"分布式数据仓库开发与构建的关键步骤与类型总结"
39 浏览量
更新于2024-01-16
收藏 1.18MB PPTX 举报
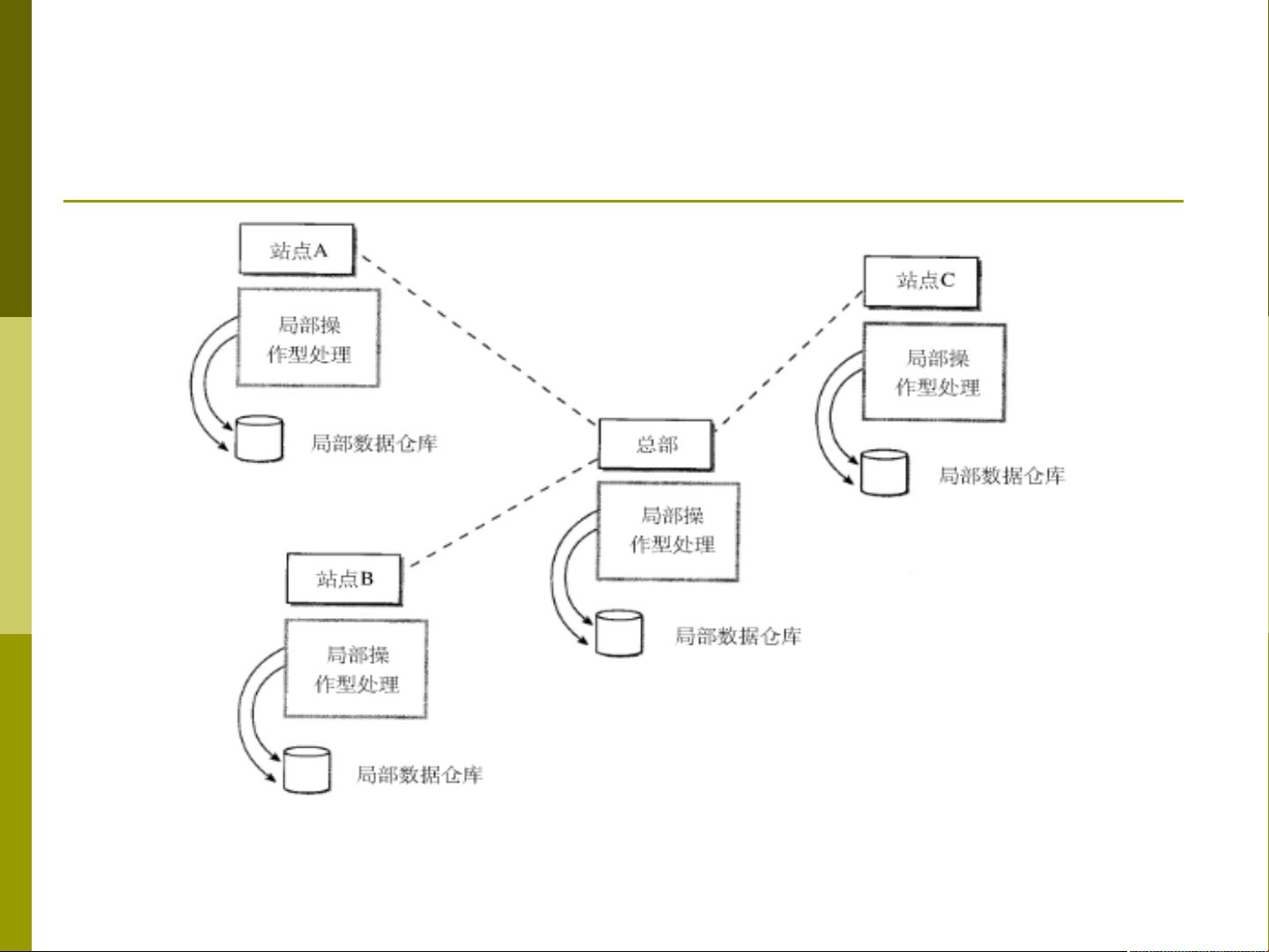
分布式数据仓库是一种能够适应企业遍布不同地域或生产线的需求的数据管理系统。在分布式数据仓库中,可以存在局部数据仓库和全局数据仓库两种类型。
局部数据仓库和全局数据仓库的区别在于数据的范围。局部数据仓库是在远程站点上提供和处理数据的,它主要用于满足某个特定地区或生产线的数据需求。而全局数据仓库是经过整合后的数据,可以为整个企业范围内的所有部门和机构提供数据支持。
当一个企业分布在不同的国家或地区时,就需要考虑建立分布式数据仓库。虽然中心数据仓库可以满足总部对企业信息的需求,但是对于远程分支机构来说,仍然存在建立各自的数据仓库的需求。因为分支机构通常具有特定的需求和业务流程,他们可能需要特定的数据集合和处理方式。而且由于网络通信的限制,远程站点对中心数据仓库的访问可能会有一定的延迟和性能问题,因此建立局部数据仓库能更好地满足他们的需求。
另外,分布式数据仓库还可以根据技术的不同进行分类。技术分布式数据仓库是一种通过网络进行数据共享和协同工作的数据管理系统。它可以实现跨地域、跨网络的数据集成和处理,能够提高企业整体数据管理的效率和灵活性。
独立开发的分布式数据仓库是指企业根据自身的需求和特点,独立进行数据仓库的开发和部署。独立开发的分布式数据仓库通常具有较高的定制化能力,可以根据企业的实际情况进行灵活的数据管理和处理。
在实际开发分布式数据仓库的过程中,需要关注项目的本质特征。开发分布式数据仓库的本质特征包括:数据集成、数据清洗、数据转换和数据加载等。这些特征对于确保数据的质量和一致性非常重要。因此,在开发分布式数据仓库时,需要根据业务需求和数据特点,建立相应的数据集成、清洗、转换和加载的机制和流程。
在构建分布式数据仓库时,可以采用多种层次的方法。多层次的数据仓库可以更好地应对数据的复杂性和不同层次的需求。常见的层次包括:企业级数据仓库、部门级数据仓库、项目级数据仓库等。通过建立多个层次的数据仓库,可以提高数据共享和管理的效率,同时也可以满足不同层次的数据需求。
在实际的分布式数据仓库开发过程中,通常会涉及多个小组的合作。每个小组负责不同的任务和模块,例如数据采集、数据清洗、数据转换等。为了确保数据的一致性和准确性,需要建立良好的沟通和协同工作机制,以保证各个小组之间的数据交流和整合。
在分布式数据仓库中,公共细节数据是非常重要的。为了满足不同需求和平台的数据访问,可以采用多种平台来共享和存储数据,例如云计算平台、大数据平台等。通过使用不同的平台,可以提高数据的可用性和访问效率,同时也可以降低数据管理和维护的成本。
总结来说,分布式数据仓库是一种能够适应企业分布在不同地域或生产线的需求的数据管理系统。它可以通过建立局部数据仓库和全局数据仓库来满足不同层次和需求的数据访问和处理。在实际的开发过程中,需要关注项目的本质特征,并采用多层次的架构和多种平台来构建和管理数据仓库。同时,也需要建立良好的协作机制,以确保数据的一致性和准确性。分布式数据仓库的建设将为企业提供更高效、灵活和可靠的数据管理解决方案,有助于企业在竞争激烈的市场环境中取得竞争优势。

