"Linux系统下安装Hadoop和一系列软件的详细步骤及版本信息"
需积分: 9 3 浏览量
更新于2024-01-02
收藏 3.83MB DOCX 举报
该文档是关于在Linux操作系统上安装和配置多个软件的说明文档。它主要介绍了在虚拟机上搭建运行Hadoop、Zookeeper、Flume、Kafka、MySQL、Hive、Redis、Elasticsearch、RabbitMQ、HBase、Spark、Storm和Azkaban等软件的过程。
本文档首先详细列出了各个软件的安装目录和版本信息,例如JDK安装目录为"jdk1.8.0_131",Hadoop安装目录为"hadoop-2.8.2"等。
然后,文档给出了在Linux系统上安装这些软件的步骤和注意事项。首先是JDK的安装,文档建议使用版本为1.8.0_131,并给出了具体的安装步骤。
接着是Hadoop的安装。文档指导用户下载并解压Hadoop安装包,然后配置环境变量和修改配置文件。详细说明了各个配置文件的作用和修改方法。
之后是Zookeeper、Flume、Kafka、MySQL、Hive、Redis、Elasticsearch、RabbitMQ、HBase、Spark、Storm和Azkaban等软件的安装过程。文档详细介绍了每个软件的下载、解压、配置和启动步骤,并给出了一些常见问题的解决方法。
最后,文档还提供了一些关于软件的常用命令和配置文件的说明。例如,介绍了如何使用Hadoop的命令行工具和Web界面管理Hadoop集群,以及如何配置Hive和Spark的参数文件等。
总之,该文档是一份详细的软件安装和配置说明文档,适用于在Linux系统上搭建和运行Hadoop、Zookeeper、Flume、Kafka、MySQL、Hive、Redis、Elasticsearch、RabbitMQ、HBase、Spark、Storm和Azkaban等软件的用户使用。通过按照文档中提供的步骤和注意事项进行操作,用户可以方便地安装和配置这些软件,并快速上手使用。

