,这些参数对数据库的性能有着直接的影响。
#### 4.2.1.1 缓冲池大小
InnoDB缓冲池是用于缓存数据和索引的内存区域。合理设置`innodb_buffer_pool_size`参数,可以减少磁盘I/O操作,提高数据库性能。
```sql
-- 调整InnoDB缓冲池大小
SET GLOBAL innodb_buffer_pool_size = 1024*1024*1024; -- 1GB
```
#### 4.2.1.2 查询缓存大小
查询缓存用于存储MySQL查询的结果。通过调整`query_cache_size`参数,可以优化查询缓存的使用。
```sql
-- 调整查询缓存大小
SET GLOBAL query_cache_size = 1024*1024; -- 1MB
```
#### 4.2.1.3 线程缓存大小
线程缓存保存了服务线程的副本,以加速新连接的处理。`thread_cache_size`参数用于定义缓存线程的数量。
```sql
-- 调整线程缓存大小
SET GLOBAL thread_cache_size = 10;
```
### 4.2.2 InnoDB引擎优化设置
InnoDB作为MySQL中广泛使用的存储引擎,其优化设置对于数据库性能的提升至关重要。
#### 4.2.2.1 表空间的管理
使用`innodb_file_per_table`设置可以为每个表创建独立的表空间文件,这有助于提高数据管理的灵活性和备份的效率。
```sql
-- 设置每个表使用独立的表空间
SET GLOBAL innodb_file_per_table = 1;
```
#### 4.2.2.2 日志文件大小
`innodb_log_file_size`参数定义了InnoDB事务日志文件的大小。较大的日志文件可以提高性能,但也会增加恢复时间。
```sql
-- 设置InnoDB日志文件大小
SET GLOBAL innodb_log_file_size = 1024*1024*1024; -- 1GB
```
### 4.2.3 缓冲池与线程优化
#### 4.2.3.1 缓冲池实例数量
通过增加`innodb_buffer_pool_instances`参数可以创建多个缓冲池实例,这样可以减少缓冲池的竞争,提升并发处理能力。
```sql
-- 增加缓冲池实例数量
SET GLOBAL innodb_buffer_pool_instances = 8;
```
#### 4.2.3.2 线程缓存管理
合理配置线程缓存参数可以避免频繁的线程创建和销毁,提升性能。
```sql
-- 配置线程缓存大小
SET GLOBAL thread_cache_size = 50;
```
## 4.3 硬件资源的优化
### 4.3.1 CPU与内存的配置策略
MySQL数据库的性能直接受到服务器硬件配置的影响,特别是CPU和内存资源。
#### 4.3.1.1 CPU资源优化
CPU资源对于MySQL来说至关重要,尤其是在处理大量并发事务时。优化策略包括增加CPU核心数、提升CPU主频、合理分配CPU资源给数据库进程等。
#### 4.3.1.2 内存资源优化
内存资源主要用于缓冲池、线程缓存和查询缓存。优化内存的策略包括根据MySQL的运行需求合理分配内存、避免过度分配内存资源导致系统不稳定。
### 4.3.2 存储系统的考量与选择
存储系统的性能和稳定性对于MySQL数据库至关重要,它决定了数据读写的速度和数据安全性。
#### 4.3.2.1 存储介质的选择
传统的机械硬盘和现代的SSD固态硬盘各有优势。机械硬盘在成本上更具优势,但SSD在读写速度、随机访问性能上表现更好。
#### 4.3.2.2 RAID级别的选择
RAID技术通过磁盘阵列提高存储系统的可靠性和性能。不同的RAID级别适用于不同的业务需求和成本预算,如RAID 10提供较好的读写性能和数据冗余。
### 4.3.3 网络对数据库性能的影响
网络的带宽、延迟和稳定性直接影响数据库操作的响应时间和数据一致性。
#### 4.3.3.1 网络带宽
高带宽能够减少网络传输时间,尤其对大数据量操作和远程数据库访问有显著影响。
#### 4.3.3.2 网络延迟
低延迟的网络环境可以减少数据往返时间,提升数据库操作的效率。
#### 4.3.3.3 网络稳定性
稳定的网络环境是数据库高可用性的基础,能够确保数据传输的完整性和一致性。
# 5. 性能优化案例分析
## 5.1 典型业务场景分析
在实际的业务场景中,数据库管理员需要根据不同的业务需求来对MySQL数据库进行优化。以下是一些典型的业务场景及其优化策略。
