Transformer: 基于注意力的高效序列模型
需积分: 0 59 浏览量
更新于2024-08-29
1
收藏 856KB DOCX 举报
《NIPS-2017:注意力即全部你所需》论文是关于自然语言处理(NLP)领域的一项重要突破,由Google Brain团队在NIPS 2017会议上发表。该研究主要关注于一种新颖的网络架构——Transformer,它完全基于自注意力机制,替代了传统的递归和卷积神经网络在序列转导任务中的应用,如机器翻译。
论文的核心思想是,Transformer不再依赖于复杂的编码器-解码器结构中的循环神经网络(RNN)或卷积操作,而是利用了注意力机制来直接在输入和输出序列之间建立关联。自注意力机制允许模型在整个序列中动态地分配权重,关注那些对当前预测最为关键的信息,从而避免了位置编码的固定依赖。这种方法极大地提升了模型的并行性和计算效率,特别是在处理长序列时,以往的递归结构由于序列依赖而难以有效扩展。
在实验部分,作者展示了Transformer在两个主要的机器翻译任务中的出色表现。在WMT2014年的英语-德语翻译任务中,Transformer模型达到了28.4 BLEU分数,相较于当时的最佳结果,这一改进超过了2个BLEU点,显示出其在翻译质量上的显著提升。对于英语到法语的翻译任务,他们开发的模型仅用三个图形处理器在3.5天内就达到了41.0的单模型最高BLEU评分,这在训练成本方面远低于文献中其他最佳模型。
Transformer的成功归功于其简洁的设计和强大的性能,它革新了序列建模领域,使得大规模并行训练成为可能,减少了训练时间和所需的硬件资源。此外,论文还提到了多位作者的贡献,他们在模型设计、实现、优化和评估过程中发挥了关键作用,共同推动了这一革命性的技术发展。
NIPS-2017的《Attention is all you need》论文标志着自然语言处理中自注意力机制的崛起,它不仅改变了我们理解和构建序列模型的方式,也开启了深度学习在序列任务中的新篇章。
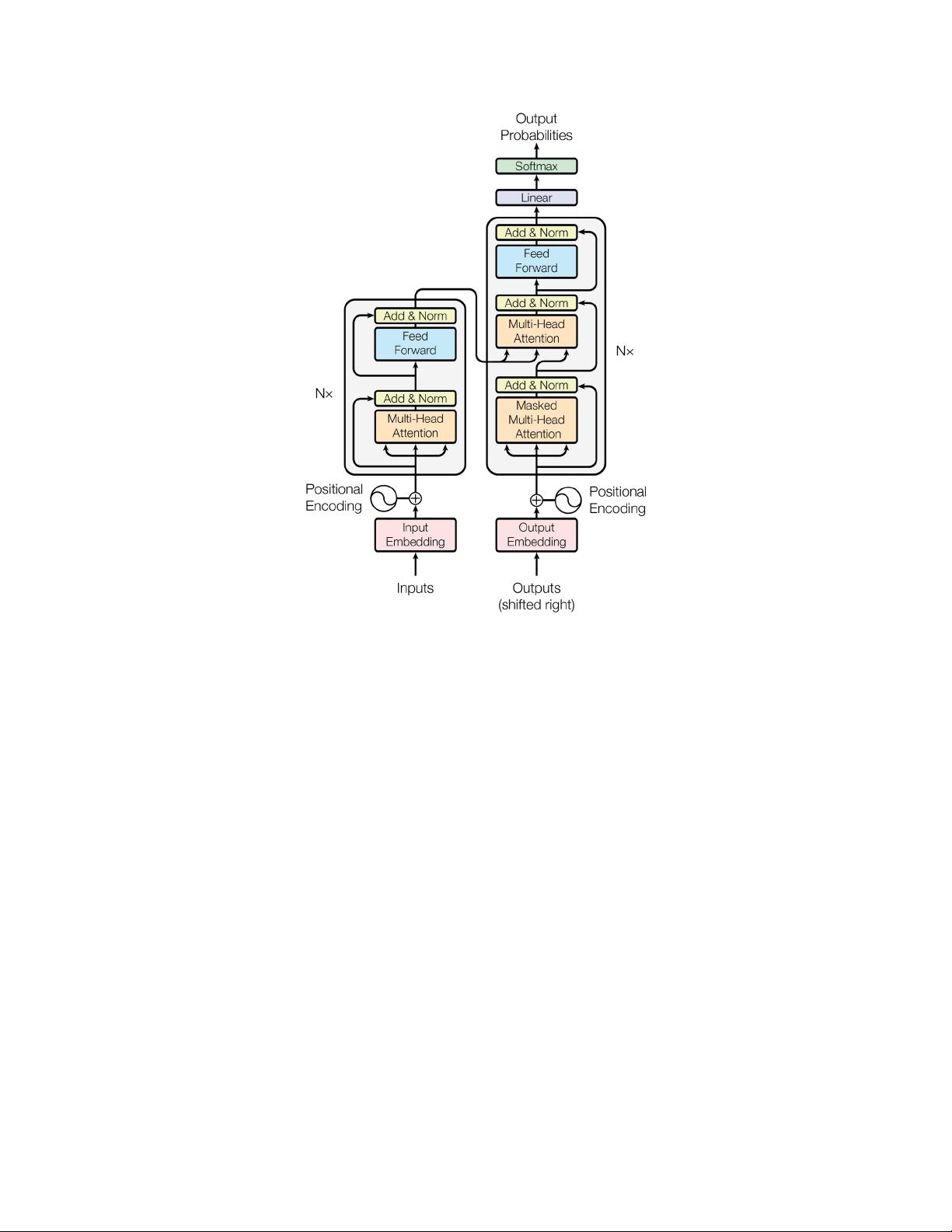
图 %?转换器模型架构。
全连接前馈网络。我们在两个子层的每一个周围使用剩余连接0%$1,接着是层归一化
0%。也就是说,每个子层的输出都是 ;A4!,=B;,=--,其中 ;,=-是子层本身
实现的功能。为了促进这些剩余连接,模型中的所有子层以及嵌入层产生维度 @
