Spark大数据处理与集群搭建教程
需积分: 5 112 浏览量
更新于2024-06-20
收藏 54.79MB PDF 举报
Spark大数据处理学习笔记是一份针对Apache Spark的大规模数据处理技术的学习资料,主要围绕Spark的分布式计算框架进行深入讲解。内容包括:
1. **搭建SparkStandalone集群**:
- 学习如何在Master节点(如虚拟机)上安装Spark,如上传安装包、解压至指定目录,设置环境变量,并编辑环境配置文件。
- 接着,扩展到Slave节点(如slave1和slave2),复制Spark到这些节点上,配置相应的环境变量,确保配置文件生效。
2. **RDD(Resilient Distributed Datasets)操作**:
- 学习RDD的创建,理解其基本概念和在Spark中的核心地位。
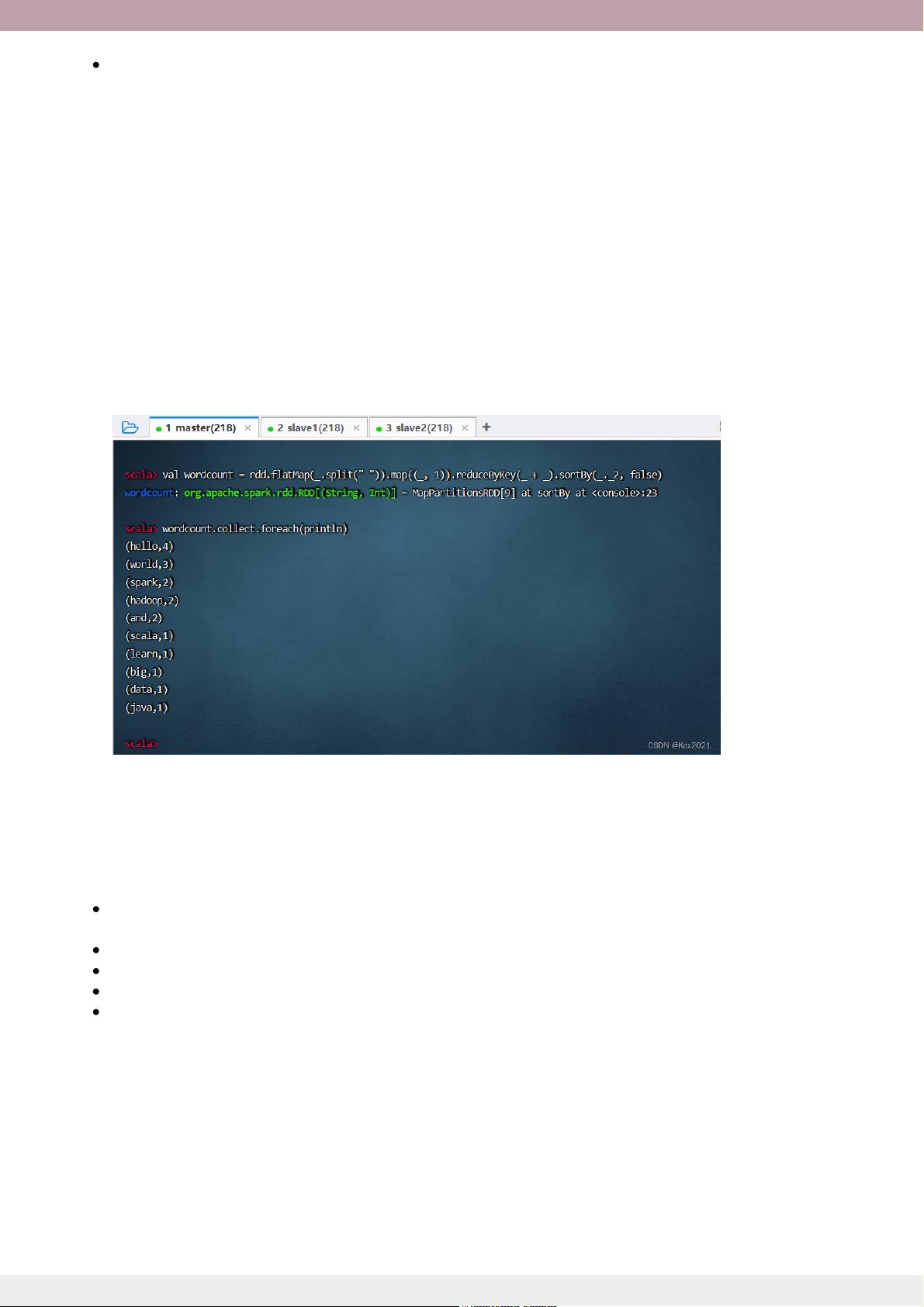
- 介绍了RDD算子,如map、filter、reduce等,它们是执行分布式计算的基础。
- 分析了RDD的分区机制,这对于性能优化至关重要。
- 提供了几个Spark RDD的典型案例,如计算总分与平均分、统计每日新增用户以及实现分组排行榜,通过实际操作演示如何运用RDD进行复杂的数据处理。
3. **离线处理总结**:
对整个Spark大数据处理的学习进行了回顾和总结,强调了Spark在大数据处理中的应用场景和优势。
4. **实战环节**:
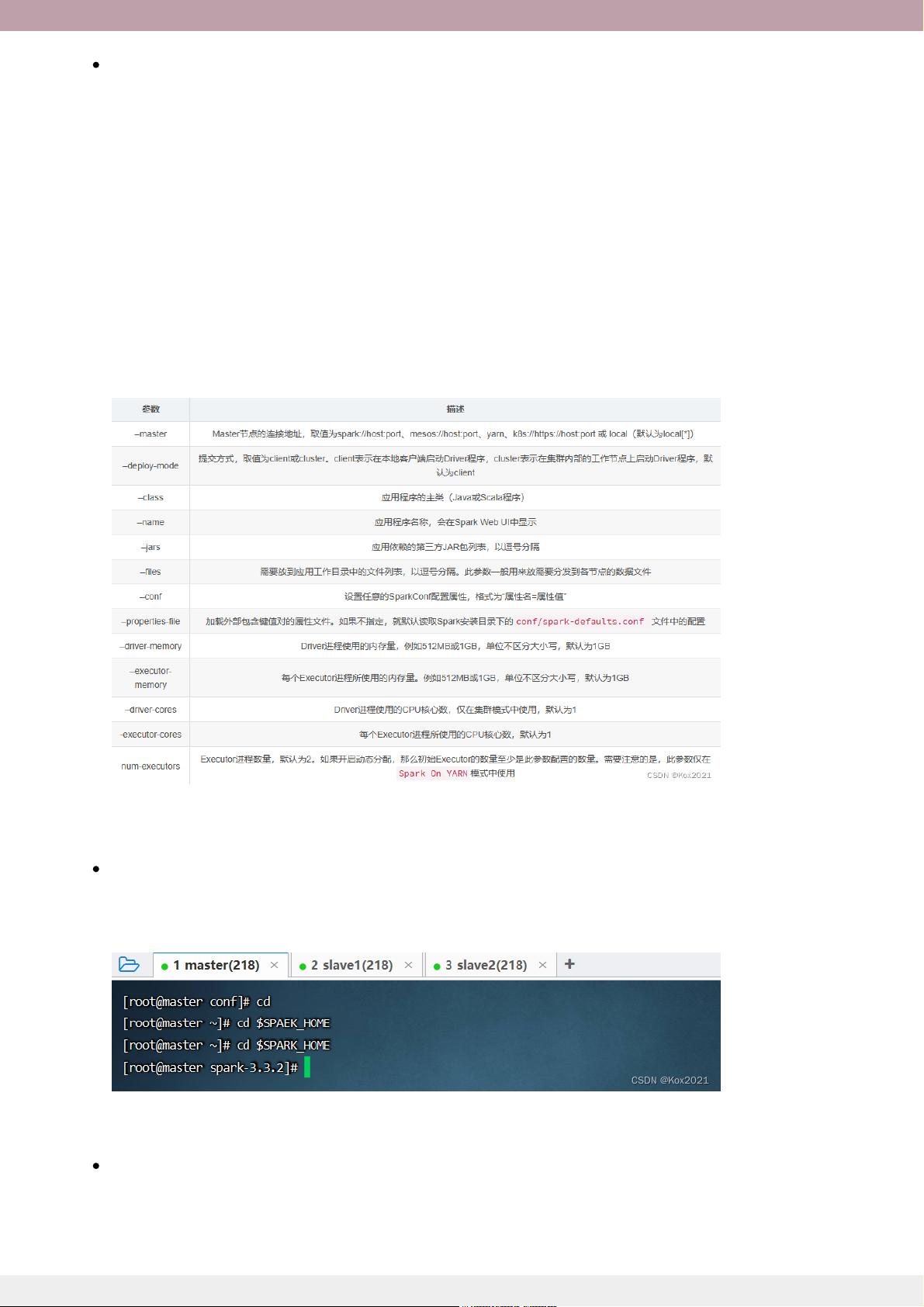
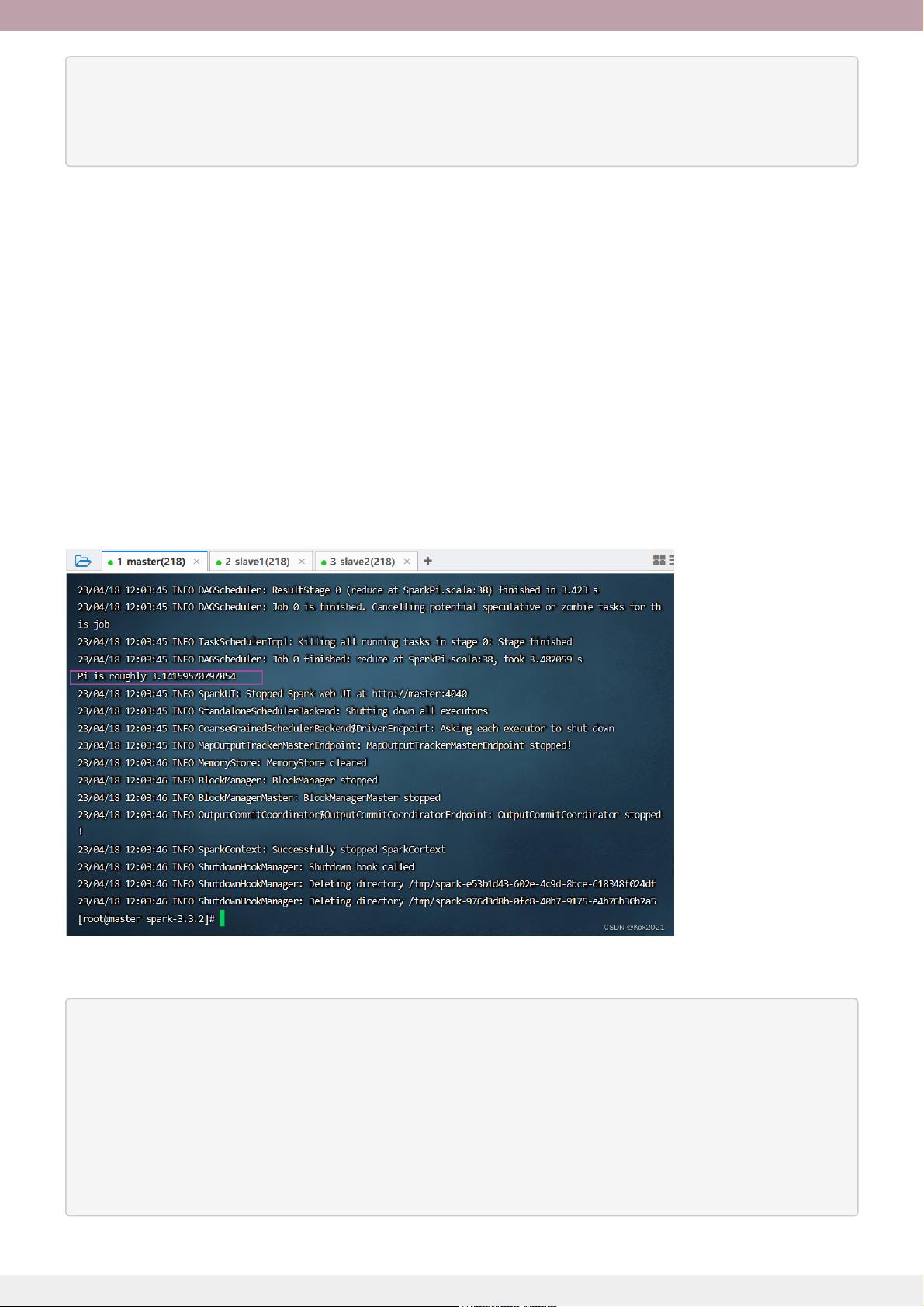
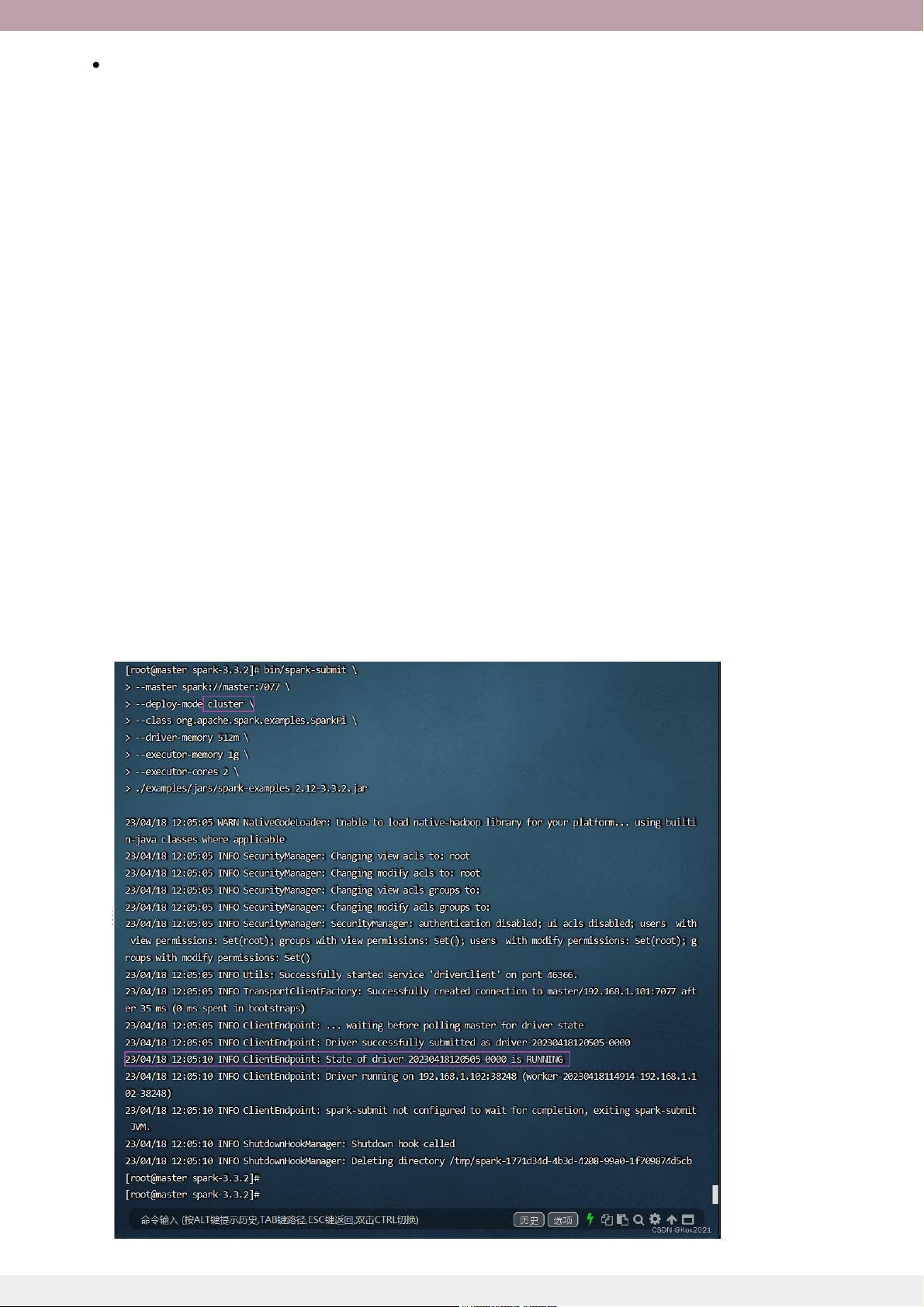
