SparkSQL在ETL中的应用与优势
需积分: 18 149 浏览量
更新于2024-07-18
收藏 4.3MB PDF 举报
"这份文档主要介绍了SparkSQL在ETL(数据抽取、转换、加载)过程中的应用,作者是嵩林,来自阿⾥里云E-MapReduce团队,有丰富的数据开发经验,包括Spark和HBase相关的开发。文档内容涵盖了SparkSQL的基本概念、特性、数据源支持以及性能优势,并且讨论了在云环境中的ETL工作流程。"
SparkSQL是Apache Spark的一个重要组件,它允许开发者使用SQL或者DataFrame/DataSet API进行数据处理。在ETL过程中,SparkSQL扮演了关键角色,提供了高效的数据处理能力。
1. 数据源(DataSource):SparkSQL支持多种数据源,包括但不限于jdbc、json、csv、text、orc、parquet、hive、avro、redshift、mongodb、cassandra和elasticsearch等。这使得它能够方便地从各种不同的数据存储中读取和写入数据,极大地扩展了其在实际项目中的适用性。同时,SparkSQL还允许自定义数据源,通过Spark Packages平台可以找到许多社区贡献的额外数据源实现。
2. 丰富的算子(Operators):SparkSQL提供了丰富的算子集,包括过滤(filter)、映射(map)等操作,方便进行数据清洗、加工和整合。这些算子使得SparkSQL能够处理复杂的业务逻辑,同时也保持了与传统SQL的兼容性,降低了学习成本。
3. Hive兼容:SparkSQL与Hive有很好的兼容性,可以直接读取和写入Hive表,这对于已经使用Hive作为数据仓库的组织来说是一个巨大的优势。这意味着可以无缝地集成到现有的Hadoop生态系统中,而无需重新编写大量代码。
4. 性能:SparkSQL基于SparkCore,提供了内存计算和DAG执行模型,能够在大规模数据处理时提供高性能。此外,它还支持优化的查询执行计划,如Catalyst优化器,进一步提升了处理效率。
5. 云上ETL:在云环境中,SparkSQL可以利用弹性计算资源,快速扩展处理能力,适应大数据处理的动态需求。通过云服务,如阿⾥里云E-MapReduce,用户可以轻松地部署和管理SparkSQL作业,进行高效的ETL流程。
6. DataFrame/DataSet API:DataFrame和DataSet是SparkSQL引入的新概念,它们提供了更高级别的抽象,简化了数据处理。DataFrame是基于列的数据结构,而DataSet则提供了更强的类型安全性和编译时检查,两者都支持SQL查询,使得开发更加便捷。
7. Structured Streaming:SparkSQL也支持Structured Streaming,这是一种处理连续数据流的API,可以用于实时ETL场景,将批处理和流处理统一在一个简单的API下。
SparkSQL凭借其强大的数据处理能力、丰富的数据源支持、与Hive的兼容性、优秀的性能以及云环境的适应性,成为现代ETL工作流中的首选工具之一。在实际应用中,开发者可以通过SparkSQL实现从数据源的提取,经过各种转换操作,最后将处理后的数据加载到目标存储,从而构建高效的数据管道。
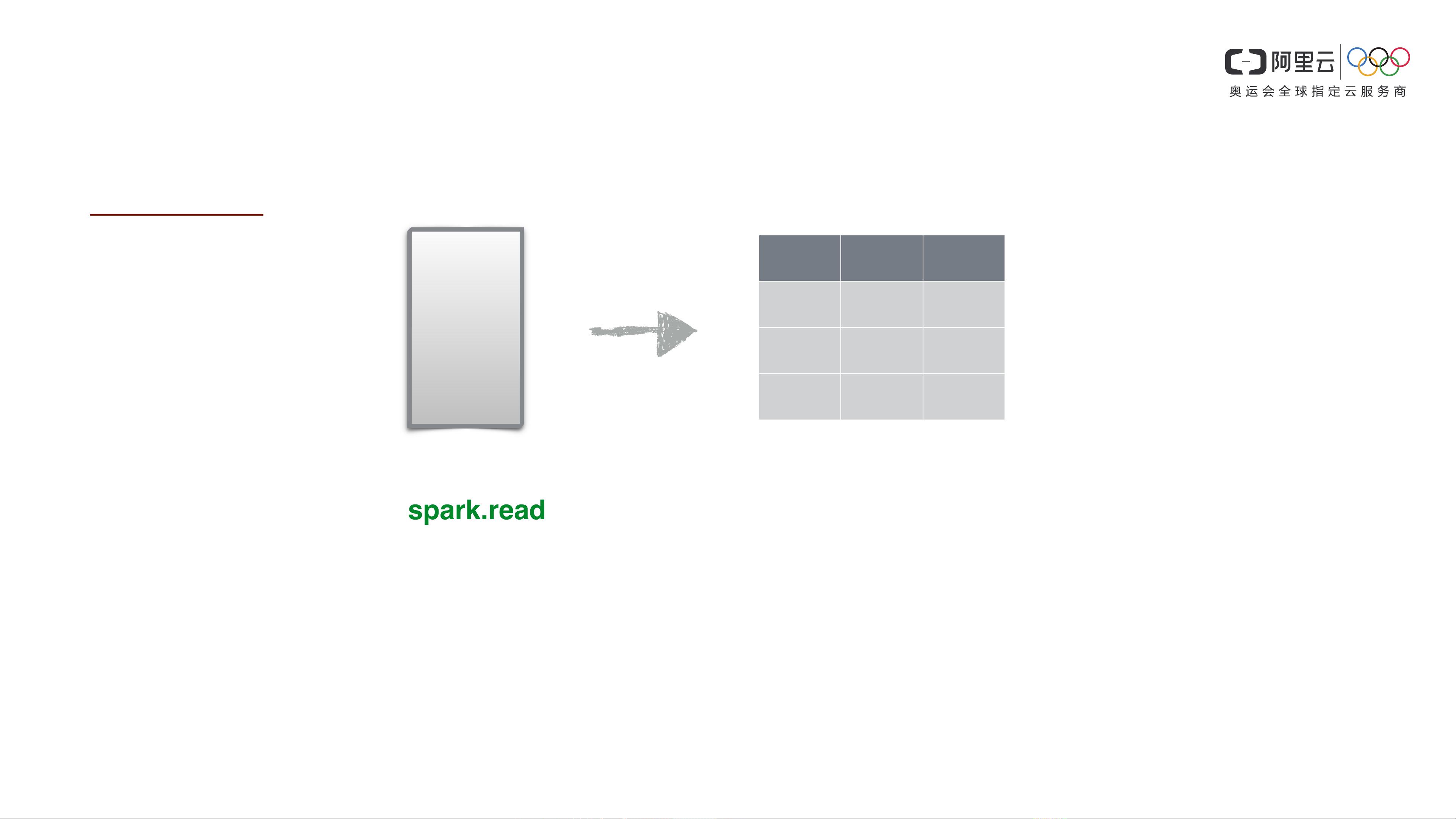
SparkSQL
spark.read
.option("sep","|").option("header","true").csv(''/csv_path'')
.filter(…)
.map(…)
.saveAsTable("t")
a
b
c
1
2
3
4
5
6
7
8
9
a|b|c
1|2|3
4|5|6
7|8|9
Extract
•••••••
Transform
••• • •••• •
Load
••••
Simple ETL
剩余37页未读,继续阅读
2018-01-18 上传
2018-04-04 上传
2018-04-04 上传
2021-10-11 上传
2021-11-13 上传
2020-01-14 上传
2023-07-03 上传
2022-06-04 上传
2014-02-04 上传

Kliners
- 粉丝: 1
- 资源: 33
 我的内容管理
展开
我的内容管理
展开







最新资源
- aqqa水文化学软件
- mybatis-generator-demo:mybatis逆向工程实践
- VC++屏蔽的编辑框 masked edit实例
- (修)10-18b2c电子商务网站用户体验研究——以京东商城为例.zip
- 基于matlab的拉普拉斯滤波实例分析.zip
- easyengine-vagrant:用于测试 Easy Engine 的 Vagrant 文件
- grader:一个用于创建和应用考试和测验的应用程序
- release-pr-test
- 基于matlab的高斯高通滤波实例分析.zip
- 搜索算法:穷举,爬山等
- PowerModels.jl:用于电网优化的JuliaJuMP软件包
- 基于matlab的高斯低通滤波实例分析.zip
- turbo-vim:Vim 支持 Tmux、RubyRails、Rspec、Git 和 RVM
- autodoc_pydantic:将pydantic模型无缝集成到您的Sphinx文档中
- VC++批量删除指定文件完整实例包
- MySQL学习教程.zip