/%# 的输出。
解码器?解码器也是由 @8 个相同的层堆叠而成。除了每个编码器层中的两个子层之外,解
码器还插入第三个子层,对编码器堆栈的输出执行多头关注。与编码器类似,我们在每个
子层周围使用剩余连接,然后进行层标准化。我们还修改了解码器堆栈中的自我关注子层 ,
以防止位置关注后续位置。这种掩蔽,加上输出嵌入偏移一个位置的事实,确保了位置 6 的
预测只能依赖于小于 6 的位置处的已知输出。
.# 注意
注意函数可以描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。
输出被计算为值的加权和,其中分配给每个值的权重由查询与相应键的兼容性函数来计算。
.#% 缩放点产品关注度
我们称我们的特别关注为C点积比例关注D,图 #-。输入由维度 的查询和键以及维度 的
值组成。我们计算点积注意力的点积 多头注意力
.
剩余10页未读,继续阅读
1854 浏览量
1693 浏览量
343 浏览量
211 浏览量
2021-04-27 上传
2023-11-22 上传
2009-02-26 上传
143 浏览量


是云小糊糊
- 粉丝: 421
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android实现四区间自定义进度条详解
- MATLAB实现kohonen网络聚类算法分析与应用
- 实现条件加载:掌握webpack-conditional-loader的技巧
- VC++实现的Base64编码解码工具库介绍
- Android高仿滴滴打车软件项目源码解析
- 打造个性JS选项卡导航菜单特效
- Cubemem:基于旧方法的Rubik立方体求解器
- TQ2440 Nand Flash测试程序:读写擦除操作详解
- 跨平台Android apk加密工具发布及使用教程
- Oracle锁对象快速定位与解锁解决方案
- 自动化MacBook维护:Linux下Shell脚本
- JavaEE实现的个人主页与签到管理系统
- 深入探究libsystemd-qt:Qt环境下的Systemd DBus API封装
- JAVA三层架构购物网站设计与Hibernate模块入门指南
- UltimateDefrag3.0汉化版:磁盘整理新体验
- Sigma Phi Delta官方网站:基于Jekyll四十主题的Beta-Nu分会
