PyTorch NLP教程:CBOW模型解析
52 浏览量
更新于2024-08-30
收藏 803KB PDF 举报
"这篇教程是PyTorch入门自然语言处理(NLP)系列的第二部分,主要介绍Word2vec中的CBOW模型。CBOW模型旨在通过上下文词汇来预测目标中心词,以此来学习词向量。相较于NNLM,CBOW模型更高效,能同时考虑前后词汇的影响。"
在NLP领域,CBOW(Continuous Bag of Words)模型是Word2vec的一种方法,用于学习词向量表示。CBOW模型的核心思想是通过上下文单词来预测中间的“目标”词。其目标函数是计算所有上下文词汇对中心词的条件概率之和,即\( J = \sum_{\omega\in corpus}P(w|content(w)) \)。这里的\( content(w) \)表示目标词w的上下文词汇集合。
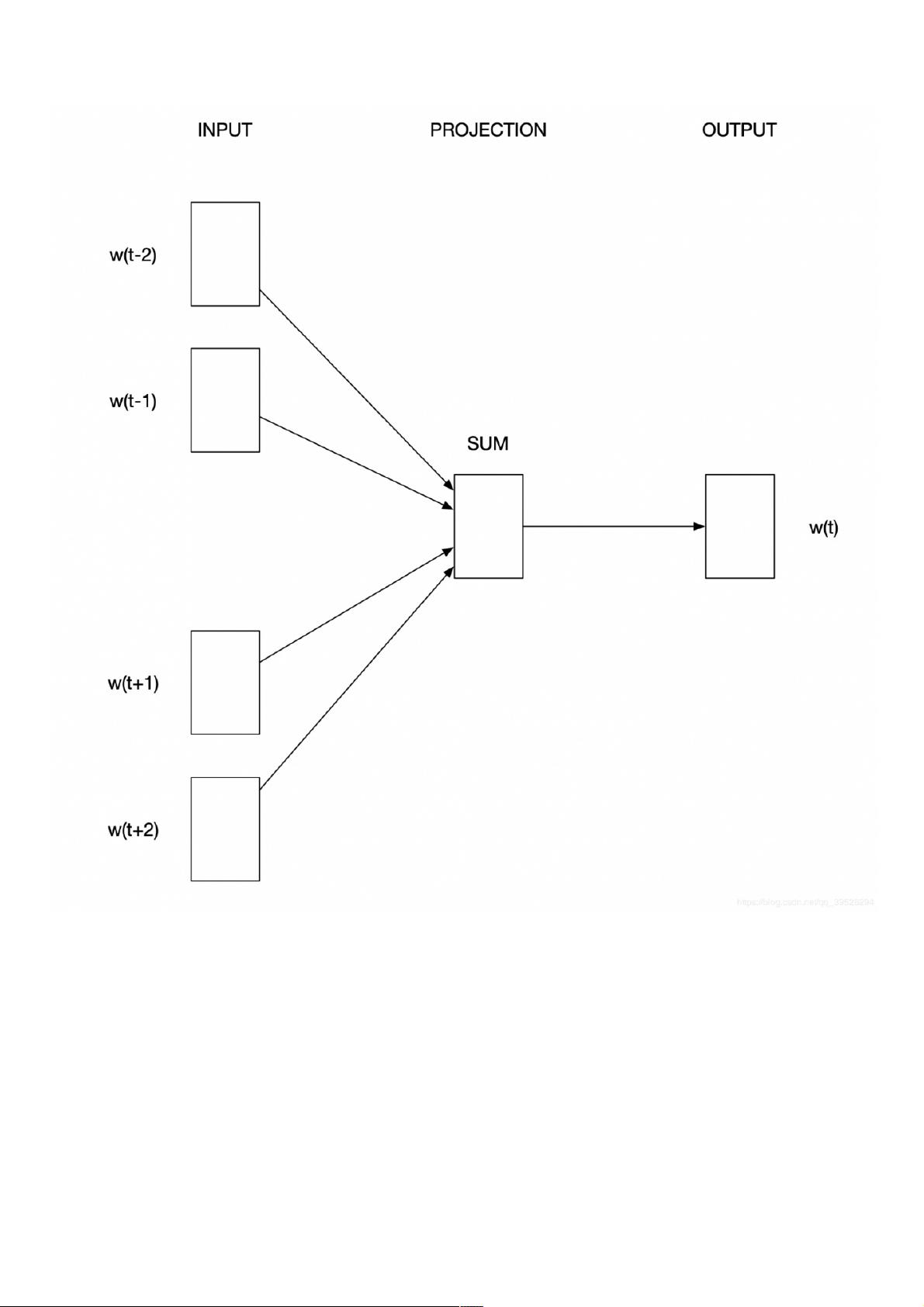
在PyTorch中实现CBOW模型时,输入是上下文单词的one-hot编码。假设词汇表大小为V,上下文窗口大小为C,则输入矩阵维度为\( C \times V \)。接着,输入的one-hot向量会与输入权重矩阵\( W (V \times N) \)相乘并求平均,形成一个维度为\( 1 \times N \)的隐层向量,其中N是隐藏层的大小。
输出阶段,这个隐层向量会乘上输出权重矩阵\( W' (N \times V) \),得到一个维度为\( 1 \times V \)的向量,这个向量代表了每个词汇成为目标词的概率分布。通过反向传播和优化算法(如随机梯度下降SGD)更新权重,使得模型能够逐步改进预测中心词的能力。
在给定的代码示例中,首先定义了一些模型参数,例如窗口大小、嵌入维度和隐藏层大小。然后,将语料库分割成句子,并提取词汇列表。这些预处理步骤为构建CBOW模型奠定了基础。
为了训练模型,我们需要进一步构建数据结构,如词索引映射、上下文窗口生成以及损失函数(通常选择交叉熵损失)和优化器(如Adam或SGD)。在训练过程中,模型会不断地根据输入上下文更新词向量,使得相似上下文的词向量接近,从而捕捉到词汇之间的语义关系。
