深度学习模型压缩与移动端优化实战
版权申诉
163 浏览量
更新于2024-06-21
收藏 4.07MB PDF 举报
"本资源是一份关于深度学习模型压缩、加速及移动端部署的教程,旨在帮助读者理解如何在有限计算资源下实现深度学习模型的有效应用。教程详细介绍了模型压缩的各种方法,包括网络剪枝、网络蒸馏、低秩分解等,并对比了前端压缩和后端压缩的策略。同时,讲解了TensorRT等模型优化加速工具的工作原理和应用,以及如何通过改变网络结构设计来实现模型的轻量化。此外,还列举了一些常用的轻量级网络结构,如SqueezeNet、MobileNet及其变体、Xception和ShuffleNet-v1,分析了它们的设计思想、网络架构和实验结果。"
深度学习模型压缩和加速是解决资源受限环境下运行复杂模型的关键技术。模型压缩主要是为了减小模型的大小,降低计算复杂度,提高执行效率,而模型加速则侧重于优化模型的运行速度,确保在有限硬件资源上快速执行。
1. **模型压缩理解**:模型压缩主要针对深度学习模型参数过多、计算量大导致的存储和计算需求问题。通过各种技术手段减小模型的体积,而不显著影响其性能。
2. **模型压缩的必要性与可行性**:随着深度学习的发展,模型越来越大,对于内存和计算力的要求越来越高,模型压缩成为在移动设备或边缘计算环境中部署模型的必要选择。通过模型压缩,可以实现在保持预测精度的同时,降低资源消耗。
3. **深度学习模型压缩方法**:
- **前端压缩**:主要通过修改网络结构,如使用更轻量级的卷积层(如GroupConvolution和DepthwiseSeparableConvolution)。
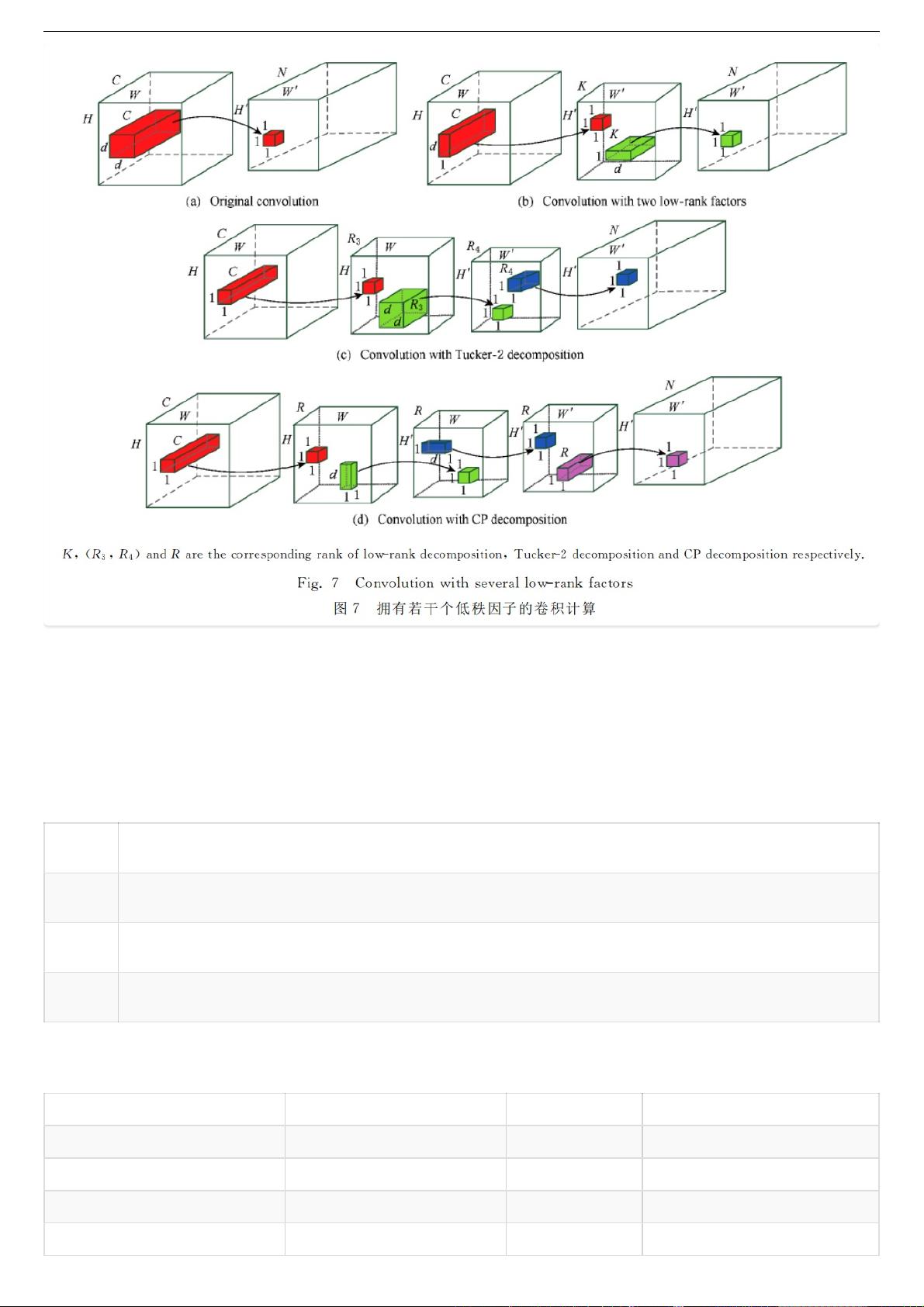
- **后端压缩**:包括网络剪枝,通过移除冗余的神经元或连接,以及低秩分解,将大型矩阵分解为较小的矩阵组合,降低计算复杂度。
- **网络蒸馏**:通过一个大模型(教师模型)指导小模型(学生模型)的学习,保留大模型的预测能力。
4. **影响神经网络速度的因素**:包括模型大小、运算类型(例如FLOPs)、激活函数的选择以及硬件平台的特性等。
5. **模型优化加速方法**:如TensorRT,它通过优化模型的计算图,提供高效的推理性能,支持模型的量化和裁剪,以适应不同的硬件环境。
6. **网络结构设计的改变**:如GroupConvolution和DepthwiseSeparableConvolution可以显著减少计算量,同时保持模型的表达能力。减少网络碎片化(分支数量)和元素级操作也能提升效率。
7. **轻量级网络**:SqueezeNet、MobileNet及其变体MobileNet-v2、Xception和ShuffleNet-v1等网络结构设计,它们通过创新的卷积方式和网络设计,实现了高效率和良好的性能平衡。
8. **选择压缩和加速方法**:应根据具体的应用场景、计算资源和性能要求来决定,通常需要在模型性能和资源消耗之间找到一个合适的权衡点。
9. **未来研究方向**:模型压缩领域的未来研究可能涉及更先进的压缩算法、自动化的模型优化策略以及适用于更多特定任务的轻量级网络设计。
DeepLearning
(出⾃《深度神经⽹络压缩与加速综述》)
17.4.7 总体压缩效果评价指标有哪些?
⽹络压缩评价指标包括运⾏效率、参数压缩率、准确率.与基准模型⽐较衡量性能提升时,可以使⽤提升倍数(speedup)或提升
⽐例(rat io)。
评价指评价指
标标 特点特点
准确率 ⽬前,⼤部分研究⼯作均会测量 Top-1 准确率,只有在 ImageNet 这类⼤型数据集上才会只⽤ Top-5 准确率.为
⽅便⽐较
参数压
缩率
统计⽹络中所有可训练的参数,根据机器浮点精度转换为字节(byte)量纲,通常保留两位有效数字以作近似估计.
运⾏效
率
可以从⽹络所含浮点运算次数(FLOP)、⽹络所含乘法运算次数(MULT S)或随机实验测得的⽹络平均前向传播所
需时间这 3 个⾓度来评价
17.4.8 ⼏种轻量化⽹络结构对⽐
⽹络结构⽹络结构 T OP1 准确率准确率/% 参数量参数量/M CPU运⾏时间运⾏时间/ms
MobileNet V1 70.6 4.2 123
Shuff leNet(1.5) 69.0 2.9 -
Shuff leNet(x2) 70.9 4.4 -
MobileNet V2 71.7 3.4 80
第⼗七章 模型压缩及移动端部署
7/55

剩余57页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-08-23 上传
2023-08-23 上传
2023-08-23 上传
2023-08-23 上传
2023-08-23 上传









