"Hadoop基本组件原理及发展历程概述"
需积分: 0 133 浏览量
更新于2024-01-03
收藏 1.31MB DOCX 举报
Hadoop的基本组件原理总结
Hadoop平台的发展过程始于谷歌公司的两款产品:GFS(Google File System)和MapReduce。在2006年3月,Map/Reduce和Nutch Distributed File System(DNFS)被纳入Hadoop项目中,从而形成了Hadoop的基本组成部分,主要包括HDFS(Hadoop Distributed File System)、MapReduce和Hbase。
Hadoop是一个能够对大量数据进行分布式处理的软件框架。它以一种可靠、高效、可伸缩的方式进行数据处理。Hadoop最初源于Apache Nutch项目,该项目是一个开源的网络搜索引擎,而Apache Lucene文本搜索引擎库是其一部分。Hadoop这个名字并非是英文的缩写,它是一个虚构的名字,来自于创始人Doug Cutting孩子的一个大象玩具的名字。
Nutch项目始于2002年,最初是一个可工作的网络爬虫和搜索系统。然而,随着他们意识到他们的架构无法扩展到拥有数十亿个网页的网络,他们开始寻求更强大的解决方案。正是在2003年,谷歌发表了一篇关于分布式文件系统(Google File System)的描述,这篇论文对Nutch项目产生了极大的影响。Hadoop的设计受到了GFS的启发,以解决存储大规模数据的需求。
Hadoop的核心组件之一是HDFS,它是一个分布式文件系统,可以将大数据集有效地分布在多个服务器集群上。HDFS通过将数据分成多个块并将其副本存储在多个服务器上来实现可靠性和容错性。此外,HDFS还具有高度扩展性,可以处理大规模数据的存储和访问。
另一个重要的组件是MapReduce,它是一种用于处理大规模数据集的编程模型。MapReduce允许用户将任务分解成可并行处理的小任务,并在多个计算节点上进行处理。具体而言,Map阶段将输入数据分成多个小块并进行处理,然后Reduce阶段将这些处理结果进行合并和整合。通过这种方式,MapReduce提供了一种可扩展和高效的处理大数据集的方法。
还有一个常用的组件是Hbase,它是一个分布式、可扩展的列式数据库系统,建立在Hadoop的HDFS之上。Hbase提供了一种快速、可靠的方式来存储和检索大规模的结构化数据。它支持实时读写操作,并具有分布式和容错的特性。
总结起来,Hadoop是一个能够对大量数据进行分布式处理的软件框架,主要由HDFS、MapReduce和Hbase组成。Hadoop的发展过程源自于Google的GFS和MapReduce,而Nutch项目的启发则促使了Hadoop的设计。通过这些组件的协同工作,Hadoop提供了一种高效、可靠、可扩展的方式来处理大规模数据集。
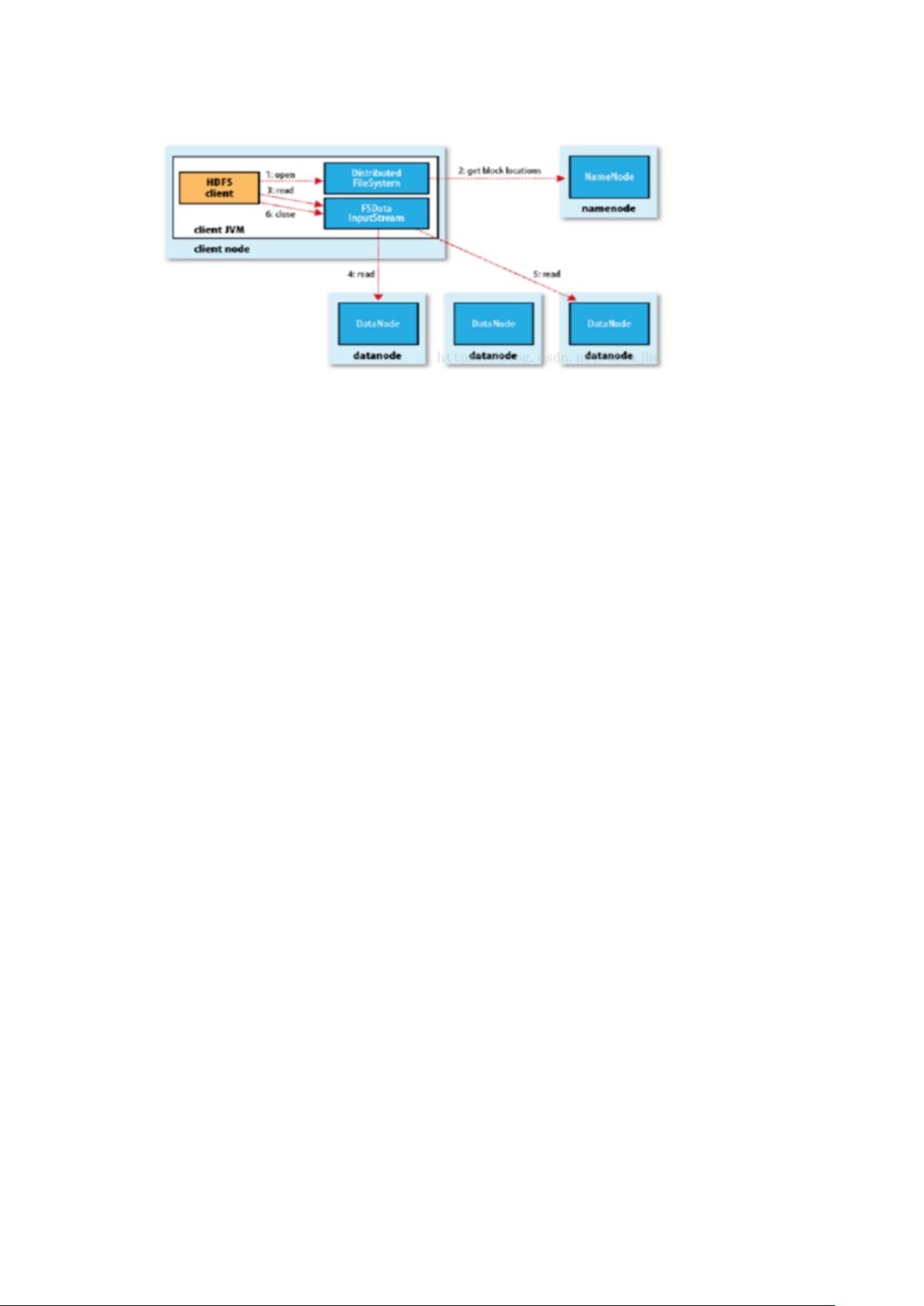
HDFS 读流程
3、简述 HDFS 写流程。
(1)客户端向 NameNode 发出写文件请求。
(2)检查是否已存在文件、检查权限。若通过检查,直接先将操作写入 EditLog,并返回输出流对象。
(注:WAL,write ahead log,先写 Log,再写内存,因为 EditLog 记录的是最新的 HDFS 客户端执行所有的写操作。如果后续真实写操作失败了,由
