【跨语言数据分析】:从R到Python,Anaconda的角色转变
发布时间: 2024-12-07 14:15:06 阅读量: 12 订阅数: 13 

通过anaconda图形界面配置Python数据分析开发环境.docx

# 1. 跨语言数据分析概述
在当今的数据驱动世界中,数据分析正变得越来越重要。企业和研究者常常面临着在多种编程语言之间选择的难题,尤其是当涉及到复杂的数据处理和统计分析时。跨语言数据分析是解决这一难题的关键,它允许我们利用不同语言的优势,对数据进行更加高效和深入的探索。在这一章节中,我们将概述跨语言数据分析的重要性和基本概念,从而为接下来各章节深入分析R语言和Python语言的数据分析基础打下基础。我们将探讨跨语言数据分析的动机、优势以及如何在R和Python之间架起桥梁,为读者提供在不同场景下选择最合适的工具的见解。
# 2. R语言的数据分析基础
### 2.1 R语言简介
#### 2.1.1 R语言的特点与应用领域
R语言是一种用于统计分析和图形表示的编程语言和软件环境。它以其在数据挖掘、机器学习以及统计模型方面的强大功能而闻名。R语言的几个显著特点包括:
- **开源免费**:R语言遵循GNU通用公共许可证,是完全开源且免费的。
- **丰富的统计包**:R拥有超过10000个用户贡献的包,覆盖从基础统计分析到高级机器学习算法。
- **良好的社区支持**:活跃的社区提供了大量的文档、论坛以及问答资源。
- **跨平台兼容性**:R可以在多种操作系统上运行,包括Windows、MacOS和Linux。
- **可扩展性**:R语言支持自定义函数和包,可以轻松扩展以满足特定需求。
R语言的应用领域广泛,涉及:
- **统计分析**:在学术和研究机构中,R语言常用于执行复杂的统计测试。
- **金融分析**:用于市场风险分析、高频交易等金融领域。
- **生物信息学**:在基因组学和药物设计中分析复杂数据集。
- **商业智能**:用于市场分析、销售预测等商务智能应用。
#### 2.1.2 R语言的安装与环境配置
安装R语言的步骤简单明了,适用于多种操作系统:
1. **访问官方网站**:打开R语言的官方网站(CRAN)下载页面。
2. **选择操作系统**:根据您的操作系统(Windows、MacOS或Linux)下载相应的安装程序。
3. **下载安装**:运行下载的安装程序,并按照向导指示完成安装。
4. **环境配置**:安装完成后,打开R控制台,执行`install.packages("包名")`命令安装需要的包。
下面是一个R语言环境配置的代码示例:
```r
# R语言版本检查
version
# 安装必要包
install.packages("ggplot2")
install.packages("dplyr")
# 载入包
library(ggplot2)
library(dplyr)
```
### 2.2 R语言的数据结构和操作
#### 2.2.1 常用数据类型及操作
R语言中的基本数据类型包括:
- **向量(Vector)**:R语言中最基本的数据结构,用于存储数值、字符或逻辑值。
- **因子(Factor)**:用于表示分类变量,每个因子值都对应一个整数标签。
- **数组(Array)**:用于存储多维数据的同质数据结构。
- **矩阵(Matrix)**:二维数组,其中元素必须是相同类型。
- **数据框(Data Frame)**:类似于数据库表,每一列可以是不同类型的。
对这些数据结构的基本操作包括创建、修改、访问和子集化等。
这里展示如何创建和操作向量:
```r
# 创建向量
my_vector <- c(1, 2, 3, 4, 5)
# 访问向量元素
my_vector[3]
# 修改向量元素
my_vector[3] <- 30
