KLOOK旅行:Apache Hudi驱动的实时数据湖优化实践
版权申诉
65 浏览量
更新于2024-08-06
收藏 586KB DOC 举报
KLOOK客路旅行是一家全球领先的在线旅游服务平台,其业务涵盖全球100多个国家和地区,提供了丰富的旅行产品和服务。由于业务快速发展,原有的数据同步策略无法满足实时性需求,特别是对于RDS MySQL数据库中的数据,8小时的同步频率无法适应快速变化的业务场景。因此,KLOOK决定对数据湖架构进行升级,采用Apache Hudi作为核心组件。
在原有的架构中,数据主要通过Google Alooma进行RDS的全量和增量同步,每8小时进行一次数据整合,然后通过Dataflow处理并写入数仓的ODS层。这种方式存在数据延迟且灵活性不足,难以满足实时分析和业务决策的需求。
改进后的架构引入了AWSDMS数据迁移工具,将RDS MySQL的全量数据迁移到S3存储,这不仅提高了数据的安全性和可扩展性,也为后续的数据处理提供了更高效的基础。Flink SQL Batch作业被用来批量将S3中的数据写入Hudi表,实现了秒级数据入湖,显著提升了数据实时性。
Debezium MySQL binlog订阅任务确保了MySQL数据库变更的实时捕获,并通过Flink实时同步到Kafka,进一步加速了数据流转。同时,Flink SQL作业实现了流式处理,既实时写入Hudi,也持续追加写入S3备份,以支持30天的数据回溯。Hudi catalog的数据同步工具允许Hive和Trino等分析工具访问Hudi数据,实现了OLAP查询的便捷性。
这一架构的改进带来了显著的优势:首先,数据使用和开发的灵活性大大提升,不再受制于外部服务;其次,数据延迟问题得到了有效解决,RDS数据的入仓时间缩短到了分钟或秒级别,这对于库存管理、风控等关键业务环节尤为重要。此外,实时数据湖的构建为KLOOK的其他业务部门提供了即时的数据支持,促进了业务决策的敏捷性。
KLOOK客路旅行通过引入Apache Hudi,成功地优化了数据湖架构,实现了数据的高效实时处理和灵活使用,为公司的业务增长和竞争力提升奠定了坚实的基础。