于在真实写操作之前,操作就被写入 EditLog 中了,故 EditLog 中仍会有记录,我们不用担心后续 client 读不到相应的数据块,因为在第 5 步中
DataNode 收到块后会有一返回确认信息,若没写成功,发送端没收到确认信息,会一直重试,直到成功)
(3)client 端按 128MB 的块切分文件。
(4)client 将 NameNode 返回的分配的可写的 DataNode 列表和 Data 数据一同发送给最近的第一个 DataNode 节点,此后 client 端和 NameNode 分
配的多个 DataNode 构成 pipeline 管道,client 端向输出流对象中写数据。client 每向第一个 DataNode 写入一个 packet,这个 packet 便会直接在
pipeline 里传给第二个、第三个…DataNode。
(注:并不是写好一个块或一整个文件后才向后分发)
(5)每个 DataNode 写完一个块后,会返回确认信息。
(注:并不是每写完一个 packet 后就返回确认信息,个人觉得因为 packet 中的每个 chunk 都携带校验信息,没必要每写一个就汇报一下,这样效率
太慢。正确的做法是写完一个 block 块后,对校验信息进行汇总分析,就能得出是否有块写错的情况发生)
(6)写完数据,关闭输输出流。
(7)发送完成信号给 NameNode。
(注:发送完成信号的时机取决于集群是强一致性还是最终一致性,强一致性则需要所有 DataNode 写完后才向 NameNode 汇报。最终一致性则其
中任意一个 DataNode 写完后就能单独向 NameNode 汇报,HDFS 一般情况下都是强调强一致性。
剩余20页未读,继续阅读
2020-08-29 上传
2020-07-17 上传
2020-06-28 上传
2022-11-24 上传
2021-10-14 上传
2021-02-17 上传
2024-07-12 上传

shsh1234567890
- 粉丝: 4
- 资源: 37
 我的内容管理
展开
我的内容管理
展开







最新资源
- Chrome ESLint扩展:实时运行ESLint于网页脚本
- 基于 Webhook 的 redux 预处理器实现教程
- 探索国际CMS内容管理系统v1.1的新功能与应用
- 在Heroku上快速部署Directus平台的指南
- Folks Who Code官网:打造安全友好的开源环境
- React测试专用:上下文提供者组件实现指南
- RabbitMQ利用eLevelDB后端实现高效消息索引
- JavaScript双向对象引用的极简实现教程
- Bazel 0.18.1版本发布,Windows平台构建工具优化
- electron-notification-desktop:电子应用桌面通知解决方案
- 天津理工操作系统实验报告:进程与存储器管理
- 掌握webpack动态热模块替换的实现技巧
- 恶意软件ep_kaput: Etherpad插件系统破坏者
- Java实现Opus音频解码器jopus库的应用与介绍
- QString库:C语言中的高效动态字符串处理
- 微信小程序图像识别与AI功能实现源码
