Apache Kafka:实时数据处理的高性能消息系统指南
需积分: 10 138 浏览量
更新于2024-07-17
收藏 695KB DOCX 举报
Apache Kafka 是一个强大的开源分布式消息传递系统,由LinkedIn于2011年开发并开源,随后于2012年进入Apache软件基金会的Incubator阶段并毕业。Kafka的设计目标是为实时数据处理提供一个高效、低延迟且高吞吐量的平台,特别适合于大规模的数据流处理和日志收集。
Kafka的核心组件包括生产者(Producer)、主题(Topic)和消费者(Consumer),以及Zookeeper集群用于存储元数据以确保系统的可用性和一致性。生产者负责将数据发布到指定的主题,而消费者则订阅这些主题并接收消息。每个Kafka节点(Broker)是消息的存储和分发中心,它们共同构成了Kafka集群。
消息队列在系统中的关键作用体现在三个方面:解耦、异步处理和并行执行。例如,在用户注册过程中,通过消息队列可以避免单点瓶颈,提高系统响应速度。当后端流程复杂时,使用消息队列可以使各步骤并行处理,即使某个步骤失败,也不会影响整体服务。同时,通过最终一致性保证,主要流程完成后,消息会被发送到目的地,其他系统通过消费数据来完成后续操作。
Kafka与传统的消息系统如RabbitMQ相比,有着显著的区别。RabbitMQ基于AMQP协议,其架构以broker为中心,消息路由和确认机制通过Exchange、Binding和Queue实现。消费者从队列中被动拉取消息,形成长连接。相比之下,Kafka更倾向于消费者为中心,消息消费信息保存在客户端的消费者上,消费者主动拉取消息,这使得Kafka在处理大规模实时数据时更为高效。
Kafka的设计决策如分区(Partition)、复制(Replication)、压缩(Compression)等特性,使其在高吞吐量和容错性方面表现出色。另外,Kafka还支持多种消息格式和消费者群组模型,这使得它在不同的应用场景下都能发挥出色性能。
总结来说,Apache Kafka作为一款重要的分布式消息中间件,其设计思想和架构模式使得它在实时数据处理和大型分布式系统中扮演着至关重要的角色,与传统消息系统有着显著的性能优势和应用场景适应性。通过深入了解Kafka的工作原理和使用方法,开发者可以更好地利用它来构建可扩展、高效的消息驱动系统。

:每个 实例
:依赖集群保存 信息。
Topics 组件介绍
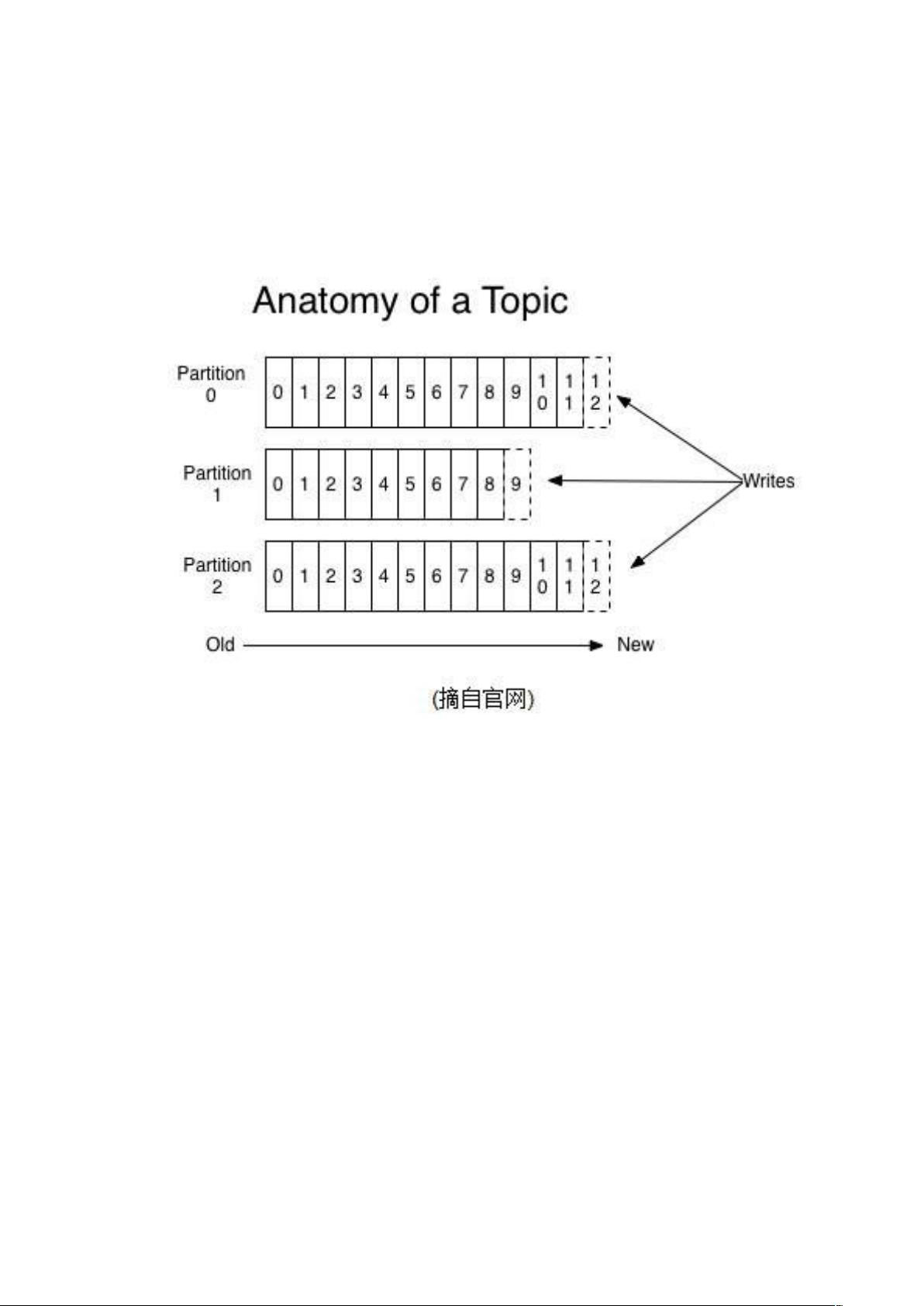
:一类消息,每个 将被分成多个 区,在集
群的配置文件中配置。
: 在 存 储 层 面 是 逻 辑 文 件 , 包 含 多 个
文件。
:消息存储的真实文件,会不断生成新的。
:每条消息在文件中的位置(偏移量)。 为一个
型数字,它是唯一标记一条消息。
paron
、 在存储层面是逻辑 文件,每个 有多个
组成。
、 任何发布到此 的消息都会被直接追加到 文件
的尾部。
、 每个 在内存中对应一个 ! 列表,记录每个
中的第一条消息偏移。这样查找消息的时候,先在
! 列表中定位消息位置,再读取文件,速度块。
"、 发布者发到某个 的消息会被均匀的分布到多个
剩余38页未读,继续阅读
2020-09-22 上传
2017-09-07 上传
2018-06-27 上传
2017-02-07 上传
2022-05-05 上传

guojing2199
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







