C/C++编码难题:多国语言处理与Unicode策略
PDF格式 | 116KB |
更新于2024-09-02
| 150 浏览量 | 举报
在EDA/PLD中的C/C++编程中,多国语言处理是一个复杂且挑战性的问题。由于多国语言的存在和不同操作系统间的差异,编码问题成为程序员们面临的一大难题。相较于Java,C/C++在编码一致性上存在更多变数,如XML格式错误、文本显示异常和解析器异常等常常困扰开发者。
文章首先强调了编码问题的核心,即如何确保在不同语言环境和系统中正确处理二进制数据的转换和解析。以Unicode作为核心标准,作者以简体中文为例,探讨了编码问题产生的背景和原因。C/C++编程中,编码问题主要涉及字符串操作、文件I/O以及跨平台兼容性,尤其是在内存和硬盘文件之间进行数据交换时,选择正确的编码格式至关重要。
文章指出,处理编码问题的关键在于理解各种编码格式的适用场景,如常用的Unicode(UCS-2)、GB2312和UTF8。例如,将内存中的编码A字符串转换为编码B的字节流写入文件可能会导致数据损坏或不准确,反之,从编码A的文件读取字节流并解析为编码B的字符串也可能出现混乱。
C/C++中的字符串操作通常使用宽字符(wstring),这与Java中的String处理方式有所不同。在C/C++中,程序员需要明确编码格式,比如在字符串操作时指定字符编码,或者使用专门的库函数来处理编码转换,如`iconv`或`std::wstring_convert`。同时,考虑到不同编译器和平台可能对编码支持程度不同,开发人员还需要对编译选项和库依赖进行适当的管理和测试。
结合项目经验,作者提供了解决多国语言编码问题的一般策略,包括但不限于:
1. 明确编码标准:统一编码为Unicode,尤其是对于关键数据和输出,以减少潜在的混乱。
2. 使用标准库函数:利用C++标准库提供的功能,如`std::wstring`和`std::string`,处理字符串和编码转换。
3. 错误处理与检查:编写代码时添加编码检查和错误处理代码,以尽早发现并修复潜在问题。
4. 测试和兼容性:在不同的操作系统和编译环境中进行充分的测试,确保代码在各种情况下都能正确工作。
处理多国语言编码问题在C/C++编程中是一项细致且需要深入理解的任务,通过理解和掌握编码格式、利用标准库以及谨慎的编码实践,开发者可以有效地降低乱码问题的发生,并提升软件的稳定性和用户体验。
EDA/PLD中的中的C/C++ 编程中多国语言处理编程中多国语言处理