CBOW模型是Word2vec的一种高效实现,它通过上下文预测中心词来学习词的分布式表示,这对于许多NLP任务(如词性标注、情感分析和机器翻译等)都具有重要的应用价值。在PyTorch框架下,我们可以利用其强大的张量运算和自动梯度功能轻松实现和训练CBOW模型。
pytorch入门入门NLP教程教程(二二)——CBOW
在上一个教程中我们说到了NNLM,但是NNLM虽然考虑的一个词前面的词对它的影响,但是没有办法顾忌到后面的词,而且计算量较大,所以可以使用Word2vec中的一个模型
CBOW。
下载后可阅读完整内容,剩余4页未读,立即下载
2021-02-03 上传
2020-02-23 上传
2021-05-03 上传
2023-09-22 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38711333
- 粉丝: 4
- 资源: 976
 我的内容管理
展开
我的内容管理
展开







最新资源
- js代码-对象数组去重
- mascoshopsql
- 调用系统相机录制视频并指定路径.rar
- audio-share-discord-linux:Discord屏幕共享,现在带有音频!
- Android应用源码使用ViewPager实现左右滑动翻页.zip
- GeneralLedger:总分类帐Web应用程序
- Turtle3D
- cpp代码-串行FCM算法代码
- LoveProject:。。
- image-music-box
- Android应用源码实现获取视频的缩略图(ThumbnailUtils),并且播放.zip
- NewsApp:一个简单的本机新闻应用程序
- ruby-snippet:VSCode的ruby-snippet
- squzy:Squzy-是一款高性能的开源监视,事件和警报系统,使用Bazel和love用Golang编写
- 奇异值分解实现图片压缩代码【三个代码+一个实验报告】
- fpga-docker:用于构建Docker容器的工具,用于运行各种FPGA供应商提供的工具链
