Apache Kafka之父剖析:《理解流处理》
需积分: 10 72 浏览量
更新于2024-07-20
收藏 7.68MB PDF 举报
"《理解流处理:Apache Kafka背后的理念与可扩展流数据平台》"
本文由Apache Kafka的创始人撰写,作者Martin Kleppmann在《Making Sense of Stream Processing》一书中深入探讨了分布式流处理技术的哲学理念以及其在实际应用中的关键作用。本书旨在帮助读者理解和掌握这一领域的核心概念,特别是围绕Apache Kafka这一广受欢迎的分布式消息队列系统。
Apache Kafka是一个开源的消息队列平台,它设计用于处理大规模实时数据流,支持高吞吐量、低延迟和持久化的数据传输。其背后的哲学强调了数据的即时性和可靠性,使得它在许多场景中成为实时分析、日志收集、监控和事件驱动架构的理想选择。书中详细阐述了Kafka的设计原则,如分区(partition)、复制(replication)和分发(distribution),这些机制共同确保了系统的可扩展性和容错性。
Kafka的可扩展性体现在其集群模式,通过增加节点数量来轻松处理更大的数据流量,同时通过水平扩展和负载均衡来保持性能。此外,Kafka还提供了强大的事件驱动模型,使得应用程序能够实时响应变化,这对于实时决策和业务流处理至关重要。
除了Apache Kafka本身,书中还涵盖了使用Confluent Platform进行流处理的实践。Confluent Platform是基于Apache Kafka构建的一套企业级解决方案,它包括Kafka、Kafka Connect、Schema Registry等组件,旨在提供更完整的流处理生态,简化开发和运维。
《Making Sense of Stream Processing》不仅深入剖析了技术原理,还提供了丰富的案例研究和最佳实践,帮助读者掌握如何在实际项目中有效地利用Kafka和相关工具。无论是开发人员、数据工程师还是架构师,都能从中找到有价值的洞察和策略,以提升他们团队在处理实时数据流时的效率和效果。
这是一本不可多得的专业书籍,对于理解分布式流处理技术、优化大型数据流应用以及利用Apache Kafka构建实时数据管道具有重要意义。无论是希望深入学习这一领域,还是寻求技术升级的开发者,都应该仔细阅读并掌握其中的知识点。

