Spark Core案例分析:WordCount与统计技巧
187 浏览量
更新于2024-08-29
收藏 671KB PDF 举报
"Spark Core的学习笔记,主要涵盖了WordCount案例的详细执行流程,以及如何统计最受欢迎的老师topN的不同方法,包括自定义分区器的应用。此外,还涉及到根据IP计算归属地的问题。"
Spark Core是Apache Spark的核心组件,它提供了分布式数据处理的基础框架。在Spark中,RDD(弹性分布式数据集)是基本的数据抽象,它代表了一个不可变、分区的记录集合,并可以在多台机器上并行操作。
1. WordCount案例详解
WordCount是Spark的典型入门示例,用于统计文本中每个单词出现的次数。在Spark中,这一过程通常包括以下步骤:
- 创建SparkConf对象,设置应用程序名称,如"ScalaWordCount",并在本地模式下启动Spark,设置master为"local[4]",表示使用4个线程。
- 创建SparkContext,作为与Spark集群交互的入口点。
- 从指定路径读取数据,生成一个HadoopRDD,然后通过flatMap操作将每一行文本分割成单词。
- 使用map操作将每个单词映射为(word, 1)的键值对,表示每个单词出现一次。
- reduceByKey操作按单词进行聚合,将相同的单词键值对合并,累加其对应的值。
- sortBy操作按单词出现的次数进行降序排序。
- 最后,使用saveAsTextFile将结果保存到文件系统中,关闭SparkContext以释放资源。
在执行WordCount时,会生成6个RDD,并在reduceByKey操作处触发一次shuffle,生成2个Stage,Task的数量由RDD的分区决定。
2. 统计最受欢迎老师topN
- 方法一:不设置分组和分区,直接进行reduceByKey操作,然后通过sortByKey获取topN。
- 方法二:先设置分组,再过滤出满足条件的键值对,然后reduceByKey和sortByKey。
- 方法三:使用自定义分区器,确保热门元素在同一个节点上处理,以减少网络传输。
3. 根据IP计算归属地
这部分可能涉及将IP地址映射到地理位置的过程,可能需要用到IP到地理位置的数据库或服务,通过lookup操作查找IP对应的国家或地区。
Spark Core的强大在于它的并行计算能力和内存优化,能够高效处理大规模数据。通过理解并掌握这些基础知识,可以进一步探索Spark SQL、Spark Streaming等其他模块,以实现更复杂的分布式数据处理任务。
Spark Core 笔记笔记02
Spark Core学习学习
对最近在看的赵星老师Spark视频中关于SparkCore的几个案例进行总结。
目录目录1.WordCountWordCount 执行流程详解2.统计最受欢迎老师topN1. 方法一:普通方法,不设置分组/分区2. 方法二:设置分组和过滤器3. 方法三:自定义分区器3.根据IP计算归属地
1.WordCount
Spark Core入门案例。
//创建spark配置,设置应用程序名字
//val conf=new SparkConf().setAppName("ScalaWordCount")
//设置本地调试
val conf=new SparkConf().setAppName("ScalaWordCount").setMaster("local[4]")