# 子集化操作
my_vector[c(1, 5)]
```
#### 2.2.2 R语言的向量化计算和矩阵运算
R语言的优势之一是向量化计算,即对整个向量执行操作而不是对单个元素。例如:
```r
# 向量化计算
a <- 1:4
b <- 5:8
result <- a + b # 结果是6 8 10 12
```
矩阵运算是线性代数计算的基础。R语言提供了多种矩阵操作:
```r
# 创建矩阵
m <- matrix(1:6, nrow=2, ncol=3)
# 矩阵乘法
n <- matrix(7:12, nrow=3, ncol=2)
result_matrix <- m %*% n
```
### 2.3 R语言的统计分析与图形展示
#### 2.3.1 基本统计分析方法
R语言提供了丰富的统计函数来进行数据分析,如:
- `mean()`: 计算均值。
- `median()`: 计算中位数。
- `var()`: 计算方差。
- `sd()`: 计算标准差。
下面是一个执行基本统计分析的代码示例:
```r
# 创建数据
data <- c(2.9, 3.0, 2.5, 3.6, 3.9, 3.9, 3.5, 3.7, 3.1, 4.0)
# 计算基本统计量
mean_value <- mean(data)
median_value <- median(data)
variance_value <- var(data)
sd_value <- sd(data)
# 输出结果
list(mean=mean_value, median=median_value, variance=variance_value, sd=sd_value)
```
#### 2.3.2 高级统计模型和图形绘制技巧
R语言不仅适用于基本统计分析,还支持构建和应用高级统计模型,例如线性回归、广义线性模型(GLM)等。同时,R的绘图系统非常强大,可使用基础图形、lattice、ggplot2等包创建复杂和美观的图形。
下面是一个使用ggplot2包绘制散点图的例子:
```r
# 载入ggplot2包
library(ggplot2)
# 创建数据框
data <- data.frame(
x = rnorm(100),
y = rnorm(100)
)
# 绘制散点图
ggplot(data, aes(x=x, y=y)) +
geom_point() +
theme_minimal()
```
以上仅是R语言在数据分析基础方面的一部分内容。要掌握R语言,还需要深入了解其编程逻辑、包的使用以及与其他编程语言的协同工作能力。通过本章节的介绍,您应该对R语言有了初步的认识,并可以在实际数据分析工作中开始尝试应用。接下来的章节将深入介绍Python语言的数据分析基础,探索两种语言在数据分析领域的不同特点和优势。
# 3. Python语言的数据分析基础
## 3.1 Python简介
Python作为一门高级编程语言,以其简洁明了的语法,强大的库生态系统和广泛的应用场景赢得了IT从业者的青睐。本节将深入探讨Python的特点以及它在数据科学领域的应用。
### 3.1.1 Python的特点与应用领域
Python被设计为一种具有清晰语法的解释型语言,这使得它成为了初学者的理想选择。Python的三大特点:
- **易读性**:Python代码的可读性非常强,这有助于维护和协作。
- **广泛的标准库和第三方库**:无论是Web开发、网络爬虫、数据分析、人工智能等领域,Python都有丰富的库支持。
- **跨平台兼容性**:Python支持在多种操作系统上运行,如Windows、Linux、macOS等。
Python的这些特性使其在多个应用领域大放异彩:
- **Web开发**:Django和Flask等框架让Python成为构建Web应用的流行选择。
- **数据科学**:NumPy、Pandas和Scikit-learn等库的使用让Python成为数据科学领域的重要工具。
- **自动化脚本**:Python能够编写各种自动化任务的脚本,提高工作效率。
- **机器学习与人工智能**:TensorFlow、Keras和PyTorch等框架都支持Python,是当前AI研究的主流选择。
### 3.1.2 Python的安装与环境配置
安装Python是一个简单直接的过程,但为了进行数据分析,推荐安装Anaconda,它是一个开源的Python发行版本,包含了科学计算和数据分析常用的包和依赖。
安装步骤如下:
1. 访问Anaconda官方网站下载适合操作系统的Anaconda安装包。
2. 执行下载的安装包并遵循安装向导完成安装。
3. 安装完成后,打开终端或命令提示符,使用`conda --version`来验证是否安装成功。
进行环境配置的目的是为了设置一个良好的工作环境,这可以通过创建虚拟环境来实现:
```bash
conda create -n myenv python=3.8 # 创建名为myenv的环境,使用Python 3.8版本
conda activate myenv # 激
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Anaconda在数据科学中的应用》专栏深入探讨了Anaconda在数据科学领域的广泛应用。文章涵盖了Anaconda的入门指南、环境构建、高级配置、并行计算加速、协作分析、版本控制、云部署、框架整合、数据可视化、机器学习模型优化、大数据处理和自动化数据分析等主题。通过这些文章,读者可以全面了解Anaconda在数据科学工作流程中的作用,并掌握如何利用Anaconda提高数据分析效率和协作能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【UHD 620核显驱动与虚拟机兼容性详解】:VMware和VirtualBox中的最佳实践
参考资源链接:[Win7 64位下UHD 620/630核显驱动发布(8代处理器适用)](https://wenku.csdn.net/doc/273in28khy?spm=1055.2635.3001.10343)
# 1. UHD 620核显驱动概述
## 1.1 UHD
【BODAS编程实践】:6个高效编码秘诀,让你成为控制应用代码高手
参考资源链接:[BODAS控制器编程指南:从安装到下载的详细步骤](https://wenku.csdn.net/doc/6ygi1w6m14?spm=1055.2635.3001.10343)
# 1. BODAS编程实践概览
在当今这个以数据为中心的世界里,BODAS编程语言因其独特的架构和强大的性能,受到了越来越多开发者的青睐。它不仅仅是一种工具,更是一种设计理念,它在处理大规模数据和实时计算方面展现了出色的能力。本章将为读者提供一
【LabVIEW错误代码应用秘籍】:提升效率的10个技巧
参考资源链接:[LabVIEW错误代码大全:快速查错与定位](https://wenku.csdn.net/doc/7am571f3vk?spm=1055.2635.3001.10343)
# 1. LabVIEW错误代码的基础知识
在LabVIEW的编程实践中,错误代码是程序运行时不可或缺的一部分,它们帮助开发者理解程序执行过程中可能遇到的问题。理解错误代码对于提升L
Fluent UDF并行计算优化秘籍:提升大规模仿真效率的终极指南
参考资源链接:[Fluent UDF中文教程:自定义函数详解与实战应用](https://wenku.csdn.net/doc/1z9ke82ga9?spm=1055.2635.3001.10343)