### 5.1.1 高并发业务处理的优化案例
在高并发的业务场景中,数据库面临的最大问题就是处理大量用户的并发请求,这通常出现在电商、社交、游戏等平台的高峰期。在这种情况下,主要优化策略包括:
- **读写分离**:通过使用主从复制,将读操作分配给从服务器,写操作仍由主服务器处理。这可以有效分散读操作的压力。
- **使用缓存**:例如使用Redis或Memcached来缓存热点数据,减少数据库的直接访问。
- **优化SQL和索引**:确保关键的查询使用高效的SQL语句和良好的索引策略,减少单个查询所需处理的数据量。
### 5.1.2 大数据量处理的优化策略
当数据库处理的数据量非常大时,如数据仓库或日志系统,性能优化则侧重于数据的管理与查询效率:
- **分区表**:通过水平或垂直分区来组织表,使得查询操作只涉及部分分区,减少I/O负载。
- **批量处理**:批量插入或更新数据,减少单条记录操作的开销。
- **列式存储**:对于特定的数据仓库应用,使用列式存储如Apache Parquet,可以提高数据扫描效率。
### 5.1.3 数据库扩展性与维护性案例
在扩展性方面,业务的快速成长往往要求数据库具备良好的扩展性,以便在不影响现有服务的情况下进行水平或垂直扩展:
- **服务拆分**:通过业务划分,将大型数据库拆分成多个小型数据库,分散压力。
- **分库分表**:在垂直方向上进行拆分,减轻单个表的压力。
- **读写分离**:通过主从复制,扩展读操作的处理能力,保证写操作的性能不受影响。
## 5.2 常见问题诊断与解决
在数据库的长期运行过程中,难免会遇到一些性能瓶颈和故障,比如慢查询、死锁等问题。
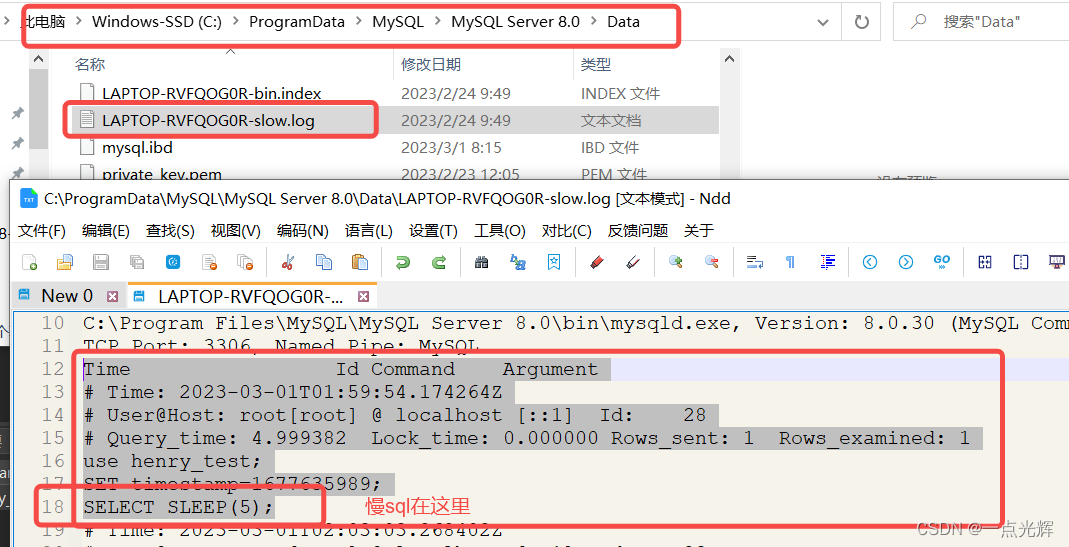
### 5.2.1 慢查询的识别与优化
慢查询对用户体验和系统性能都有极大的负面影响。解决慢查询通常包括以下步骤:
- **启用慢查询日志**:开启慢查询日志记录,找出执行时间超过阈值的SQL语句。
- **分析查询计划**:使用`EXPLAIN`命令分析查询语句的执行计划,优化涉及的索引和表结构。
- **优化SQL语句**:重构SQL语句,避免全表扫描,确保使用到正确的索引。
### 5.2.2 死锁的避免与处理
死锁是数据库事务中的一种资源竞争状态,可采取以下措施:
- **控制事务大小**:限制事务所涉及的数据量,减少资源锁定的时间。
- **事务顺序化**:确保事务的执行顺序一致,避免循环等待资源。
- **及时回滚**:当检测到死锁时,及时回滚事务,释放资源。
### 5.2.3 事务日志管理的优化
事务日志记录了数据库的所有更改,优化事务日志管理可以提高数据库的性能和稳定性:
- **日志文件大小与数量**:合理配置二进制日志(binlog)的大小和数量,避免日志文件过大导致的性能问题。
- **日志清理策略**:定时清理旧的日志文件,减少磁盘空间使用和提高日志备份的效率。
## 5.3 性能监控与调优工具应用
为确保数据库的性能处于最佳状态,监控和调优工具的使用显得尤为重要。
### 5.3.1 MySQL监控工具介绍
MySQL自带的性能监控工具,例如`SHOW STATUS`和`SHOW PROCESSLIST`,能够提供性能相关的各种指标。除此之外,还有第三方的监控工具如Percona Monitoring and Management (PMM)、MySQL Enterprise Monitor等,它们能够提供更加直观的监控界面和更加深入的性能分析。
### 5.3.2 性能数据的收集与分析
性能数据的收集和分析是优化工作的基础,收集到的数据需要通过各种分析方法来诊断问题:
- **趋势分析**:观察指标随时间的变化趋势,以便预测潜在问题。
- **对比分析**:将当前性能数据与历史数据进行对比,分析性能的波动。
- **相关性分析**:分析不同性能指标之间的相关性,如CPU负载与查询延迟的相关性。
### 5.3.3 自动化调优工具的使用
为了减轻DBA的负担,许多公司开发了自动化调优工具,如`mysqltuner`和`Percona Toolkit`中的`pt-online-schema-change`。自动化工具能够基于当前的数据库状态提出优化建议,甚至自动执行某些优化操作。
通过结合以上各类工具和策略,IT专业人士可以有针对性地对数据库性能进行持续优化。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MySQL 数据库的使用案例和最佳实践,涵盖广泛的主题,包括:
* 架构设计:打造高效可扩展的数据库系统
* 迁移策略:升级和迁移 MySQL 数据库的最佳实践