摘要:多国语言的存在,使程序员在编码处理上花费了大量时间和精力;然而各种各样的乱码问题,如 XML 格
式错误、文本显示异常、解析器异常等依然层出不穷。特别的,相对于 JAVA 语言,C/C++ 在处理编码问题上
有更大的困难。本文避免纠缠不同编码格式的具体异同,以 Unicode 为核心,以简体中文为例,从工程应用角
度分析编码问题存在的原因,不仅提出 C/C++ 标准库编程的解决方案,更结合项目经验,总结出处理多国语言
编码问题的一般思路。 问题的提出 多国语言的存在、不同语言操作系统的存在,使得针对多语言的设
计颇费周章,在编码上所付出的工作量也是可观的。所谓编码的问题,归结起来,就是
摘要:多国语言的存在,使程序员在编码处理上花费了大量时间和精力;然而各种各样的乱码问题,如 XML 格式错误、
文本显示异常、解析器异常等依然层出不穷。特别的,相对于 JAVA 语言,C/C++ 在处理编码问题上有更大的困难。本文避
免纠缠不同编码格式的具体异同,以 Unicode 为核心,以简体中文为例,从工程应用角度分析编码问题存在的原因,不仅提
出 C/C++ 标准库编程的解决方案,更结合项目经验,总结出处理多国语言编码问题的一般思路。
问题的提出
多国语言的存在、不同语言操作系统的存在,使得针对多语言的设计颇费周章,在编码上所付出的工作量也是可观的。所
谓编码的问题,归结起来,就是二进制的编码以何种编码格式进行解析的问题。特别是在硬盘文件和内存数据的相互转化、即
读写过程中,如果采用了错误的编码格式,就会造成乱码。JAVA 语言在字符串、编码等处理方面给了程序员更为直接、方便
的接口,习惯使用 JAVA 做编码的程序员,在使用 C/C++ 进行文本编码相关的操作时,常会感到困惑。本文的目的在于以常
用的 Unicode(UCS-2)、GB2312、UTF8 三种编码为例,分析不同编码在实用中的关系,特别是 C/C++ 中,怎样处理各种
编码的问题。
编码处理常见的问题
1. 将内存中编码 A 的字符串以编码 B 格式处理成字节流写入文件
2. 将原本以 A 编码组成的文件以字节流形式读入内存、并以编码 B 解析为字符串。
第一种情况,可能造成数据的变化、失真。
如果使用 JAVA 语言,发生这种错误的情况稍少一些,因为在 JAVA 中没有 wstring 这种概念,在内存中的 String,使用
的编码都是 Unicode,其中的转换对于程序员来讲是透明的。只要使用输入 / 输出方法时注意字节流的字符集选择即可。
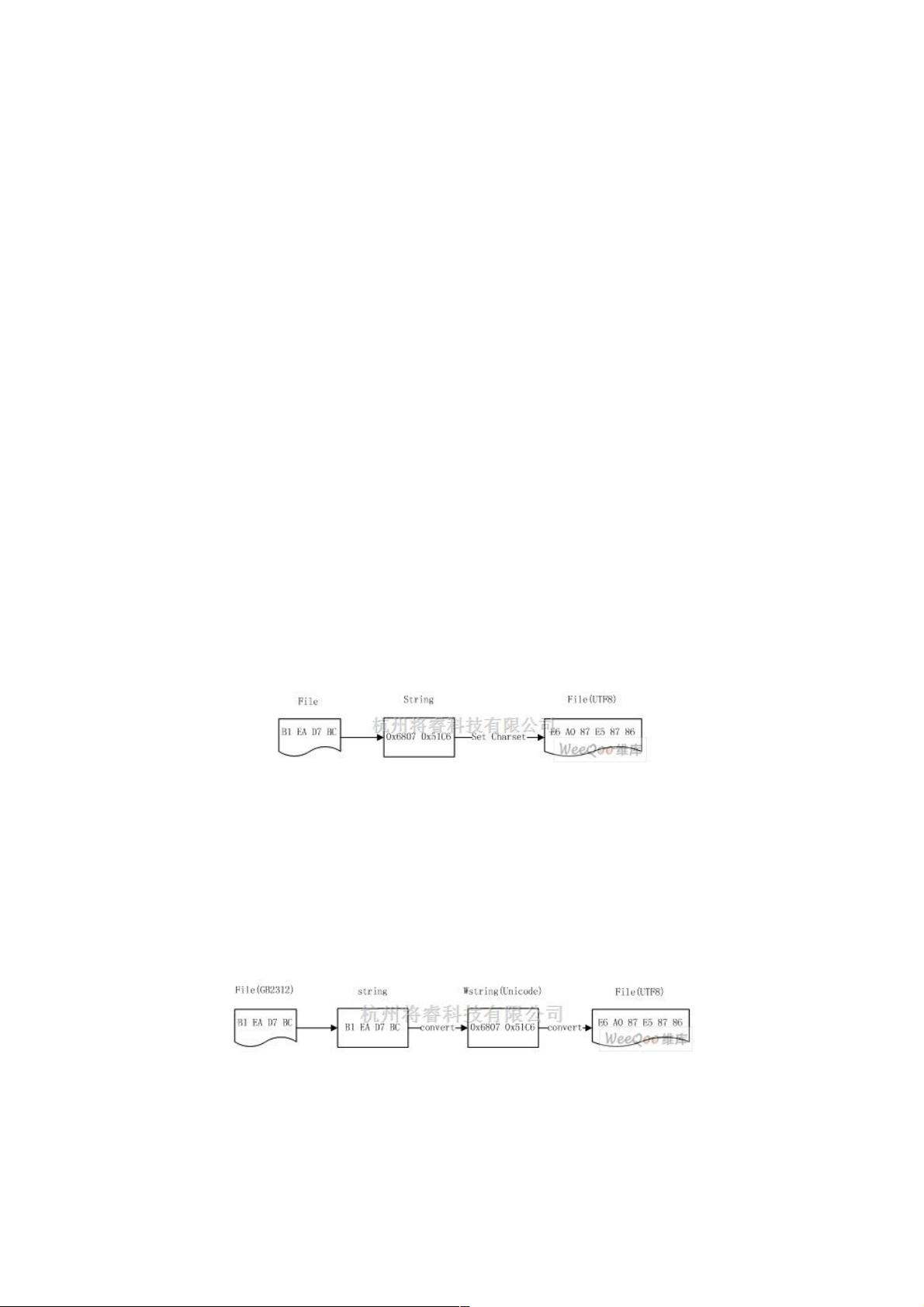
