深度学习模型详解:从基础知识到Keras实践
需积分: 50 178 浏览量
更新于2024-07-18
收藏 2.05MB PDF 举报
"深度学习模型介绍,通过keras代码实践,适合初学者了解深度学习中的网络模型,包括图像分类、卷积、激活函数、池化、损失函数等内容。"
深度学习是一种模仿人脑神经网络结构的机器学习方法,广泛应用于图像识别、自然语言处理等领域。在深度学习中,模型通常由多个层次组成,这些层次通过大量的权重参数连接,形成复杂的特征提取和决策系统。本资源主要介绍了深度学习的基础知识,特别是与图像分类相关的模型和操作。
1. 基础知识
- 全连接层:每个神经元都与其他所有神经元相连,用于处理输入数据的全局信息。
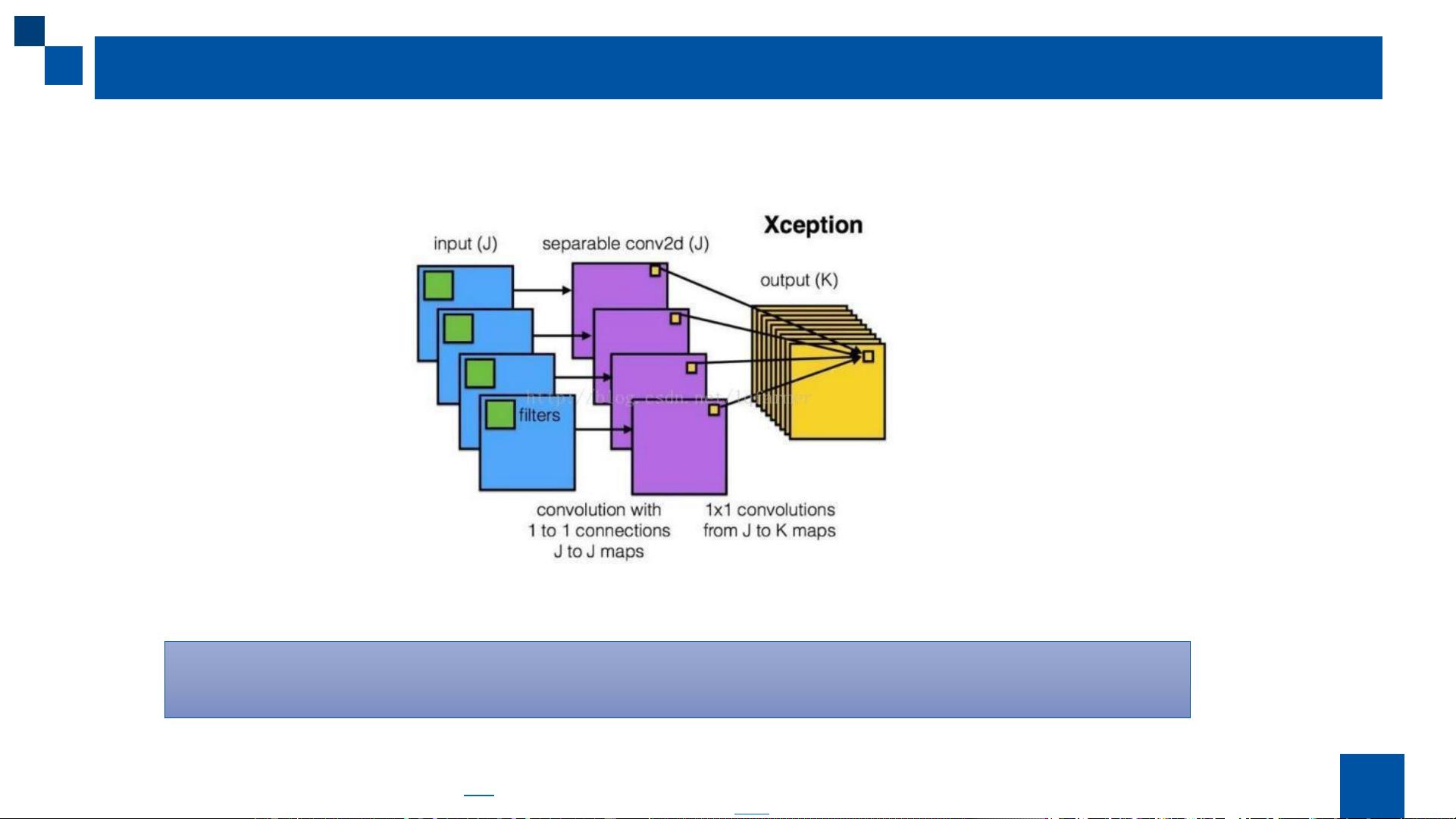
- 卷积层:是深度学习中的核心组件,通过卷积核对输入数据进行滤波,提取特征。卷积核有不同的尺寸和数量,例如这里的3x3卷积核,可以有多个输出通道(本例中为5)。
- 膨胀卷积(Dilated Convolution):保持卷积核大小不变,增加空隙(dilation),以增大感受野,提高模型对全局信息的捕捉能力,常用于图像分析和语音处理。
- 反卷积(Deconvolution):用于上采样,扩大输入尺寸,常在生成模型和图像恢复任务中使用。
2. 激活函数
- ReLU (Rectified Linear Unit):最常用的激活函数,能解决梯度消失问题,加速训练。
- Sigmoid:输出介于0和1之间,适用于二分类问题。
- Tanh:输出介于-1和1之间,比Sigmoid有更好的中心化特性。
- ELU (Exponential Linear Units):解决了ReLU的“死区”问题,提供平滑的梯度。
3. 池化操作
- 最大池化:选取局部区域的最大值,降低计算复杂性,保持关键信息。
- 平均池化:取区域平均值,提供平滑的特征表示。
- 全局池化:在整个特征图上执行池化,常用于分类任务的最后阶段。
4. 目标函数(损失函数)
- 均方误差:常用于回归任务,衡量预测值与真实值的差距。
- 交叉熵:适用于分类问题,尤其在多分类任务中。
- KL散度:衡量两个概率分布之间的差异,常用于自编码器和生成模型。
通过keras等深度学习框架,可以方便地实现这些模型和操作。初学者可以通过实践这些代码来深入理解深度学习模型的工作原理,并逐渐掌握如何构建和优化自己的深度学习模型。同时,了解和掌握这些基础知识对于进一步研究更复杂的模型如ResNet、VGG、Inception或Transformer等至关重要。

剩余40页未读,继续阅读
800 浏览量
249 浏览量
175 浏览量
1523 浏览量
602 浏览量
482 浏览量
735 浏览量
528 浏览量

新彦
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- 昆仑通态MCGS嵌入版_XMTJ温度巡检仪软件包解压教程
- MultiBaC:掌握单次与多次组批处理校正技术
- 俄罗斯方块C/C++源代码及开发环境文件分享
- 打造Android跳动频谱显示应用
- VC++实现图片处理的小波变换方法
- 商城产品图片放大镜效果的实现与用户体验提升
- 全新发布:jQuery EasyUI 1.5.5中文API及开发工具包
- MATLAB卡尔曼滤波运动目标检测源代码及数据集
- DoxiePHP:一个PHP开发者的辅助工具
- 200mW 6MHz小功率调幅发射机设计与仿真
- SSD7课程练习10答案解析
- 机器人原理的MATLAB仿真实现
- Chromium 80.0.3958.0版本发布,Chrome工程版新功能体验
- Python实现的贵金属追踪工具Goldbug介绍
- Silverlight开源文件上传工具应用与介绍
- 简化瀑布流组件实现与应用示例