# 1. Fluent UDF并行计算基础
Fluent是流体仿真领域广泛使用的计算流体动力学(CFD)软件,其用户定义函数(UDF)是扩展软件功能的强大工具。本章节将探
内存乒乓缓存机制:C语言最佳实践
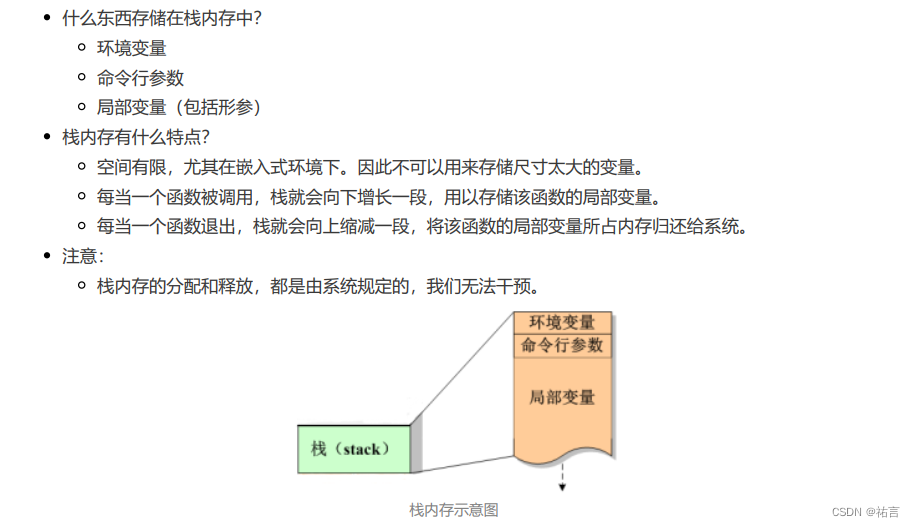
参考资源链接:[C代码实现内存乒乓缓存与消息分发,提升内存响应](https://wenku.csdn.net/doc/64817668d12cbe7ec369e795?spm=1055.2635.3001.10343)
# 1. 内存乒乓缓存机制概述
## 内存乒乓缓存简介
内存乒乓缓存机制是一种高效的内存管理策略,它通过使用两组内存缓冲区交替处理数据流,以减少缓存失效和提高系统性能。这种机制特别适用于数据流连续且具有
宏命令性能优化策略:提升执行效率的5大技巧
参考资源链接:[魔兽世界(WOW)宏命令完全指南](https://wenku.csdn.net/doc/6wv6oyaoy6?spm=1055.2635.3001.10343)
# 1. 宏命令性能优化概述
在现代IT行业中,宏命令作为一种常见的自动化指令集,广泛应用于多种场景,如自动化测试、系统配置等。性能优化,尤其是对宏命令的优化,对于提高工作效率、保障系统稳定性以及实现资源高效利用具有重要意义。本章将
【HBM ESD测试自动化】:结合JESD22-A114-B标准的新技术应用

参考资源链接:[JESD22-A114-B(EDS-HBM).pdf](https://wenku.csdn.net/doc/6401abadcce7214c316e91b7?spm=1055.2635.3001.10343)
# 1. HBM ESD测试概述
在现代电子制造领域中,随着集成电路密度的不断提高和尺寸的不断缩小,电路对静电放电(ESD)的敏感性也随之增加,这成为了电子行
【CAD许可问题急救手册】:迅速诊断并解决“许可管理器不起作用或未正确安装”
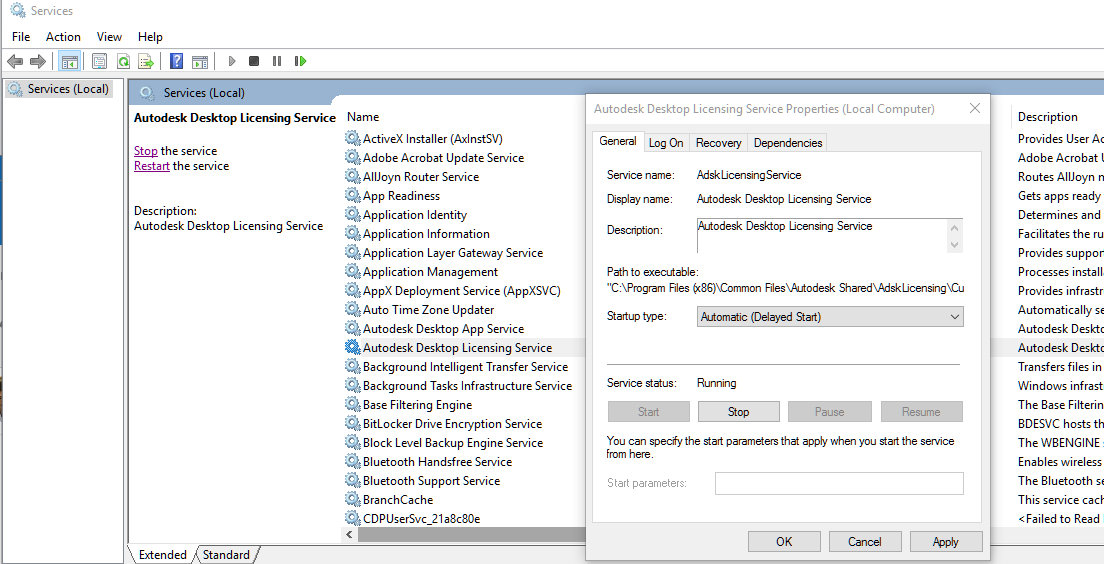
参考资源链接:[CAD提示“许可管理器不起作用或未正确安装。现在将关闭AutoCAD”的解决办法.pdf](https://wenku.csdn.net/doc/644b8a65ea0840391e559a08?spm=1055.2635.3001.10343)
# 1. CAD许可问题概述
CAD软件作为工程设计领域不可或缺的工具,其许可问题一直备受关注。本章将为读者提供一个关于CAD许
深入解析STC89C52单片机:掌握内部结构的5大核心要点
参考资源链接:[STC89C52单片机中文手册:概览与关键特性](https://wenku.csdn.net/doc/70t0hhwt48?spm=1055.2635.3001.10343)
# 1. STC89C52单片机概述
STC89C52单片机作为一款经典的8位微控制器,它在工业控制、家用电器和嵌入式系统设计等领域广泛应用于各种控制任务。它由STC公司生产,是基于Intel 8051内核的单片机产品系列之一。该单片机因其高可靠性和高性价比而被广泛采用,其性能在对资源要求不是极高的场合完全能够满足。
核心硬件组成方面,STC89C52拥有4KB的内部程序存储器(ROM)、128字节
【计算机网络与体系结构融合】:整合技术与系统整合的五大方法

参考资源链接:[王志英版计算机体系结构课后答案详解:层次结构、虚拟机与透明性](https://wenku.csdn.net/doc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )