深度学习在计算机视觉中的突破:方法解析、因果探讨与公平挑战
需积分: 39 200 浏览量
更新于2024-07-09
收藏 1.07MB PDF 举报
本文深入探讨了计算机视觉领域中深度学习的关键要素,从方法论到实际应用及其潜在问题。首先,深度学习的核心是其深度架构,它能够将复杂的视觉任务分解为一系列逐步抽象的处理步骤,如卷积神经网络(CNN)中的特征提取和池化层。这种分层结构使得模型能够自动学习到输入图像中的底层特征和高级模式,从而实现高精度的识别和分类。
其次,标准梯度下降优化算法在非凸损失函数中的表现是深度学习成功的关键。通过迭代调整权重参数 W,模型能够在局部最小化误差的同时,逐渐逼近全局最优解。特别是在GPU等并行计算硬件的支持下,大规模数据集上的训练得以高效进行,促进了计算机视觉技术的发展。
然而,深度学习并非完美无缺。它面临的问题包括缺乏可解释性,即我们难以理解模型内部是如何做决策的,这在医疗诊断等关键领域可能带来风险。此外,深度模型可能会捕获并放大训练数据中的偏见,导致不公平的结果。例如,在人脸识别或招聘决策中,如果训练数据存在性别、种族等方面的偏差,模型可能会无意中复制这些偏见。
为了提高深度学习的透明度和公平性,研究人员正在探索生成模型(如生成对抗网络GANs)用于解释模型决策,以及因果推理方法来分析输入(X)与输出(y)之间的因果关系。此外,公平性研究关注的是如何设计和实施策略,确保模型在处理不同群体时能避免歧视和偏见。
计算机视觉中的深度学习是一个既充满机遇又具有挑战的领域。尽管其强大的表现在许多任务中取得了显著成就,但理解和解决其中的解释性、因果性和公平性问题,是推动这一技术向前发展的重要课题。未来的研究将继续关注模型的可解释性增强、公平性保障以及在复杂环境下的稳健性能提升。
6
pushes the neural network output
(
)
;
towards 1 and therefore its log towards the maximum value 0.
Similarly, when
()
= 0, the neural network output is similarly pushed towards 0.
()
=
(
)
;
,
()
=
(
)
log
(
)
;
(1
(
)
) log 1
(
)
;
(6)
We need the derivatives of this loss function with respect to the parameters . The derivative represents
the sensitivity of the output with respect to a single parameter. The parameter
is iteratively updated directly
in proportion to this derivative until the gradient descends to zero. At a gradient of zero, we intuitively expect
the cost function to be at a local minima with respect to the focal parameter
. As shown below, the derivative
is quite straightforward for a single neuron.
=
+
;
=
()
()
=
,
(
)
;
;
(
)
;
=
(
,
)
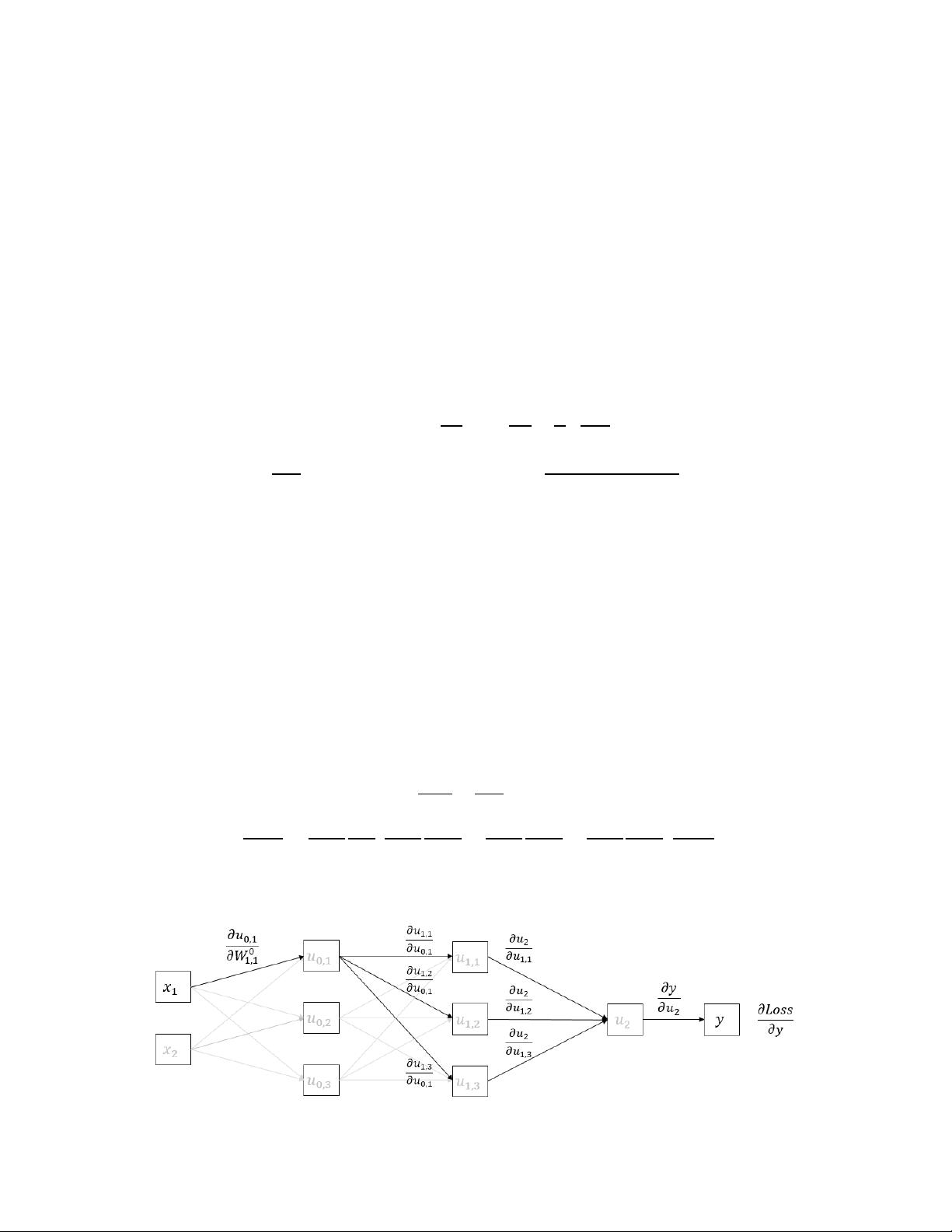
Unlike a single neuron above, calculating the derivatives of the loss function with respect to the neuron
parameters is somewhat nontrivial in deep networks. The output of the last layer
does not hint at a tractable
form for the parameter gradients at layer . The derivative for a parameter in layer requires accounting for
derivatives with all neurons in layer + 1, since each parameter on layer contributes to all neurons on layer
+ 1 (Figure 3). The backpropagation algorithm [46] makes deep network training tractable by iteratively
applying the chain rule. Fortunately, the application of the chain rule on parameter
,
(paramter of neuron
in layer ) simplifies to depend only on the derivative of the loss with the layer output
and the
corresponding layer input
[28].
()
,
=
()
()
,
=
(
)
y
y
u
(
u
u
,
u
,
u
,
+
u
u
,
u
,
u
,
+
u
u
,
u
,
u
,
)
u
,
W
,
(7)
Electronic copy available at: https://ssrn.com/abstract=3395476