6.1.1 局部数据仓库和全局数据仓库
2.全局数据仓库
局部数据仓库的数据来源于相应的操作型系统,企业全
局数据仓库的数据来源通常是局部数据仓库,有时全局数据
仓库可能直接被更新。

剩余61页未读,继续阅读
2023-03-03 上传
188 浏览量
2021-09-21 上传
2021-09-22 上传
2021-09-22 上传
200 浏览量
382 浏览量

猫一样的女子245
- 粉丝: 232
 我的内容管理
展开
我的内容管理
展开







最新资源
- 揭秘嵌入式Linux性能:深度解析与哲思
- Hibernate开发指南:数据库映射到Pojo的实战教程
- Symbian OS 设计模式全书:智能手机软件基石
- .NET面试必备知识点大全
- 利用CPU时间戳实现高精度计时方法
- Pentium处理器的分支预测策略与优化
- InfoQ中文站:深入浅出Struts2电子书-免费在线学习资源
- CVS并发版本系统中文手册v1.12.9:团队开发必备
- UML初学者教程:实例解析类与关系
- Seam深度集成框架:简化企业级应用开发
- 掌握复杂指针教程:解析与实例
- TestInside 310-065 Java SE 6.0 Programmer题库下载与编程练习
- Java与SAP R/3系统的集成技术探索
- 理解银行家算法:C++实现详解
- C# 3.0编程规范详解:从HelloWorld到结构与接口
- 大规模网络异常检测:滤波与统计方法的融合策略
