基于网格和密度的数据流聚类算法研究
版权申诉
103 浏览量
更新于2024-07-02
收藏 1.69MB PDF 举报
"计算机研究 - 数据流聚类算法的研究"
**数据流聚类算法研究**
**数据流聚类算法的背景**
传统的数据挖掘算法主要是针对于简单的、结构化的数据,这些数据大都静态的。然而,当前很多大规模数据都是以数据流的形式存在。这样的数据流具有海量的、不间断到达的、快速变化的特点,使得传统的数据挖掘算法无法适用,算法精度难以得到保证,迫切需要一些新的、基于数据流的挖掘算法。
**数据流聚类算法的重要性**
在数据挖掘中,聚类又是很重要的一方面算法,在对数据流进行聚类这一问题上,同样具有非常重要的研究价值。本文研究的正是这样一种数据流聚类的算法。
**数据流聚类算法的发展**
很多知名学者对已有的传统聚类方法进行了扩展和改进,提出不同的数据流聚类算法,已经获得了较好的聚类效果。但是,由于参数设置不当或传统算法固有的缺陷,诸多算法仍存在着一些不足之处。
**本文的贡献**
针对上述问题,本文在传统聚类算法的基础上,利用网格和密度,对其进行了扩展,使之可应用于数据流聚类问题。该方法结合了基于密度和基于网格两种聚类方法的优势,具有聚类速度较快、精度较高等优点。
**算法改进**
本文是由D-Stream算法改进得到的,充分发挥其算法优势,并且在其原有算法的基础上,进行了几方面的改进:
* 首先改进了相关参数的设置,使得划分网格疏密程度的参数可以随网格的变化进行动态调整,避免了参数设置需要具有经验知识这一问题。
* 在离线聚类阶段,本文提出了基于并查集和基于广度优先两种算法,在工程实践中具有有一定的意义。
* 同时,对原有的D-Stream算法的离线部分也做了一些改进,在聚类阶段也加入了基于并查集和基于广度优先两种算法的相关操作,优化了算法效率。
**实验验证**
最后,本文使用了KDD99数据集,对本文提出的算法进行了实验验证。通过调节实验相关的参数,使算法获得的较好性能;然后通过实验与D-Stream算法和NDD-Stream算法进行了比较,验证了本算法的正确性和高效性。
**结论**
本文提出的数据流聚类算法具有较高的聚类速度和精度,能够满足大规模数据流聚类的需求。该算法的提出为数据流挖掘领域提供了新的研究方向和思路。
第 1 章 绪论
- 5 -
2007 年,Udommanetanakit 等在文献
[13]
中提出了 E-Stream 算法,在
HPStream 算法的基础上进行了补充和完善。
1.2.3 扩展密度的方法
基于划分的方 法和基于层 次的方法都 是在整个 对象空间的 距离的基础上
进行的,这就导致了聚类结果近似于球形,这对于非球状的簇聚类效果较差。
基于密度的方法从另一个角度出发解决了这一问题。其基本思想是发现相邻区
域中密度较高的部分,并将其聚类,记入同一个簇。在传统聚类算法中,基于
