近似最近邻搜索:从哈希到向量量化
需积分: 10 89 浏览量
更新于2024-07-17
收藏 6.39MB PPTX 举报
"这篇资源总结了常见的快速搜索方法,包括基于树、哈希、矢量量化和图的方法,特别关注了近似最近邻搜索(Approximate Nearest Neighbor Search, ANN)。这些方法广泛应用于推荐系统、图片检索和文本检索等领域,以解决在大规模高维数据中的高效查找问题。"
在信息技术和大数据时代,快速有效地搜索相似数据变得至关重要。传统的线性搜索方法在处理大量数据时效率低下,因此出现了多种优化策略,如基于树、哈希、矢量量化和图的方法。
1. **基于树的方法**:KD-Tree 是一种典型的空间划分方法,尤其适用于高维数据。构建过程中,选择方差最大的维度作为分割依据,然后通过中值分割数据点,形成左右子空间。查询时,沿着树结构按分割点进行二分搜索,并在到达叶子节点后进行回溯,检查其他子空间是否存在更近的邻居。除KD-Tree外,还有如球树(Ball Tree)和覆盖树(Cover Tree)等类似方法。
2. **哈希方法**:哈希方法通过将高维数据映射到低维哈希码,从而减少搜索空间,提高查询效率。常见的哈希方法有 locality-sensitive hashing (LSH) 和 multi-probe LSH,它们利用碰撞概率来近似判断数据点的相似度。
3. **矢量量化方法**:这种方法通过预先训练的聚类中心(码书)对高维数据进行量化,将数据点映射到最近的聚类中心。典型的算法有 K-Means 和 Product Quantization (PQ)。PQ 将高维空间分解为多个子空间,对每个子空间分别进行量化,显著降低了存储和搜索复杂度。
4. **基于图的方法**:例如图聚类和倒排索引,这些方法利用数据之间的关系构建图结构,通过遍历图来找到最近邻。例如,Annoy(Approximate Nearest Neighbors Oh Yeah)库就使用了随机森林构建图,实现高效的搜索。
这些方法在深度学习领域特别重要,尤其是在推荐系统和计算机视觉任务中,如图像检索和文本检索。深度学习模型产生的高维特征向量需要高效的近似最近邻搜索来实现内容匹配。通过结合不同方法的优点,可以设计出更适合特定应用场景的搜索策略。
近似最近邻搜索技术是现代信息技术中不可或缺的一部分,它们通过各种巧妙的算法优化,实现了在大规模数据集上的高效搜索,从而推动了诸如推荐系统、搜索引擎、图像识别等多个领域的快速发展。
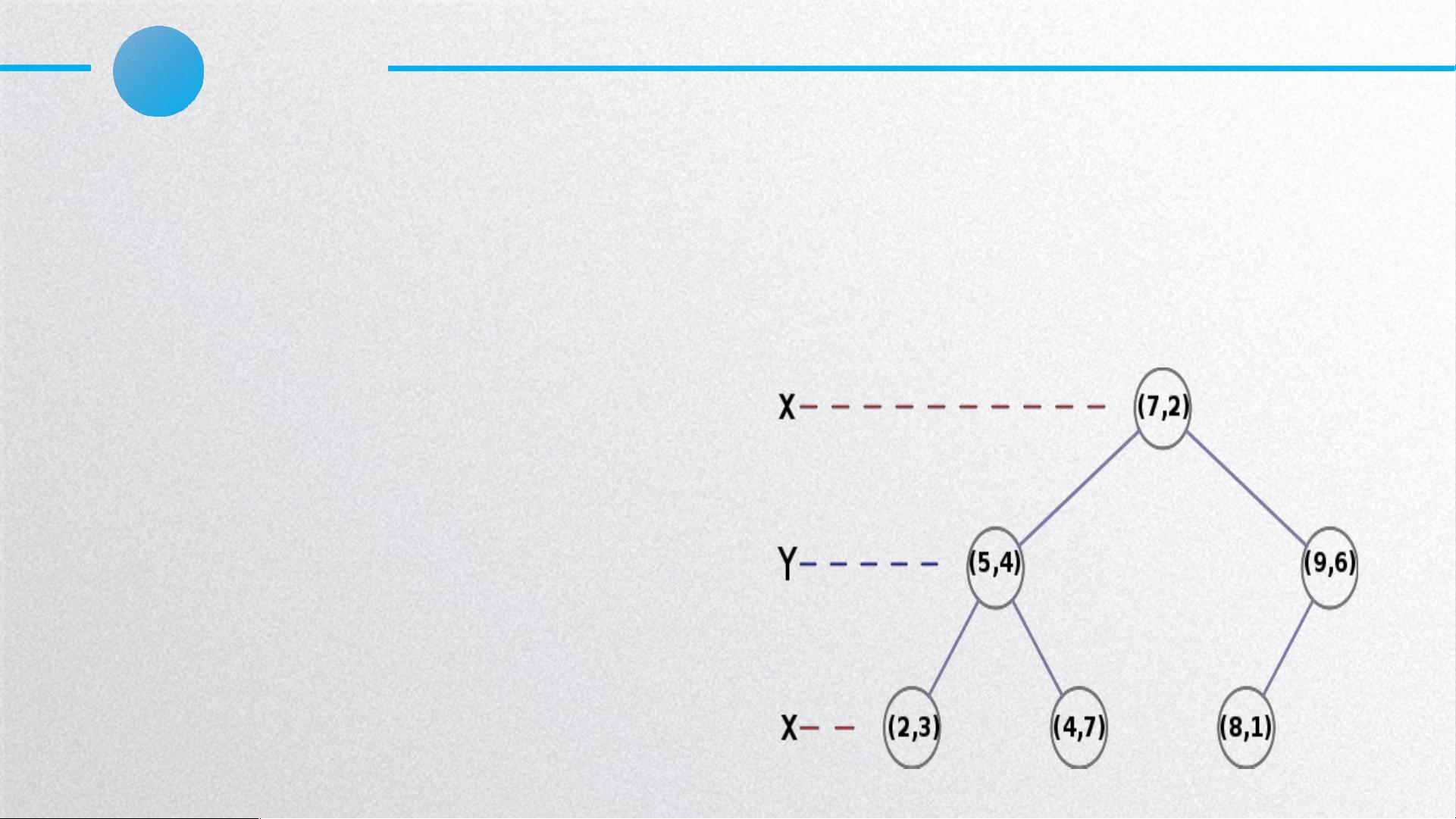
KD-Tree
3
•
最邻近查询
•
路径:类似二叉树搜索,从根节点开始,根据每个
维度的 split 维进行左右子树的查询,直到叶子节
点 构建过程
•
回溯:检查查询路径上节点的另一半子空间是否有
距离更近的点
•
查询点 (2, 4.5)
•
路径: (7, 2)(5, 4)(4, 7)
•
回溯: (5, 4)(2,3)

剩余30页未读,继续阅读
2011-07-14 上传
2009-12-27 上传
2008-10-22 上传
2013-03-01 上传
2009-05-09 上传
2016-06-17 上传
2010-08-05 上传
2012-03-20 上传

horizonheart
- 粉丝: 38
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
