李志毅的SparkSQL与SparkStreaming实验报告
需积分: 0 172 浏览量
更新于2024-08-04
收藏 931KB DOCX 举报
"本次实验是2018211582号学生李志毅在2021年05月07日完成的SparkSQL和SparkStreaming实验,涉及RDD编程、JDBC连接MySQL数据库以及SparkStreaming统计词频的应用。实验过程中遇到了排序和数据库连接错误,通过分析和修改解决了问题。"
在此次实验中,李志毅同学主要进行了以下几个方面的学习和实践:
1. **RDD编程**:实验一中,他使用Scala编写程序实现了两个文本文件的数据合并与去重功能。在处理过程中,他遇到一个问题,即去重后的结果没有按第一列进行排序。最初,他只是简单地使用了`distinct()`方法,导致结果虽然正确但未排序。为了解决这个问题,他修改了程序,增加了排序操作,确保了结果按照第一列的顺序输出。这反映了对Scala语法和程序设计细节的深入理解和掌握的重要性。
2. **JDBC连接MySQL数据库**:在实验二中,李志毅在服务器上安装并配置了MySQL,然后编写Scala程序通过Spark的JDBC接口连接到数据库。在这个环节,他遇到了连接错误,原因是URL中的`localhost`拼写错误,缺少一个字母'l'。发现并修正这个错误后,他成功地向MySQL数据库写入了数据。这个错误提醒他在实验中需要更加仔细检查代码和配置。
3. **SparkStreaming应用**:实验三涉及到SparkStreaming的实战,他首先安装并启动了Kafka,然后编写Scala程序作为消费者来处理Kafka产生的流数据,统计词频。通过一个生产者终端发送词,消费者实时处理并显示统计结果。这个部分展示了SparkStreaming处理实时数据流的能力。
整个实验过程不仅锻炼了李志毅的编程技能,也提高了他对Spark生态系统的理解,包括RDD的处理逻辑、数据库交互以及实时流处理。同时,他从错误中吸取了教训,认识到实验前的充分准备和实验过程中的细致操作至关重要,这将有助于他在未来的学习和工作中避免类似错误,提升效率。
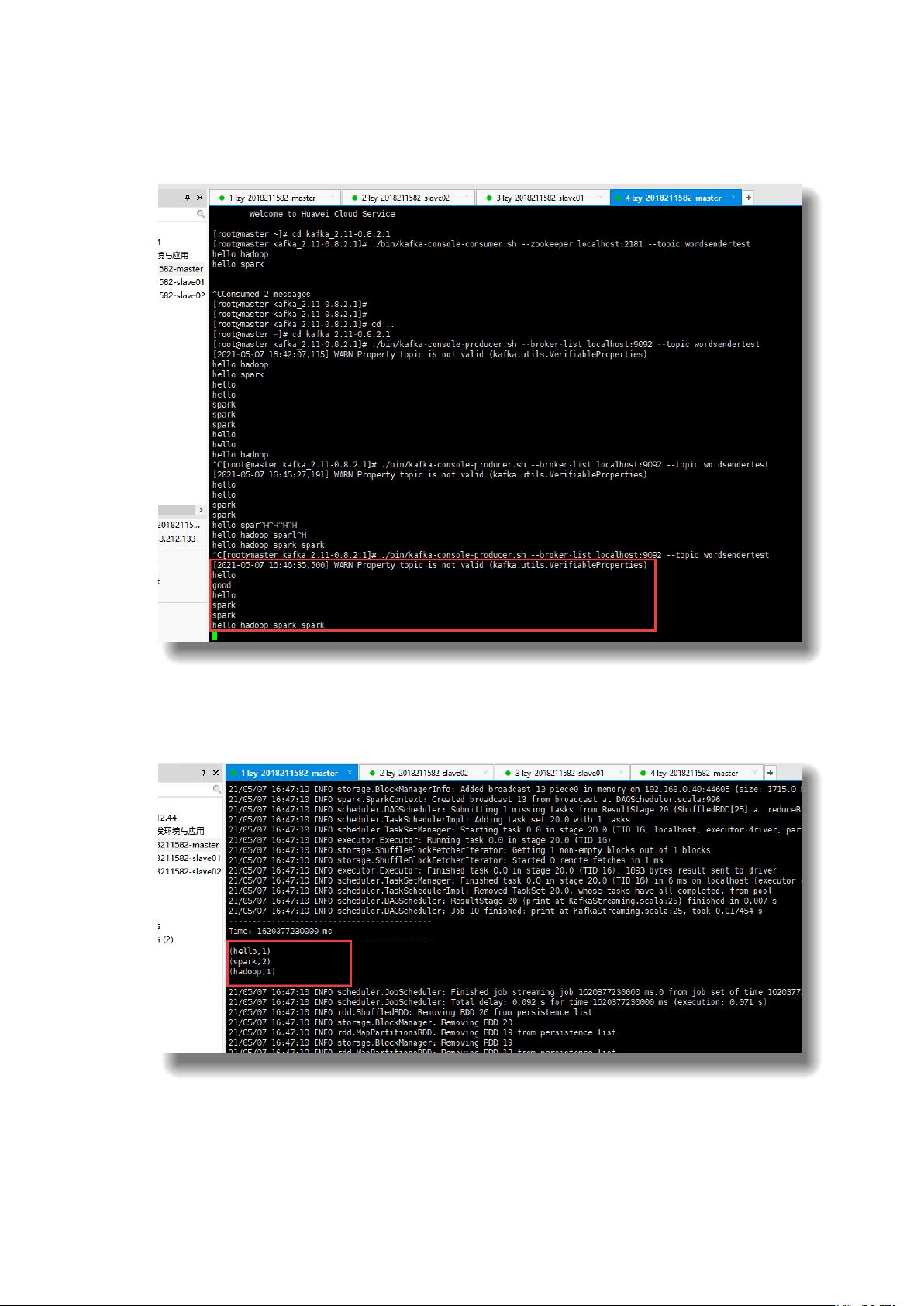
Spark Streaming 实验结果:
图五:生产者终端展示
图六:消费者统计词频结果
剩余11页未读,继续阅读
2022-08-03 上传
2022-08-03 上传
150 浏览量
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传

Orca是只鲸
- 粉丝: 36
 我的内容管理
展开
我的内容管理
展开







最新资源
- React.js实现的简单HTML5文件拖放上传组件
- iReport:强大的开源可视化报表设计器
- 提升代码整洁性:Eclipse虚线对齐插件指南
- 迷你时间秀:个性化系统时间显示与管理工具
- 使用ruby-install一次性安装多种Ruby版本
- Logality:灵活自定义的JSON日志记录器
- Mogre3D游戏开发实践教程免费分享
- PHP+MySQL实现的简单权限账号管理小程序
- 微信支付统一下单签名错误排查与解决指南
- 虚幻引擎4实现的多边形地图生成器
- TouchJoy:专为触摸屏Windows设备打造的屏幕游戏手柄
- 全方位嵌入式开发工具包:ARM平台必备资源
- Java开发必备:30个实用工具类全解析
- IBM475课程资料深度解析
- Java聊天室程序:全技术栈源码支持与学习指南
- 探索虚拟房屋世界:house-tour-VR应用体验
