揭秘ChatGPT背后的训练技术:从预训练到强化学习
ChatGPT原理深入解析
自从ChatGPT在市场上引起轰动以来,其强大的对话生成能力使得AI领域的专业人士不得不重新审视这一技术。尽管OpenAI并未公开ChatGPT的具体技术和训练细节,但从其与InstructGPT的关系以及已知的信息中,我们可以大致了解它的构造和工作原理。
首先,ChatGPT的训练基础是预训练大型语言模型。这一过程借鉴了GPT和BERT等模型的传统方法,通过自监督学习,模型能够理解和生成文本,GPT利用单向Transformer解码器擅长生成,而BERT则采用双向Transformer编码器,擅长理解。尽管GPT2引入了多任务预训练,使模型在零样本学习(zero-shot learning)下表现出更强泛化能力,但其Alignment(即模型的意图和行为与目标的一致性)仍有待提高,仍需针对特定任务进行微调(fine-tuning)。
其次,ChatGPT与InstructGPT的关键差异可能在于其标注数据的收集方式。OpenAI强调了这一点,表明ChatGPT可能采用了更有效的数据驱动策略,使其在理解和生成上下文连贯对话方面超越了InstructGPT。强化学习的介入帮助优化了模型,使其在处理复杂对话场景时能更好地理解用户意图,并提供连贯且准确的回答。
虽然ChatGPT在某些方面已经展现出了接近人类的交互水平,但它的技术并非完美无缺。例如,它可能依赖于大量的训练数据和算力支持,以及对语言模式的深入理解和预测。此外,关于模型的伦理和隐私问题也开始引起关注,因为大语言模型可能会学习到并复制潜在的偏见或误导信息。
ChatGPT的原理涉及深度学习中的预训练、多任务学习、强化学习以及与人类交互的理解和生成。尽管它展现出了显著的进步,但持续的技术改进和监管仍然是推动其发展的重要因素。未来,我们期待看到更多关于ChatGPT技术细节的披露,以及如何在保持性能的同时解决伦理和安全问题的研究成果。