KLOOK 客路旅行基于 Apache Hudi 的数据湖实践
1. 业务背景介绍
客路旅行(KLOOK)是一家专注于境外目的地旅游资源整合的在线旅行平台,提供景点
门票、一日游、特色体验、当地交通与美食预订服务。覆盖全球 100 个国家及地区,支持 12
种语言和 41 种货币的支付系统,与超过 10000 家商户合作伙伴紧密合作,为全球旅行者提供
10 万多种旅行体验预订服务。
KLOOK 数仓 RDS 数据同步是一个很典型的互联网电商公司数仓接入层的需求。对于公
司数仓,约 60%以上的数据直接来源与业务数据库,数据库有很大一部分为托管的 AWS
RDS-MYSQL 数据库,有超 100+数据库/实例。RDS 直接通过来的数据通过标准化清洗即
作为数仓的 ODS 层,公司之前使用第三方商业工具进行同步,限制为每隔 8 小时的数据同
步,无法满足公司业务对数据时效性的要求,数据团队在进行调研及一系列 poc 验证后,最
后我们选择 Debezium+Kafka+Flink+Hudi 的 ods 层 pipeline 方案,数据秒级入湖,后续数仓
可基于近实时的 ODS 层做更多的业务场景需求。
2. 架构改进
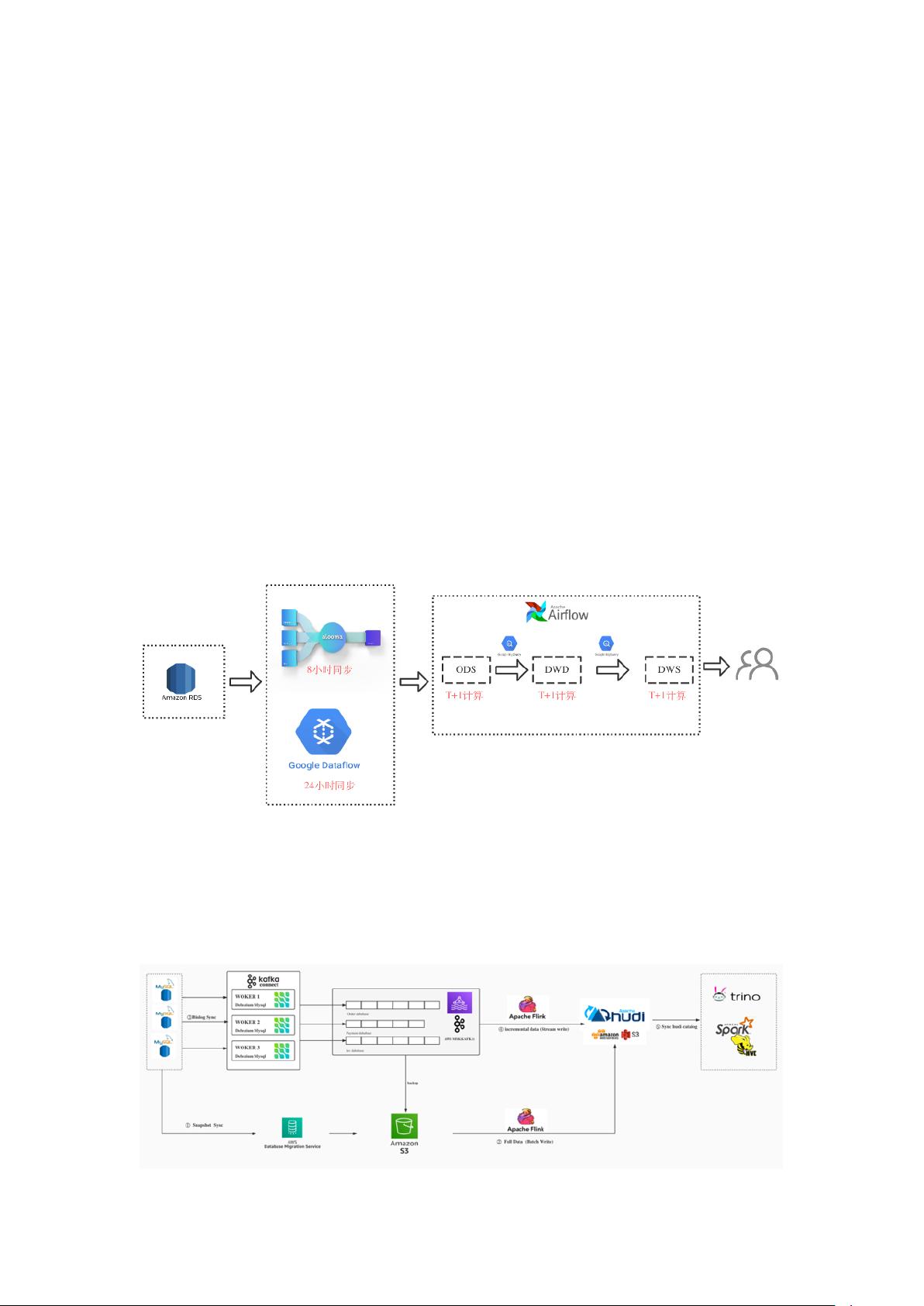
2.1 改造前架构
整体依赖于第三服务,通过 Google alooma 进行 RDS 全量增量数据同步,每隔 8 小时进
行 raw table 的 consolidation,后续使用 data flow 每 24 小时进行刷入数仓 ODS 层
2.2 新架构
下载后可阅读完整内容,剩余8页未读,立即下载
2021-10-03 上传
2021-10-14 上传
2021-12-28 上传
2021-10-04 上传
2022-03-18 上传
2022-07-10 上传
2022-03-18 上传

书博教育
- 粉丝: 1
- 资源: 2837
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
