解决拉链表重复跑数据错误的策略
需积分: 10 159 浏览量
更新于2024-08-11
收藏 276KB DOCX 举报
"拉链表重复跑数据错误解决"
在大数据处理中,Hive是一个常用的分布式数据仓库工具,常用于处理大规模的数据集。本问题聚焦于Hive中的拉链表(Zigzag Join或Zipping)在处理数据时遇到的重复跑数据错误。拉链表是一种特殊的表,它用于存储一个时间段内数据的变化历史,通常用于跟踪用户或实体的状态变化。在错误描述中,当同一天的数据被多次运行时,会导致dwd_dim_user_info_his表中的历史数据被错误地更新。
以下是针对这个问题的三个解决方案:
**方案一:**
问题在于拉链表在更新数据时,没有正确地处理当前日期与历史日期的关系。原始HQL可能使用了小于目标日期的条件,这将导致多次跑同一天数据时,历史数据被无差别更新。解决方法是,在每次运行目标日期的数据时,只选取非当前日期以前的数据。然而,这种方法对于重跑历史数据并不适用,因为它会丢失目标日期之后的所有数据。为了处理历史数据的重跑,需要从目标日期一直运行到最新日期。
**方案二:**
这个方案提出了一个新的HQL结构,通过在插入时使用`INSERT OVERWRITE TABLE`并结合`UNION`操作来避免重复。在这个方案中,首先选取目标日期的ODS层数据,然后通过`LEFT JOIN`与现有的dwd_dim_user_info_his表进行合并。关键改进是在结束日期的计算上添加了一个判断条件,避免了使用`UNION ALL`可能导致的重复。通过这种方式,可以确保只有新的或更新的数据被写入到临时表中,然后再将临时表的数据写入目标表。
**方案三:**
虽然没有提供完整的HQL,但这个问题的解决方案可能是基于对MySQL的事务或者时间戳的使用。在MySQL中,可以通过开启事务来确保数据的一致性,或者利用每条记录的时间戳字段来判断和处理最新的数据。当更新拉链表时,可以比较当前记录的时间戳和已存在的记录,仅更新时间戳较新的记录。这种方法同样适用于Hive,但需要注意的是,Hive不支持事务,所以可能需要在ETL过程中模拟事务行为,例如在每个步骤后检查和验证数据的完整性。
处理拉链表重复跑数据错误的关键在于如何正确地处理历史数据的更新和维护数据的完整性。无论是通过限制查询条件、使用`INSERT OVERWRITE`配合条件判断,还是借助事务和时间戳,都需要确保在更新历史记录时不会覆盖或丢失已有的有效信息。在设计ETL流程时,应充分考虑到数据的幂等性,即多次执行相同的操作应该得到相同的结果,以防止因重复跑数据而导致的错误。
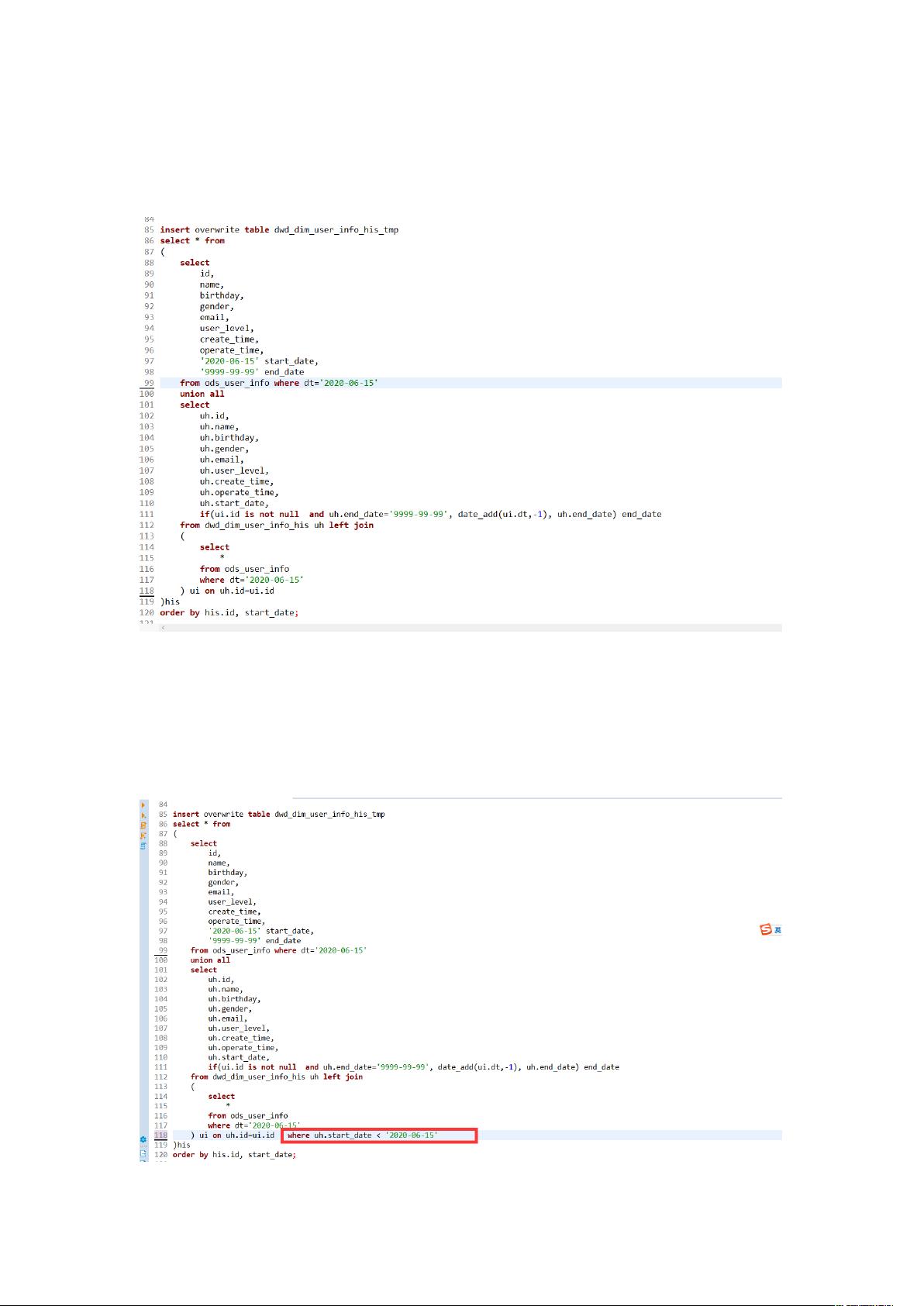
方案一:
问题:拉链表重复跑某一天数据错误
原始 :
数据错误原因:
多次跑同一天数据, 表中当天数据会被当做历史数据无差别更新
解决思路:
每次跑目标日数据时, 表中数据只取非当前日期以前数据
下载后可阅读完整内容,剩余4页未读,立即下载
2024-09-05 上传
2022-06-22 上传
2022-07-12 上传

昊天249
- 粉丝: 2
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
