CentOS 7上Hadoop 2.7.2全分布集群部署教程
需积分: 18 109 浏览量
更新于2024-06-30
收藏 2.08MB DOCX 举报
本文是一份关于在虚拟机环境中进行Hadoop大数据平台完整安装与配置的详细指南,适用于计算机科学与技术专业,特别是软工2001班的学生。作者以软工2001班的学号2000770063,姓名陶心理,为实验报告作者,课程背景是大数据原理与实践。
首先,实验环境设定在PC上使用VMware Workstation Pro,操作系统为CentOS 7,配合Oracle JDK 1.8.0_144版本,Hadoop选用的是2.7.2版本。实验目标旨在帮助学习者深入理解并掌握关键技能,如Linux基础操作(如基本命令、vim编辑器),Java的安装和环境变量配置,以及SSH免密登录的配置。
在实验内容部分,主要包括以下几点:
1. **Linux基础**:通过实际操作,学生将学会使用Linux的各种基础命令,这对于理解和管理Hadoop集群至关重要。
2. **Vim编辑器**:作为常用的文本编辑器,vim的掌握能提高编写配置文件的效率。
3. **Java**:安装Java并配置环境变量,因为Hadoop是基于Java的分布式计算框架,熟悉Java是构建Hadoop集群的基础。
4. **SSH参数**:SSH(Secure Shell)是远程登录工具,通过配置免密登录,可以方便地在不同节点间进行交互,提升运维效率。
5. **Hadoop部署**:核心环节,学生将学习如何在Linux环境中部署全分布模式的Hadoop集群,包括主节点和从节点的设置,以及Hadoop配置文件的调整。
实验步骤详细到实际操作,例如在母机(Alan_Amy)上克隆虚拟机,并配置静态IP地址,修改网络配置,确保网络连接稳定。此外,还涉及Java命令的执行,以及Hadoop的安装和启动过程,包括Hadoop守护进程的启动、配置文件的检查和调整等。
这个实验不仅教授理论知识,还注重实践经验,使学生能够在实际操作中掌握Hadoop的大数据处理流程,为后续数据分析和分布式系统开发打下坚实基础。通过这份详尽的报告,无论是在校大学生还是职场进修者,都能获得宝贵的学习资源。
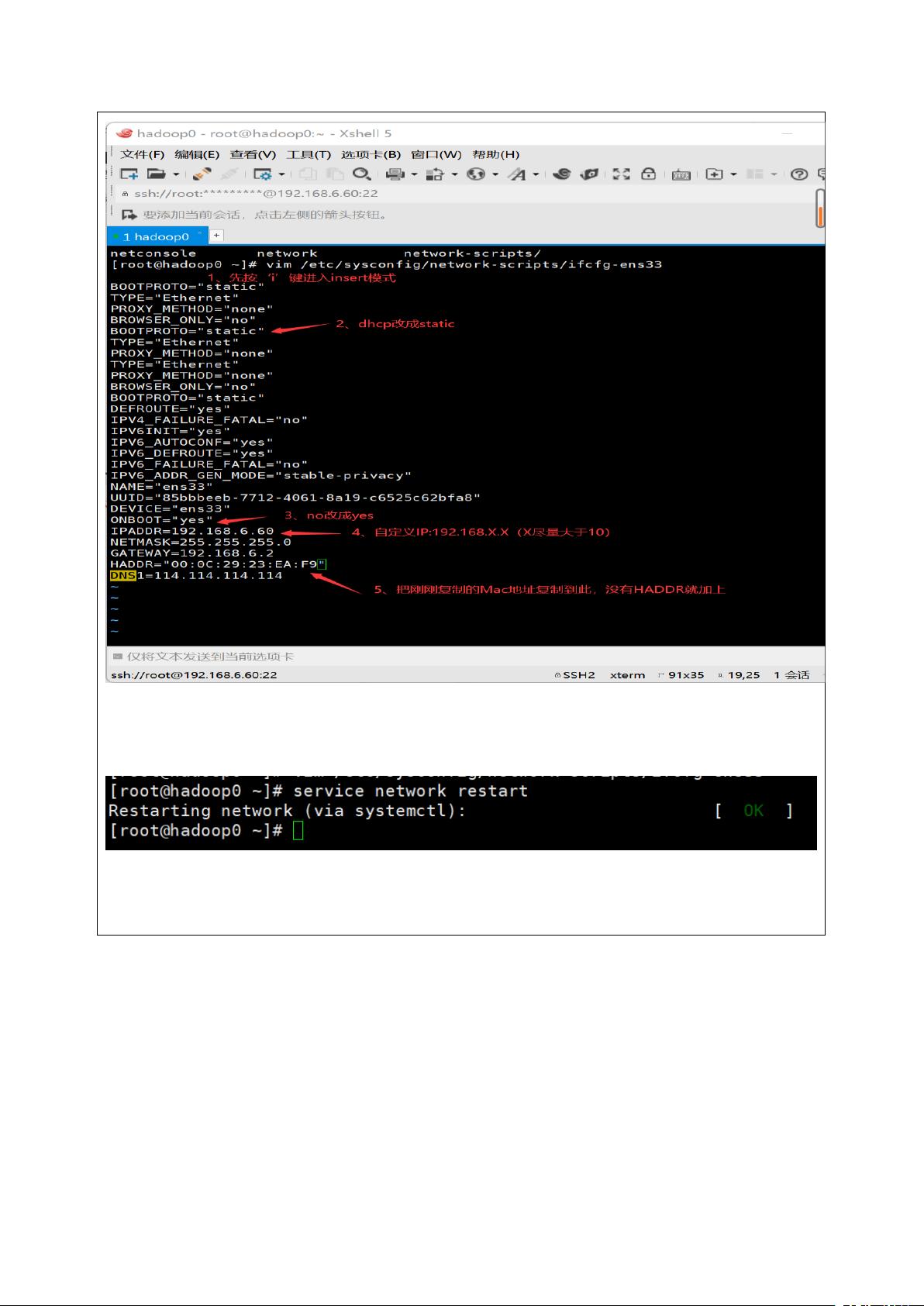
3)重启网络服务
Service network restart
4)检测 IP 是否成功
ip addr
剩余19页未读,继续阅读
684 浏览量
149 浏览量
439 浏览量
301 浏览量
2021-10-14 上传


重生之我是程序猿
- 粉丝: 16
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM配置文件整理.zip
- Reference-Design-Terms-of-Use-教程与笔记习题
- 精美鱼骨结构图图表下载PPT模板
- CapstoneWebsiteV2:Capstone网站的V2
- Ajax-wikipedia-viewer.zip
- marvel-jarvig:Marvel JARVIG(一个非常有趣的游戏)是一款游戏,可让您根据角色的名称,图像和描述来查找和发现Marvel Comics角色!
- 猜测数字mollyons:GitHub Classroom创建的猜测数字mollyons
- FreeCAD-0.18.4.zip
- 示例-github-actions
- vehicle-signout:实时网络应用程序,用于管理共享车辆的登出。 内置Angular和Firebase
- 5张精美立体的SWOT并列关系图表PPT模板
- A星八数码/广度优先/深度优先/粒子群寻优算法/遗传算法/蚁群算法/BP神经网络/卷积神经网络
- halma-ai:具有AI播放器的Halma游戏,移动验证和动态棋盘尺寸
- Ajax-Giffy-Gallery.zip
- 你好
- 天野学院OD.rar