//创建spark执行的入口
val sc=new SparkContext(conf)
//指定以后从哪里读取数据创建RDD
//sc.textFile(args(0)).flatMap(_.split("")).map((_,1)).reduceByKey(_+_).sortBy(_._2,false).saveAsTextFile(args(1))
val lines: RDD[String] = sc.textFile(args(0))
//切分压平
val words:RDD[String]=lines.flatMap(_.split(""))
//将单词和一组合
val wordAndOne: RDD[(String, Int)] = words.map((_,1))
//按key进行聚合
val reduced: RDD[(String, Int)] = wordAndOne.reduceByKey(_+_)
//排序
val sorted: RDD[(String, Int)] = reduced.sortBy(_._2,false)
//将结果保存到HDFS中
sorted.saveAsTextFile(args(1))
//释放资源
sc.stop()
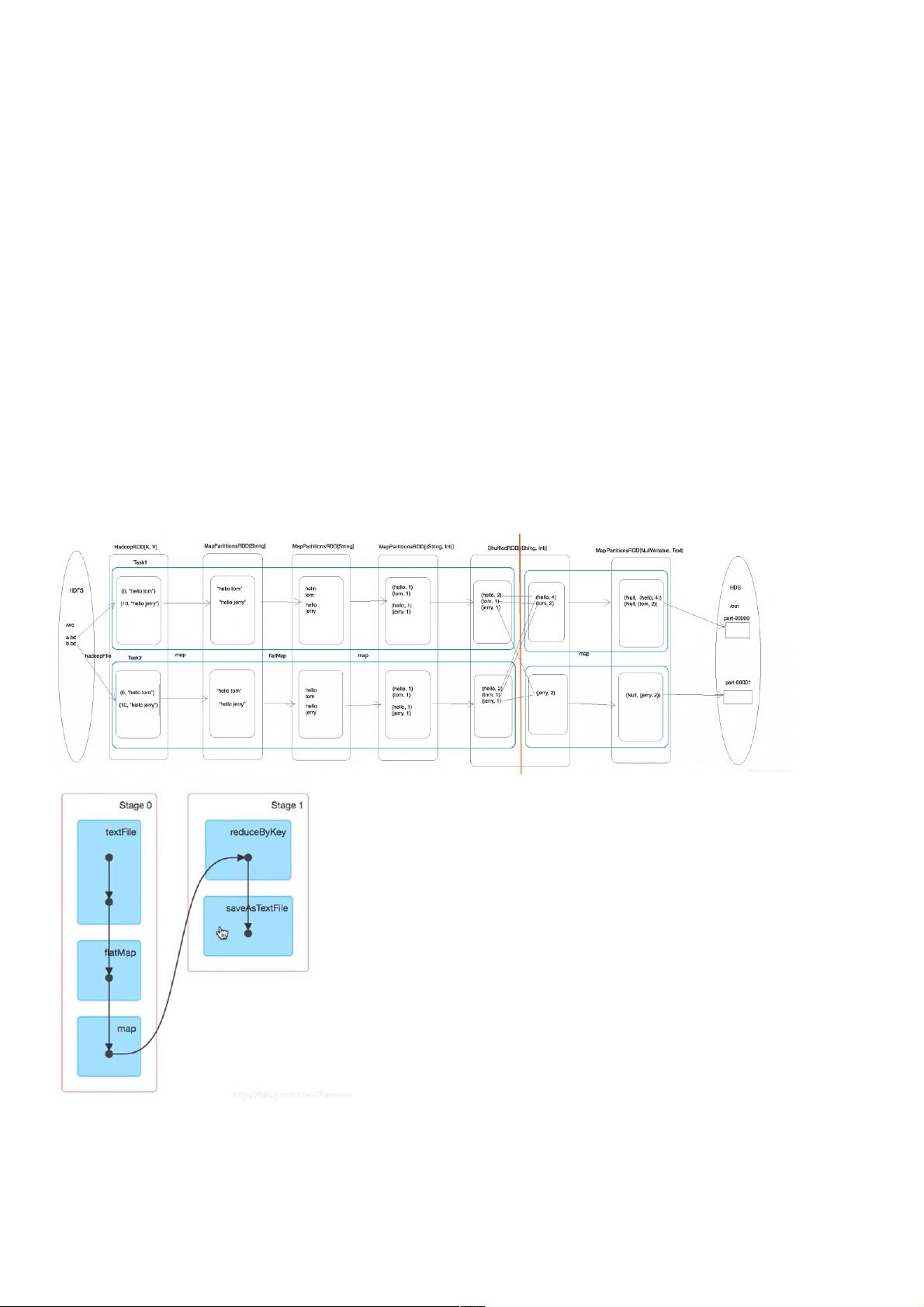
WordCount 执行流程详解执行流程详解
WordCount执行过程中一共生成6个 RDD,2个Stage(一次shuffle),task取决于分区数量
注意点:
1. textFile方法生成两个RDD,一个为HadoopRDD,一个为内部调用map方法产生的MapParitionsRDD
2. 切分Stage的方法为区分宽窄依赖,shuffle次数等于宽依赖次数
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
WordCount执行流程:
DAG可视化:可视化:
2.统计最受欢迎老师统计最受欢迎老师topN
数据描述:
数据格式为以下类型:http://学科.edu360.cn/老师
http://bigdata.edu360.cn/laozhang
http://bigdata.edu360.cn/laozhang
http://bigdata.edu360.cn/laozhao
http://bigdata.edu360.cn/laozhao
http://javaee.edu360.cn/xiaoxu
http://javaee.edu360.cn/laoyang
1. 方法一:普通方法,不设置分组方法一:普通方法,不设置分组/分区分区
//创建spark配置,设置应用程序名字
val conf=new SparkConf().setAppName("ScalaWordCount").setMaster("local[4]")
下载后可阅读完整内容,剩余4页未读,立即下载
2020-07-26 上传
2018-01-18 上传
2021-05-26 上传
2018-10-29 上传
2018-08-20 上传
2021-05-09 上传
2021-05-26 上传
2020-08-25 上传
2021-03-28 上传

weixin_38709379
- 粉丝: 3
- 资源: 954
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