例如,编码为中文 GB2312 的“标准”字符串被读入内存后转存为 UTF8 的过程:
图 1. 文件转换编码的 JAVA 处理方式
但 C/C++ 编程,由于通常使用 char、string 类型的时候比较多,特别是进行文件读写,基本都是操作 char* 类型的数
据。并且也没有像 JAVA 中 getByte(String charsetname) 这种函数,不能直接根据字符集重新编码得到字符串的 byte 数组。
这时候,我们使用的 string 其实就一般不是 Unicode,而是符合某种编码表的。这使得我们往往困惑于 string 的编码问题。假
设有 utf8 的字符串“一”(E4 B8 80),而我们错误的认为它是符合 gb2312(编码 A)的,并将其转换为 utf8(编码 B),这种
转换结果是破坏性的,错误的输出将永远无法正确识别。
依然以“标准”为例,这是一个正确的转换:
图 2. 文件转换编码的 C/C++ 处理方式
第二种情况,则是更常见到的。例如:浏览器浏览网页时的发生的乱码问题;在写 XML 文件时,指定了 < ?xml
version="1.0" encoding="utf-8" ?> 然而文件中却包含 GB2312 的字符串——这样经常会导致 XML 文件 bad formatted,而使
得解析器出错。
这种情况下,其实数据都是正确的,只要浏览器选择正确的编码,将 XML 文件中的 GB2312 转换为 UTF8 或者修改
encoding,就可以解决问题。
下载后可阅读完整内容,剩余3页未读,立即下载
相关推荐

128 浏览量

336 浏览量


weixin_38651786
- 粉丝: 7
- 资源: 915
 我的内容管理
展开
我的内容管理
展开







最新资源
- Zigbee入门学习
- at&t 部分语法大 其中的一个小块
- ARM嵌入式系统实验教程(二)附加实验教程
- NETBEANS RCP.PDF
- 基于超混沌的FM_DCSK系统的性能分析.pdf
- GPRS模块Q39的介绍
- 《effective software testing》 addison wesley 著
- unix/linux系统管理
- 基于ORACLE数据融合的一卡通系统的实现
- java西安公司考试考试资源
- FPGA设计的经验谈
- RestFul_Rails_Dev_v_0.1
- 软件工程师笔试题目(应聘)
- 宫东风考研英语讲座.宫东风考研英语讲座
- ARM嵌入式WINCE实践教程
- SCCP信令原理介绍