F网关 这里为默认网关 与你的物理机所在网段一直 如 ;;;;;;;;;
A-$EF主的 A-$
A-$EF备用 A-$
;%= 编辑完成输入’#@保存退出
;$= 重启网卡指令:
;,= 按照以上步骤即可实现 215 模式,如果 ! 不通,关闭防火
墙。
;= 关闭防火墙
46 查看防火墙:FC&3%%
46 关闭防火墙:F%%%C&3&'"
46 禁止 C&3 开机启动:F%%"!
C&3&'"
;= 设置
修改命令:'":%:%#
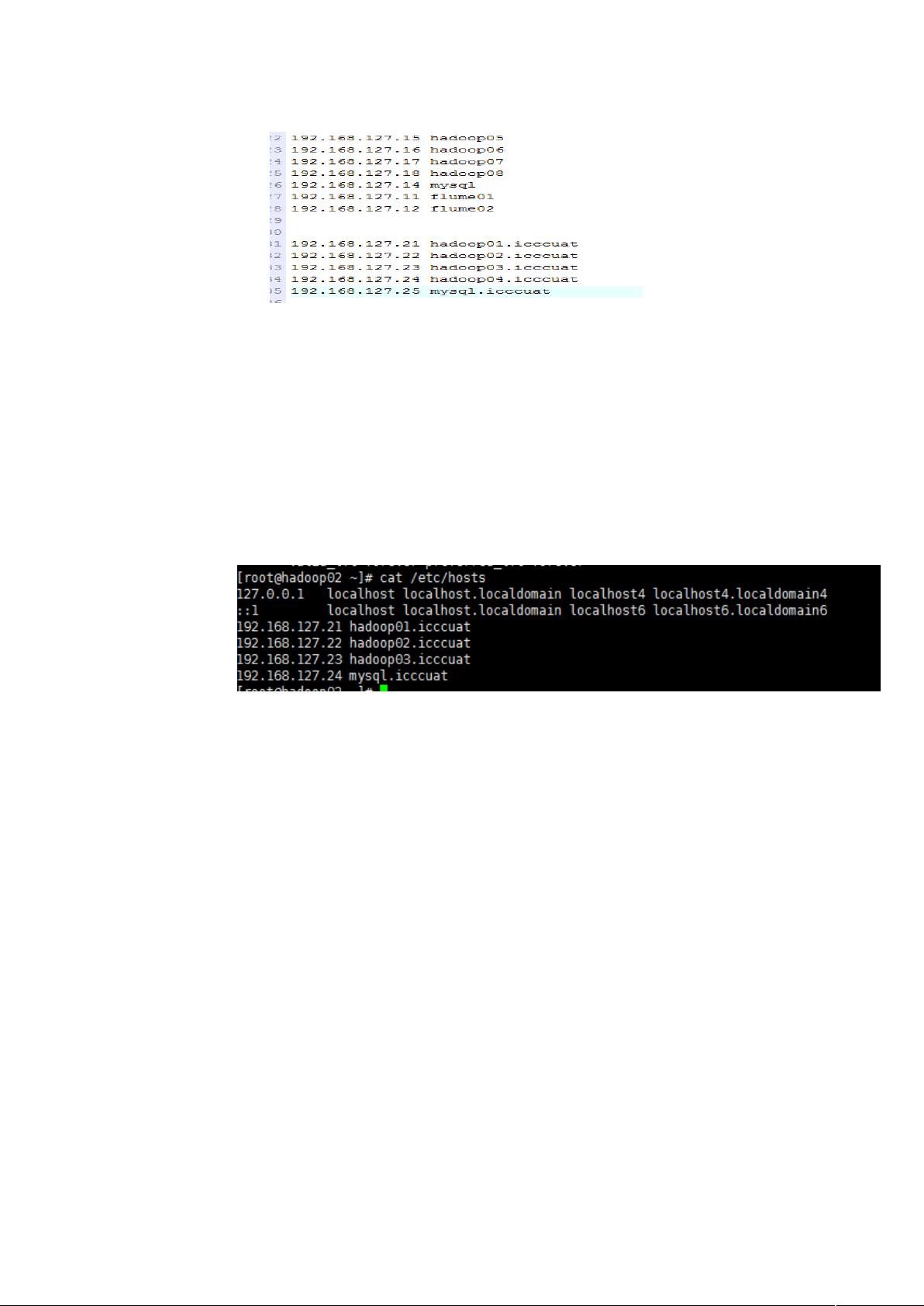
;%= 设置 配置主机名和 映射
= 在 下设置 配置主机名和 映射
I"#3 下路径:B>PI"#3P$%P&"'&P%

剩余56页未读,继续阅读
2023-06-21 上传
2023-07-13 上传
2023-07-24 上传
2023-04-03 上传
2023-06-22 上传
2024-01-07 上传

做自己的太阳·
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 火炬连体网络在MNIST的2D嵌入实现示例
- Angular插件增强Application Insights JavaScript SDK功能
- 实时三维重建:InfiniTAM的ros驱动应用
- Spring与Mybatis整合的配置与实践
- Vozy前端技术测试深入体验与模板参考
- React应用实现语音转文字功能介绍
- PHPMailer-6.6.4: PHP邮件收发类库的详细介绍
- Felineboard:为猫主人设计的交互式仪表板
- PGRFileManager:功能强大的开源Ajax文件管理器
- Pytest-Html定制测试报告与源代码封装教程
- Angular开发与部署指南:从创建到测试
- BASIC-BINARY-IPC系统:进程间通信的非阻塞接口
- LTK3D: Common Lisp中的基础3D图形实现
- Timer-Counter-Lister:官方源代码及更新发布
- Galaxia REST API:面向地球问题的解决方案
- Node.js模块:随机动物实例教程与源码解析