3 Jim N Gray, Surajit Chaudhuri, Adam Bosworth, et al.: “Data Cube: A Relational
Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals,” Data Min‐
ing and Knowledge Discovery, volume 1, number 1, pages 29–53, March 2007. doi:
10.1023/A:1009726021843
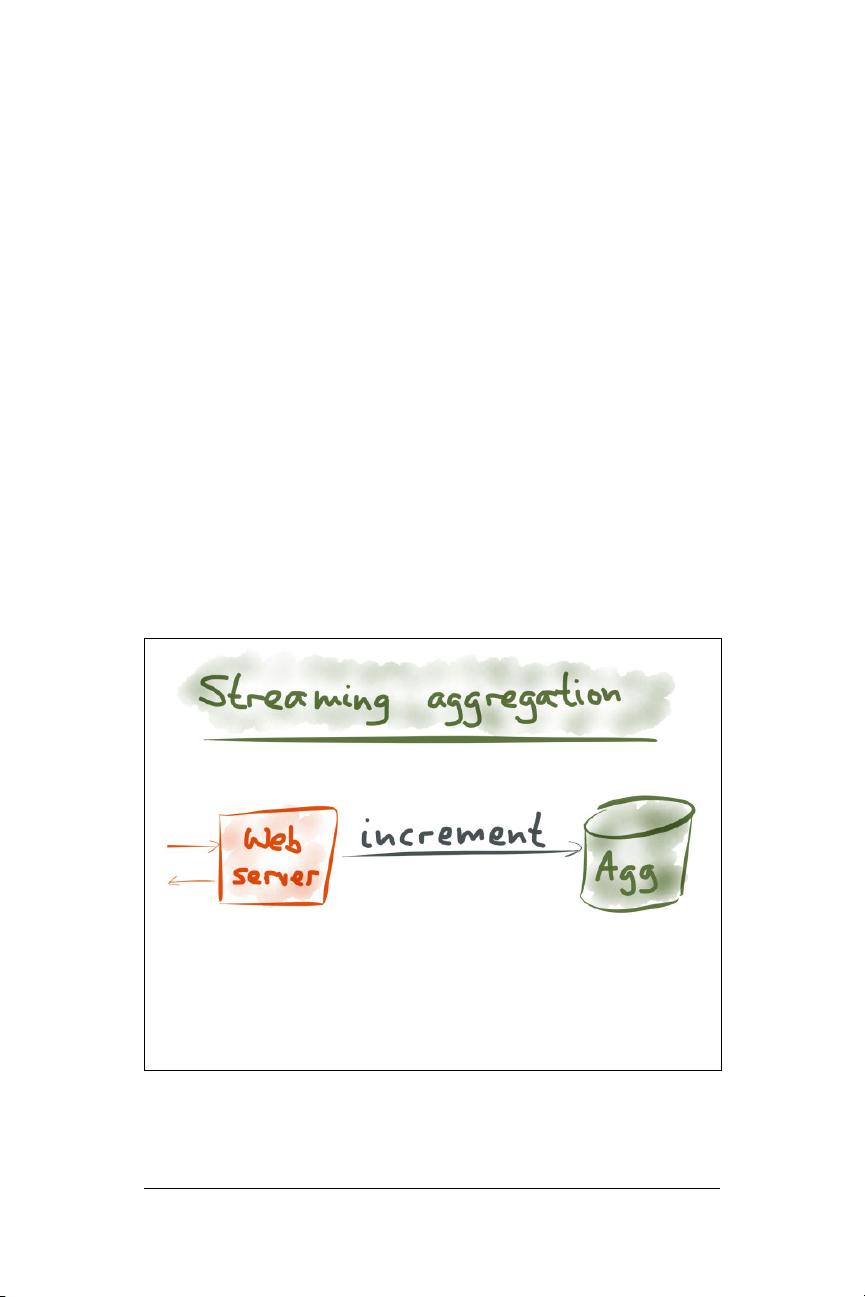
actual event. You might keep several counters in an O
LAP cube:
3
imagine a multidimensional cube for which one dimension is
the URL, another dimension is the time of the event, another
dimension is the browser, and so on. For each event, you just
need to increment the counters for that particular URL, that
particular time, and so on.
With an OLAP cube, when you want to find the number of page
views for a particular URL on a particular day, you just need to read
the counter for that combination of URL and date. You don’t need to
scan over a long list of events—it’s just a matter of reading a single
value.
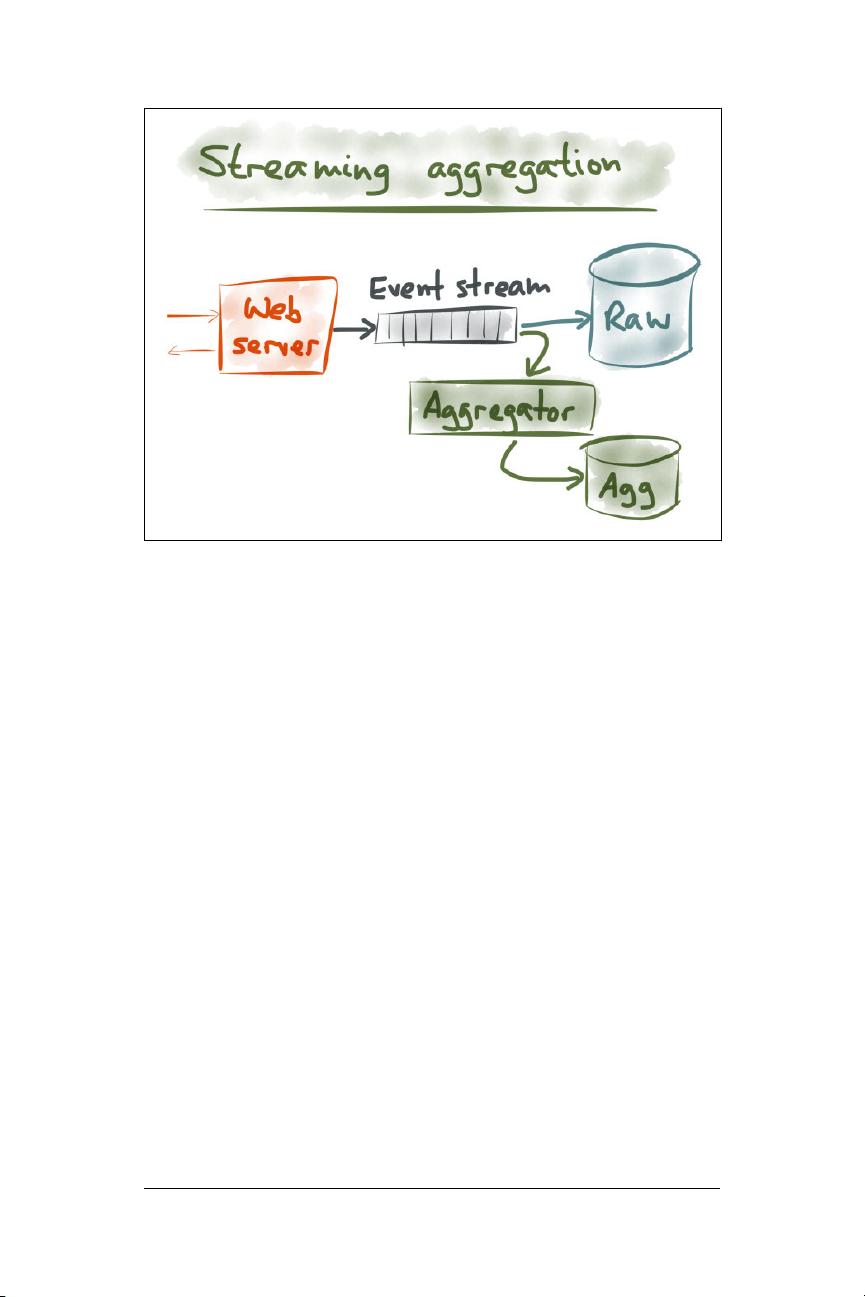
Now, option (a) in Figure 1-5 might sound a bit crazy, but it actually
works surprisingly well. I believe Google Analytics actually does
store the raw events—or at least a large sample of events—and per‐
forms a big scan over those events when you look at the data.
Modern analytic databases have become really good at scanning
quickly over large amounts of data.
6 | Chapter 1: Events and Stream Processing


剩余182页未读,继续阅读
2016-07-01 上传
2021-05-24 上传
2023-03-28 上传
2023-05-20 上传
2023-08-17 上传
2023-05-20 上传
2023-03-29 上传
2023-11-11 上传

tplee923
- 粉丝: 3
- 资源: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- BottleJS快速入门:演示JavaScript依赖注入优势
- vConsole插件使用教程:输出与复制日志文件
- Node.js v12.7.0版本发布 - 适合高性能Web服务器与网络应用
- Android中实现图片的双指和双击缩放功能
- Anum Pinki英语至乌尔都语开源词典:23000词汇会话
- 三菱电机SLIMDIP智能功率模块在变频洗衣机的应用分析
- 用JavaScript实现的剪刀石头布游戏指南
- Node.js v12.22.1版发布 - 跨平台JavaScript环境新选择
- Infix修复发布:探索新的中缀处理方式
- 罕见疾病酶替代疗法药物非临床研究指导原则报告
- Node.js v10.20.0 版本发布,性能卓越的服务器端JavaScript
- hap-java-client:Java实现的HAP客户端库解析
- Shreyas Satish的GitHub博客自动化静态站点技术解析
- vtomole个人博客网站建设与维护经验分享
- MEAN.JS全栈解决方案:打造MongoDB、Express、AngularJS和Node.js应用
- 东南大学网络空间安全学院复试代码解析
