Ubuntu 14.04上编译Spark以支持Hive on Spark (1.4.0版)的实施教程
需积分: 0 106 浏览量
更新于2024-08-04
收藏 270KB DOCX 举报
本文档是关于在Ubuntu 14.04操作系统环境下,针对Hive on Spark实施过程中遇到的问题进行的编译和配置指南。主要关注点在于如何解决Spark与Hive之间的jar包冲突,以确保Spark可以支持从Hive中读取数据。
首先,文章强调了在编译Spark时需要的环境设置,包括使用Maven作为构建工具,Scala语言(版本2.11.7),以及Hadoop 2.6作为基础框架。由于Spark对Scala的依赖,编译时网络连接是必需的,以便下载Scala的最新nightly版本。此外,作者推荐使用国内的Maven镜像以提高下载速度并减少网络延迟,这一步骤对于大规模的编译过程非常重要,可以显著缩短时间。
其次,文章建议选择较稳定的Spark版本1.4.0进行编译,因为可能存在Hive不兼容新版本Spark的情况,并且这个版本在社区中已经得到广泛验证。编译步骤包括下载源码、执行编译命令,最后生成编译后的结果文件。
安装阶段,编译好的Spark包会被复制到集群节点,并进行解压,然后配置环境变量SQOOP_HOME,确保bin目录被添加到系统的PATH中,这样所有节点都能访问Spark服务。
配置方面,涉及到的主要文件包括`conf/spark-env.sh`(用于环境变量配置)、`conf/spark-defaults.conf`(Spark默认配置)、`conf/slaves`(定义集群节点列表),以及`conf/log4j.properties`(用于调整日志级别)。启动集群服务通常通过`/sbin/start-all.sh`命令,如果启动失败,可能是编译或配置存在问题。
HiveOnSpark的集成是在Hive启动时自动检测Spark环境变量SPARK_HOME的,只要正确配置,Hive就能利用Spark的功能。启动后,可以通过webUI查看Spark Master的URL,这有助于监控和管理Spark集群。
最后,整个过程的运行环境依赖于Java 1.7、Hadoop 2.6和Hive 1.2.1。总结来说,本文提供了一个详细的步骤指导,帮助用户在特定环境中成功地将Hive与Spark集成,以满足大数据处理的需求。
Hive on Spark 实施笔记
一、 编译适合 Hive 的 Spark
a) 说明