* 数据保护:备份和恢复 MySQL 数据的核心策略
* 查询优化:提升查询效率的黄金规则
* 数据库调优:使用分析和调优工具的实战指南
* 高可用性:主从复制和故障转移的实用指南
* 水平扩展:分区和分表技术的深入解析
* 索引管理:高效索引创建和维护的实用技巧
* 日志分析:故障诊断和性能调优的秘密武器
* NoSQL 与 MySQL 融合:混合架构下的数据管理和优化策略
* 数据库逆向工程:从应用代码推导数据库设计
* 数据字典管理:构建高效数据管理平台的方法论
本专栏旨在为数据库管理员、开发人员和架构师提供全面的指导,帮助他们有效地使用 MySQL 数据库,提高性能、可靠性和可扩展性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【图像分析软件深度剖析】:Image-Pro Plus 6.0 高级功能全面解读

参考资源链接:[Image-Pro Plus 6.0 中文
【智慧竞赛必备】:四人抢答器设计全面指南与优化秘籍
参考资源链接:[四人智力竞赛抢答器设计与实现](https://wenku.csdn.net/doc/6401ad39cce7214c316eebee?spm=1055.2635.3001.10343)
# 1. 四人抢答器设计概述
## 1.1 设计背景
在日常的学术研讨、知识竞赛以及各种娱乐节目中,我们经常能看到抢答器的身影。随着技术的发展和应用场景的多样化,对抢答器的性能和功能提出了更高的要求。一个高效、准确
高通Camera Chi-CDK Feature2性能与兼容性秘籍:跨平台与调优全攻略

参考资源链接:[高通相机Feature2框架深度解析](https://wenku.csdn.net/doc/31b2334rc3?spm=1055.2635.3001.10343)
# 1. Camera Chi-CDK Feature2概述
## 1.1 Camera Chi-CDK Feature2
验证规则的最佳实践:精通系统稳定性

参考资源链接:[2014年Mentor Graphics Calibre SVRF标准验证规则手册](https://wenku.csdn.net/doc/70kc3iyyux?spm=1055.2635.3001.10343)
# 1. 系统稳定性的基础理论
系统稳定性是指在一定时间内,系统保持其功能正常运行的能力。它是一个复杂的话题,涉及多个方面,包括硬
深入解析Android WebView文件下载:性能优化与安全性提升指南

参考资源链接:[Android WebView文件下载实现教程](https://wenku.csdn.net/doc/3ttcm35729?spm=1055.2635.3001.10343)
# 1. Android WebView文件下载基础
## 1.1 WebView概述
在移动应用开发中,WebView是一个重要的组件,它
【交互设计的艺术】:优雅地引导用户订阅小程序消息
参考资源链接:[小程序订阅消息拒绝后:如何引导用户重新开启及获取状态](https://wenku.csdn.net/doc/6451c400ea0840391e738237?spm=1055.2635.3001.10343)
# 1. 交互设计在小程序中的重要性
随着互联网技术的不断进步,小程序作为移动互联网领域的新宠,其用户界面(UI)和用户体验(UX)的重要性日益凸显。交互设计作为用户体验的核心
【S19文件错误排查】:高效排除常见错误,提升调试效率
参考资源链接:[S19文件格式完全解析:从ASCII到MCU编程](https://wenku.csdn.net/doc/12oc20s736?spm=1055.2635.3001.10343)
# 1. S19文件错误排查概述
S19文件错误排查是嵌入式开发中常见的工作流程之一,尤其在微控制器程序开发中占有重要的地位。本
【PLC编程语言对比】:梯形图与指令列表的优劣深度分析
参考资源链接:[PLC毕业设计题目大全:300+精选课题](https://wenku.csdn.net/doc/3mjqawkmq0?spm=1055.2635.3001.10343)
# 1. PLC编程语言概述
## 1.1 PLC编程语言的发展简史
可编程逻辑控制器(PLC)自20世纪60年代问世以来,便成为了工业自动化领域不可或缺的设备。PLC编程语言也随着技术的不断进步,从最初的继电器逻辑图,发展到如今包括梯形图、指令列表(IL)、功能块
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )