Python爬虫实战:抓取书籍信息示例
需积分: 0 134 浏览量
更新于2024-08-03
收藏 1.19MB DOCX 举报
本资源是一份名为"202118140104张昊宇_人工智能2101班.docx"的文档,该文档似乎与人工智能课程相关,特别是与Python编程中的网络爬虫(Web Scraping)技术相结合。文档展示了如何通过编程实现网络数据抓取和处理,主要涉及以下几个知识点:
1. **Python库使用**:
- `requests`库用于发送HTTP请求获取网页内容。
- `BeautifulSoup`库是用于解析HTML文档的强大工具,这里用于解析抓取到的网页结构。
2. **函数定义**:
- `parse_html(r)`函数:检查HTTP请求状态,如果状态码为200(OK),则使用BeautifulSoup解析HTML,否则打印错误信息并返回None。
- `save_to_csv(booklist, file)`函数:将抓取的书籍信息存储为CSV文件,包括书名、作者、发布时间、网址和价格等字段。
- `save_to_json(booklist, file)`函数:将书籍信息转换为JSON格式,并以指定的编码方式(utf-8)保存到文件中,确保中文字符正常显示。
3. **网络抓取函数**:
- `web_scraping_bot(url)`:主函数,负责发起网络抓取请求,设置合适的User-Agent头以模仿浏览器行为,然后调用`parse_html()`解析网页。抓取的网页链接以变量`url`为参数,示例中未给出具体URL。
4. **网页元素提取**:
- 使用`soup.find_all('tag_b')`来定位HTML中的特定标签('tag_b'未在提供的代码片段中明确指出,可能是某个包含书籍信息的标签,如`<a>`或`<div>`等)。
这部分代码展示了在人工智能课程背景下,如何利用Python的基础库(requests, BeautifulSoup)进行网页数据的抓取和数据结构的转换(CSV和JSON)。学生张昊宇可能在学习如何通过网络爬虫技术从指定的中文书籍网站抓取数据,以便于后续分析或数据可视化。这个实践项目有助于理解HTTP请求、HTML解析以及数据格式转换在实际应用中的作用。
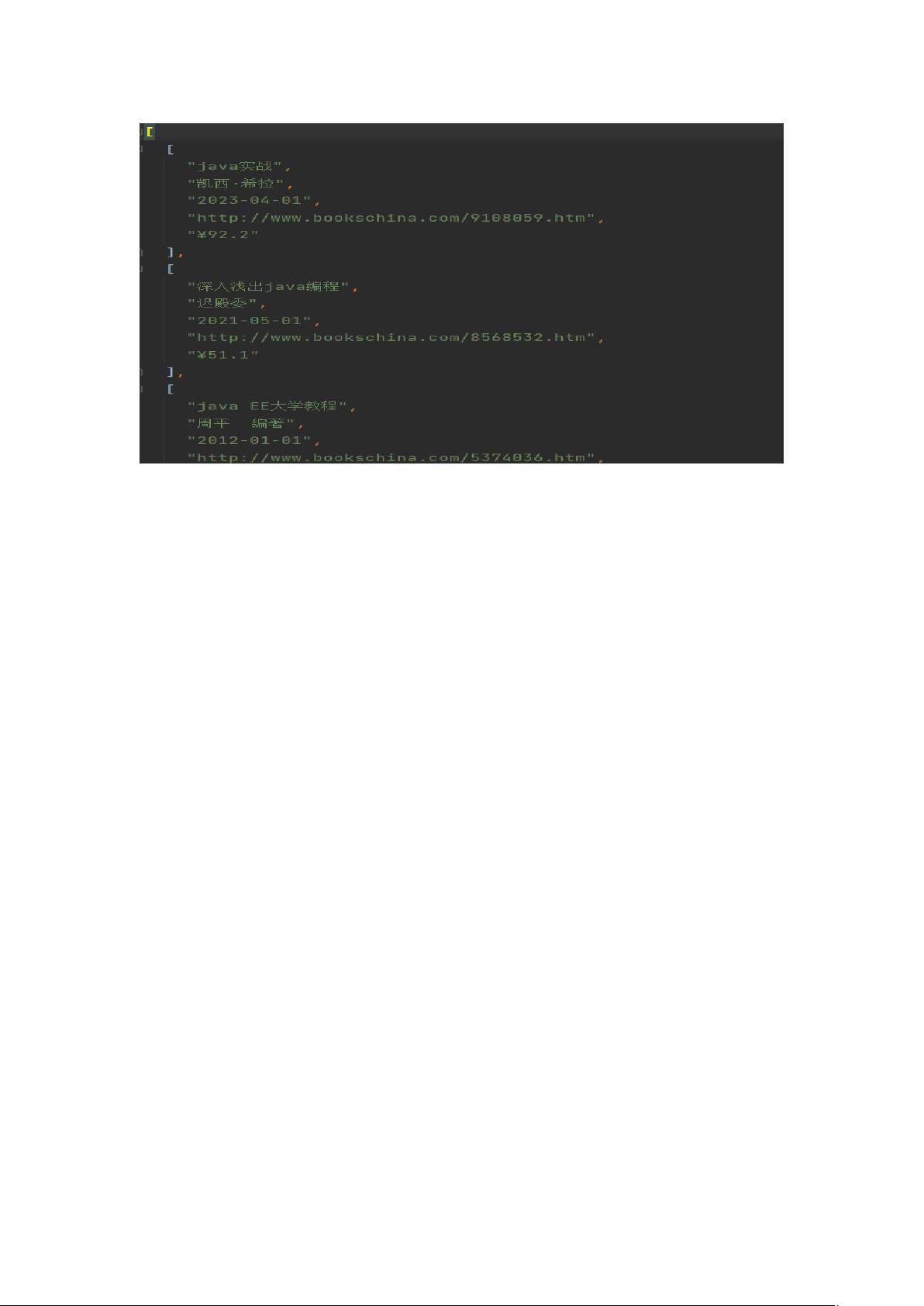
.csv
剩余12页未读,继续阅读
2021-09-13 上传
2022-02-08 上传
2021-09-22 上传
2023-03-21 上传
2021-10-10 上传
2021-10-05 上传
2024-03-31 上传
2024-10-22 上传

m0_67443107
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 开源通讯录备份系统项目,易于复刻与扩展
- 探索NX二次开发:UF_DRF_ask_id_symbol_geometry函数详解
- Vuex使用教程:详细资料包解析与实践
- 汉印A300蓝牙打印机安卓App开发教程与资源
- kkFileView 4.4.0-beta版:Windows下的解压缩文件预览器
- ChatGPT对战Bard:一场AI的深度测评与比较
- 稳定版MySQL连接Java的驱动包MySQL Connector/J 5.1.38发布
- Zabbix监控系统离线安装包下载指南
- JavaScript Promise代码解析与应用
- 基于JAVA和SQL的离散数学题库管理系统开发与应用
- 竞赛项目申报系统:SpringBoot与Vue.js结合毕业设计
- JAVA+SQL打造离散数学题库管理系统:源代码与文档全览
- C#代码实现装箱与转换的详细解析
- 利用ChatGPT深入了解行业的快速方法论
- C语言链表操作实战解析与代码示例
- 大学生选修选课系统设计与实现:源码及数据库架构