Spark 为了支持从 Hive 中读取数据,所以有很多 Hive 中用到的 jar 包,而 Hive
中 Hive on spark 时会将 Spark 的 jar 包引入到 Hive 的运行环境,因此及其他原因会
有 jar 冲突。所以需要重新编译没有包含 Hive 相关模块的 Spark。
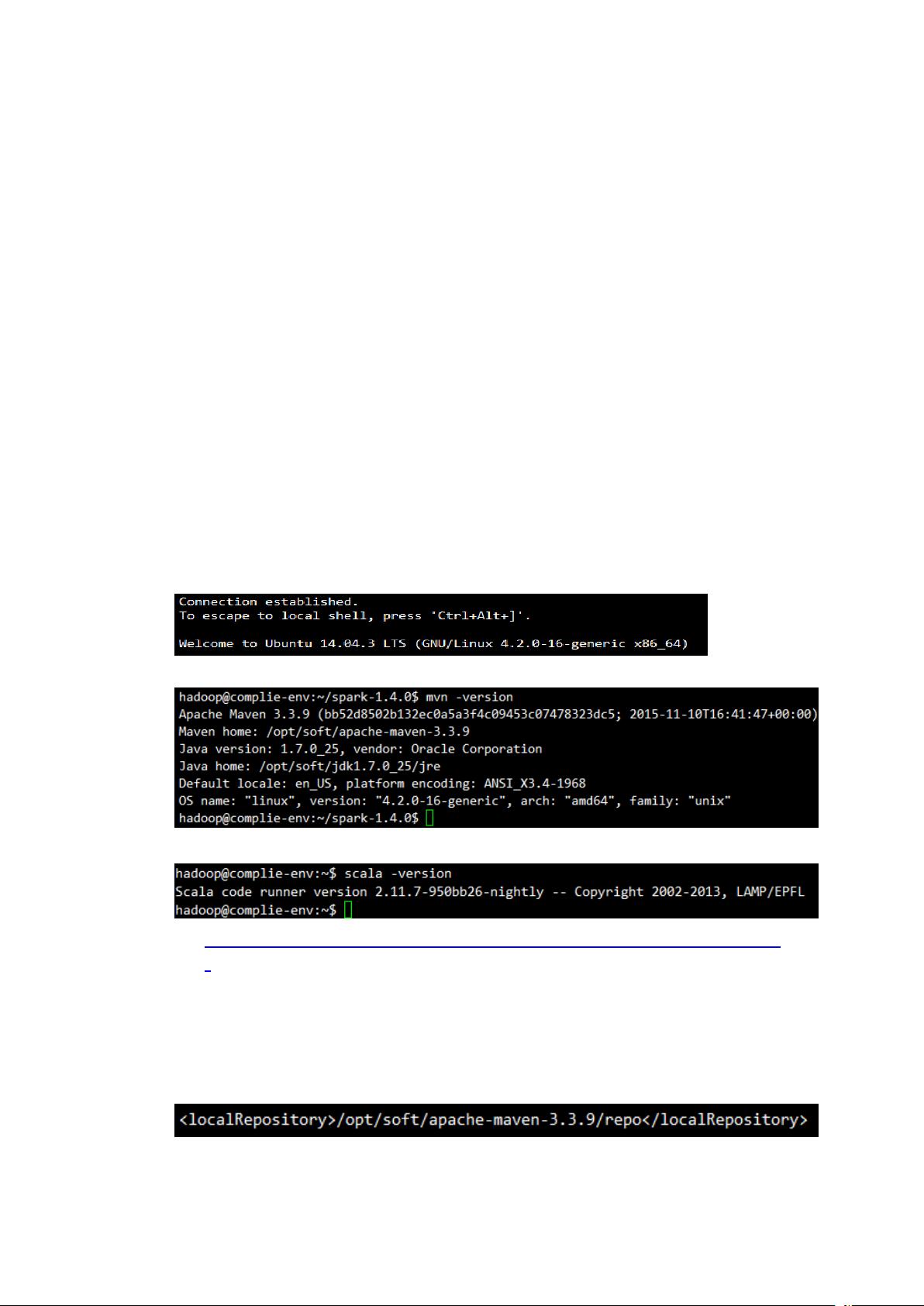
b) 编译环境
1. OS – Ubuntu 14.04
2. Maven
3. Scala (Spark 编译时有用到)
http://www.scala-lang.org/files/archive/nightly/2.11.x/scala-2.11.7-950bb26-nightly.tg
z
4. Hadoop2.6(已引入 HADOOP_HOME 环境变量)
5. 可访问外网(编译过程要联网下载)
6. 配置 maven 的国内镜像(编译过程会从国外下载较多文件,改国内 maven 库
镜像后编译过程大约需要 1 小时)
设置本地库路径:
镜像:
下载后可阅读完整内容,剩余4页未读,立即下载
2021-01-07 上传
2019-03-01 上传
2021-02-24 上传
2021-02-23 上传
2022-08-08 上传
2024-06-23 上传
点击了解资源详情
2023-03-16 上传

晕过前方
- 粉丝: 983
- 资源: 328
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全国江河水系图层shp文件包下载
- 点云二值化测试数据集的详细解读
- JDiskCat:跨平台开源磁盘目录工具
- 加密FS模块:实现动态文件加密的Node.js包
- 宠物小精灵记忆配对游戏:强化你的命名记忆
- React入门教程:创建React应用与脚本使用指南
- Linux和Unix文件标记解决方案:贝岭的matlab代码
- Unity射击游戏UI套件:支持C#与多种屏幕布局
- MapboxGL Draw自定义模式:高效切割多边形方法
- C语言课程设计:计算机程序编辑语言的应用与优势
- 吴恩达课程手写实现Python优化器和网络模型
- PFT_2019项目:ft_printf测试器的新版测试规范
- MySQL数据库备份Shell脚本使用指南
- Ohbug扩展实现屏幕录像功能
- Ember CLI 插件:ember-cli-i18n-lazy-lookup 实现高效国际化
- Wireshark网络调试工具:中文支持的网口发包与分析