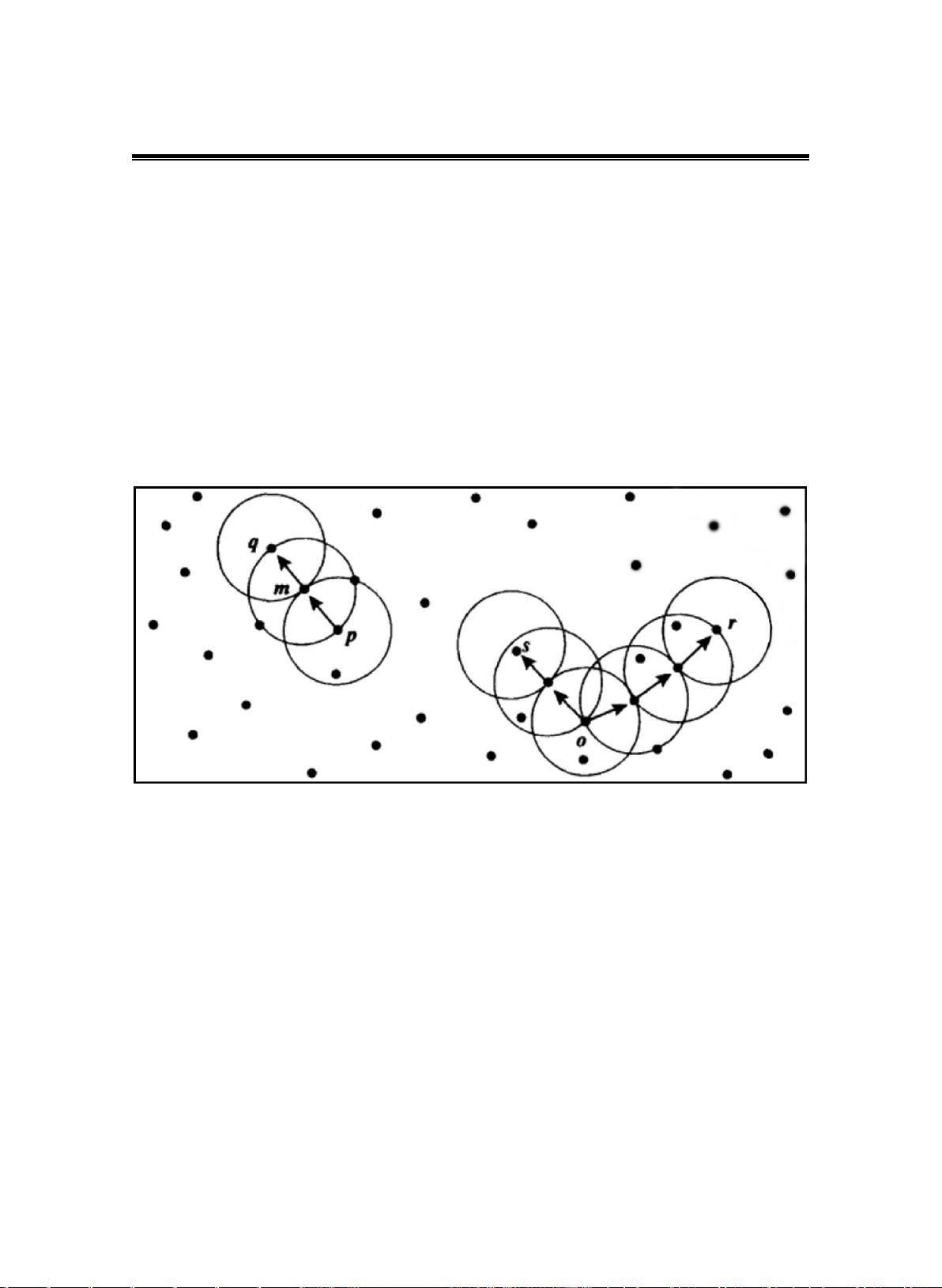
密度的典型算法是 DBSCAN 算法和 OPTICS 算法。基于密度的方法的示意图
如下:
图 1-3 基于密度的算法示意图
[3]
2006 年,Cao F 等在文献
[14]
中提出了 DenStream 算法。这是一种全新的、
基于密度方法的聚类算法。该算法使用了前面提到过的 CluStream 算法的两段
处理框架,在线阶段使用衰减窗口处理数据,生成核心微簇,离线阶段扩展了
DBSCAN 算法对数据进行聚类,由微簇生成宏簇。在 DenStream 算法中还提
出了潜在簇的概念,较为妥当的处理了数据中出现的离群点。
但是,在这个算法中仍在存在一个问题。DenStream 算法中使用了一些全
局性的常量作为参数,这样的参数对聚类结果影响比较大。针对于这个问题,
2011 年,的时候,胡睿等在文献
[15]
中提出了 DsStream 算法 ,弥补了 DenStream
算法的不足。DsStream 算法和 DenStrea m 算法同样使用了两段聚类,其中在
线阶段使用的是滑动窗口技术,没有使用全局不变的参数,而是每隔一段时间
对全局参数进行 更新,这样 动态维护参 数使得内存 空间可以更 有效的利用起
来,同时消除了聚类参数对聚类效果的影响。同时,离线部分对 DBSCAN 算


剩余56页未读,继续阅读
2022-07-02 上传
2022-07-02 上传
2021-08-10 上传
2022-07-02 上传
2023-03-12 上传
2021-07-14 上传
2019-07-22 上传
2021-08-10 上传
2023-04-01 上传

programyp
- 粉丝: 90
- 资源: 9323
 我的内容管理
展开
我的内容管理
展开







最新资源
- PDF格式的MySQL数据库初学者参考指南
- PDF格式的《戏说面向对象程序设计C#版》
- ARM+经典300+问
- Oracle.11g.-.New.Features.for.Administrators.中文版教材
- PDF格式的Rational Robot 中文帮助文档
- PDF格式的Struts2 Projects
- Struts in Action Building web applications with the leading Java framework.pdf
- Linux+C编程一站式学习
- 方案:校园网络设计方案
- 方案:网络机房建设方案
- C_C++指针经验总结
- 嵌入式操作系统简要分析
- cuda编程指南及范例
- Pro.NET 2.0 Code and Design Standards in C#, 3rd Edition (2008)
- 统一建模语言(UML)参考手册——基本概念
- 车牌识别中智能算法研究