文章以实训任务的形式深入实践,详细记录了在虚拟机集群中搭建SparkStandalone集群的具体步骤,如启动Hadoop DFS服务、启动Spark集群,以及如何通过WebUI管理和监控集群,以及如何使用Scala版SparkShell提交应用程序,包括提交语法和常用的spark-submit参数。
这份学习笔记旨在帮助读者理解Spark的基本架构、核心组件和API,以及如何在实际环境中部署和使用Spark进行大数据处理。通过阅读和实践,读者可以掌握Spark在大规模数据处理中的应用和优化技巧。
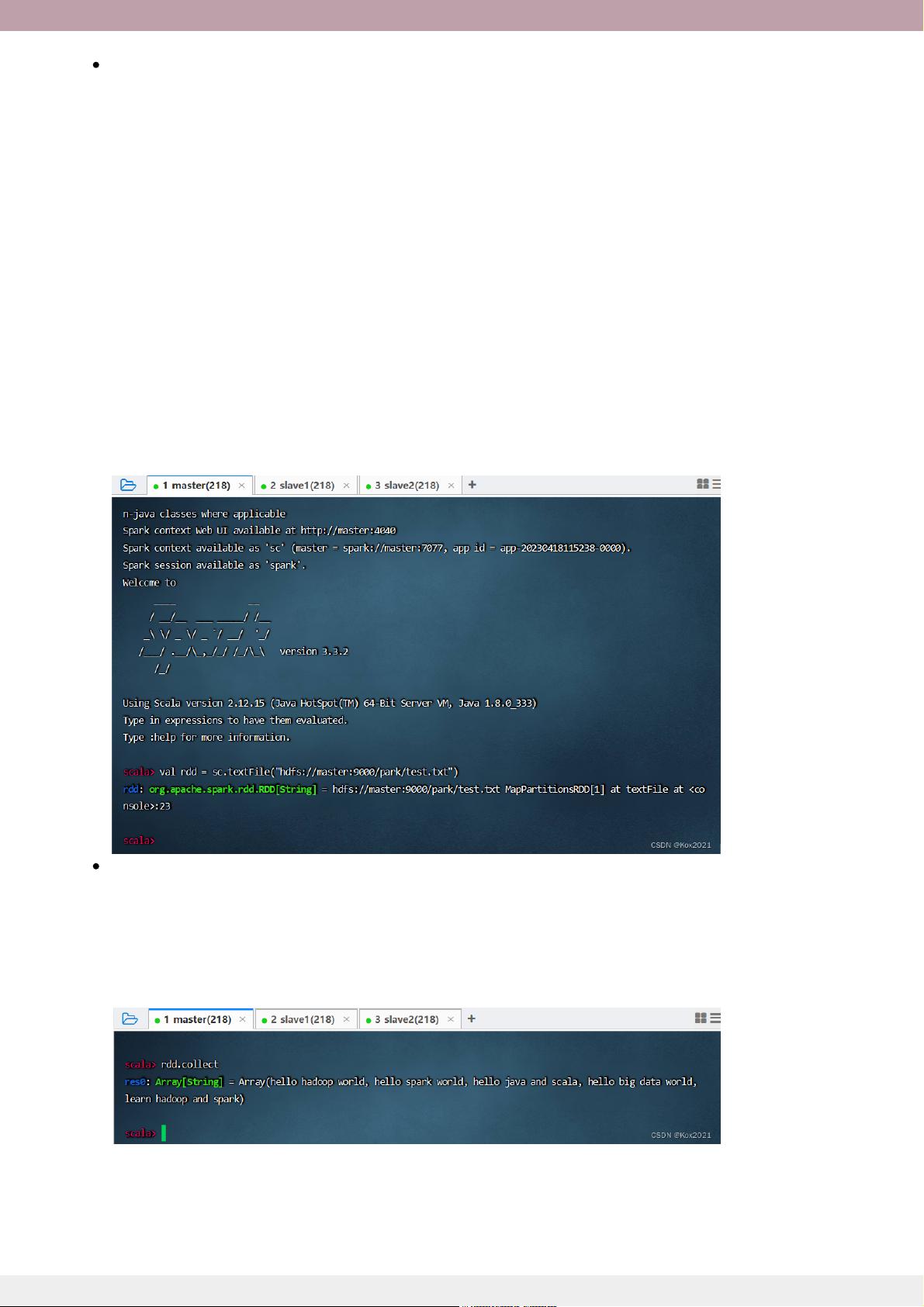
读取HDFS上的文件,创建RDD,执行命令:val rdd = sc.textFile("hdfs://master:9000