剩余31页未读,继续阅读
2346 浏览量
909 浏览量
223 浏览量
2021-06-10 上传
2021-05-19 上传
171 浏览量
128 浏览量
108 浏览量
2021-06-10 上传

weixin_38651445
- 粉丝: 7
 我的内容管理
展开
我的内容管理
展开







最新资源
- VB通过Modbus协议控制三菱PLC通讯实操指南
- simfinapi:R语言中简化SimFin数据获取与分析的包
- LabVIEW温度控制上位机程序开发指南
- 西门子工业网络通信实例解析与CP243-1应用
- 清华紫光全能王V9.1软件深度体验与功能解析
- VB实现Access数据库数据同步操作指南
- VB实现MSChart绘制实时监控曲线
- VC6.0通过实例深入访问Excel文件技巧
- 自动机可视化工具:编程语言与正则表达式的图形化解释
- 赛义德·莫比尼:揭秘其开创性技术成果
- 微信小程序开发教程:如何实现模仿ofo共享单车应用
- TrueTable在Windows10 64位及CAD2007中的完美适配
- 图解Win7搭建IIS7+PHP+MySQL+phpMyAdmin教程
- C#与LabVIEW联合采集NI设备的电压电流信号并创建Excel文件
- LP1800-3最小系统官方资料压缩包
- Linksys WUSB54GG无线网卡驱动程序下载指南