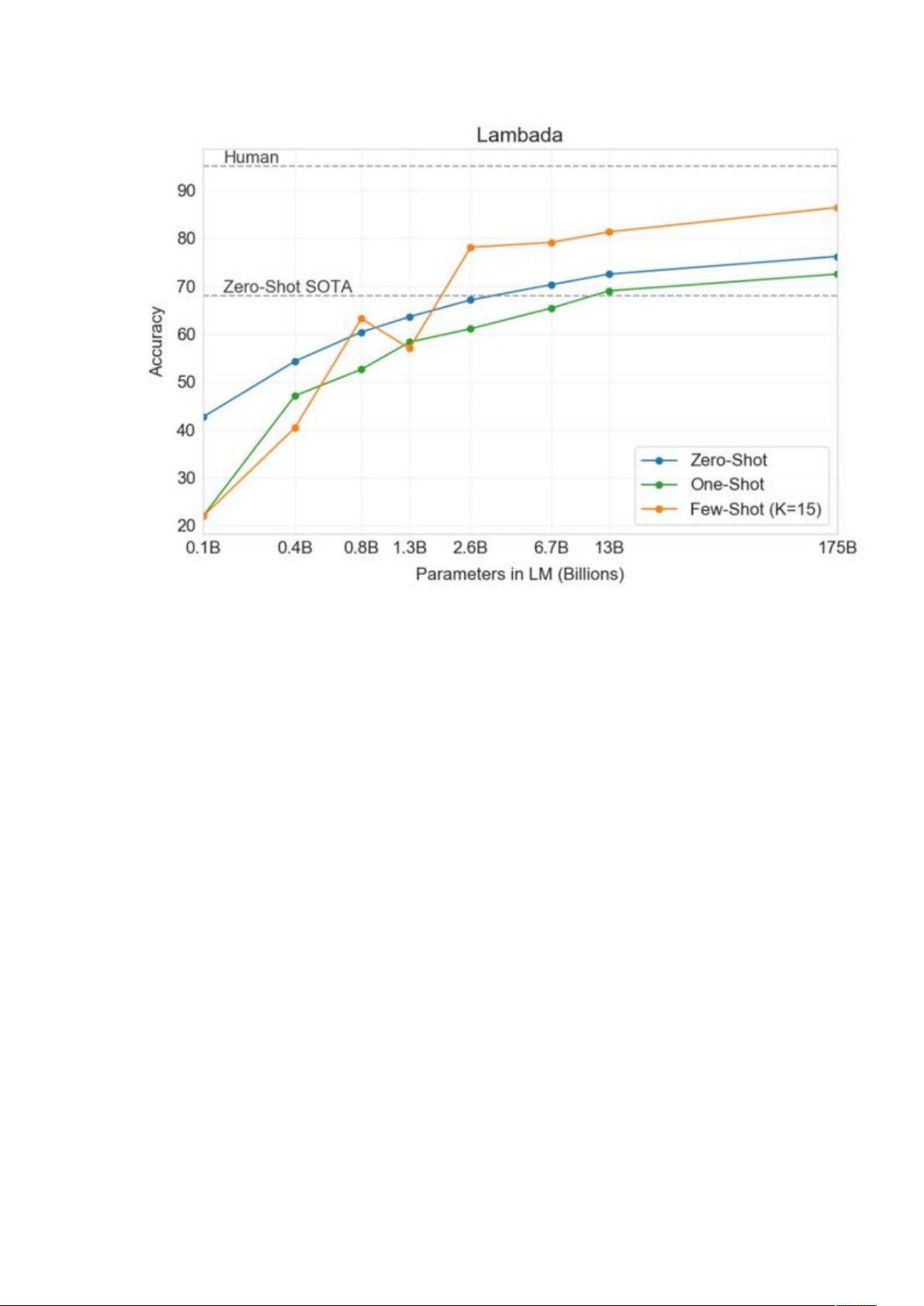
图 1 不同参数规模语言模型 zero-shot 效果对比
正如上面 GPT3 论文中的对比图所示,zero-shot 极度依赖于大语言模
型(LLM),可以说从 GPT3 开始的语言模型的发展,已经与缺乏资源
的普通人无关了,自然语言处理的发展已经全面进入了超大语言模型时
代,但这并不影响我们去理解和借鉴其思想。
ChatGPT 也正是依赖于一个大规模的语言模型(LLM)来进行冷启动
的,具体过程如图 2 所示:
剩余10页未读,继续阅读
2023-04-17 上传
2023-04-24 上传
2023-04-18 上传
2023-04-24 上传
2023-04-20 上传
2024-09-05 上传
2023-04-24 上传

Andy&lin
- 粉丝: 165
- 资源: 216
 我的内容管理
展开
我的内容管理
展开







最新资源
- WordPress作为新闻管理面板的实现指南
- NPC_Generator:使用Ruby打造的游戏角色生成器
- MATLAB实现变邻域搜索算法源码解析
- 探索C++并行编程:使用INTEL TBB的项目实践
- 玫枫跟打器:网页版五笔打字工具,提升macOS打字效率
- 萨尔塔·阿萨尔·希塔斯:SATINDER项目解析
- 掌握变邻域搜索算法:MATLAB代码实践
- saaraansh: 简化法律文档,打破语言障碍的智能应用
- 探索牛角交友盲盒系统:PHP开源交友平台的新选择
- 探索Nullfactory-SSRSExtensions: 强化SQL Server报告服务
- Lotide:一套JavaScript实用工具库的深度解析
- 利用Aurelia 2脚手架搭建新项目的快速指南
- 变邻域搜索算法Matlab实现教程
- 实战指南:构建高效ES+Redis+MySQL架构解决方案
- GitHub Pages入门模板快速启动指南
- NeonClock遗产版:包名更迭与应用更新