(说明: 读取的依然是HDFS上/park/test.txt") val rdd = sc.textFile("/park/test.txt")
的文件,绝对不是本地文件)
收集rdd的数据,执行命令:rdd.collect
Spark大数据处理学习笔记(2.2)搭建Spark Standalone集群
第 14 页 /共
173 页
剩余174页未读,继续阅读
2017-11-06 上传
2018-05-13 上传
2022-08-07 上传
2021-05-26 上传
2021-05-26 上传
2022-08-31 上传
2024-03-04 上传

北极象
- 粉丝: 1w+
- 资源: 396
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java集合ArrayList实现字符串管理及效果展示
- 实现2D3D相机拾取射线的关键技术
- LiveLy-公寓管理门户:创新体验与技术实现
- 易语言打造的快捷禁止程序运行小工具
- Microgateway核心:实现配置和插件的主端口转发
- 掌握Java基本操作:增删查改入门代码详解
- Apache Tomcat 7.0.109 Windows版下载指南
- Qt实现文件系统浏览器界面设计与功能开发
- ReactJS新手实验:搭建与运行教程
- 探索生成艺术:几个月创意Processing实验
- Django框架下Cisco IOx平台实战开发案例源码解析
- 在Linux环境下配置Java版VTK开发环境
- 29街网上城市公司网站系统v1.0:企业建站全面解决方案
- WordPress CMB2插件的Suggest字段类型使用教程
- TCP协议实现的Java桌面聊天客户端应用
- ANR-WatchDog: 检测Android应用无响应并报告异常
