视频无监督域自适应技术:VUDA探索与方法分类
版权申诉
105 浏览量
更新于2024-06-25
收藏 3.58MB PPTX 举报
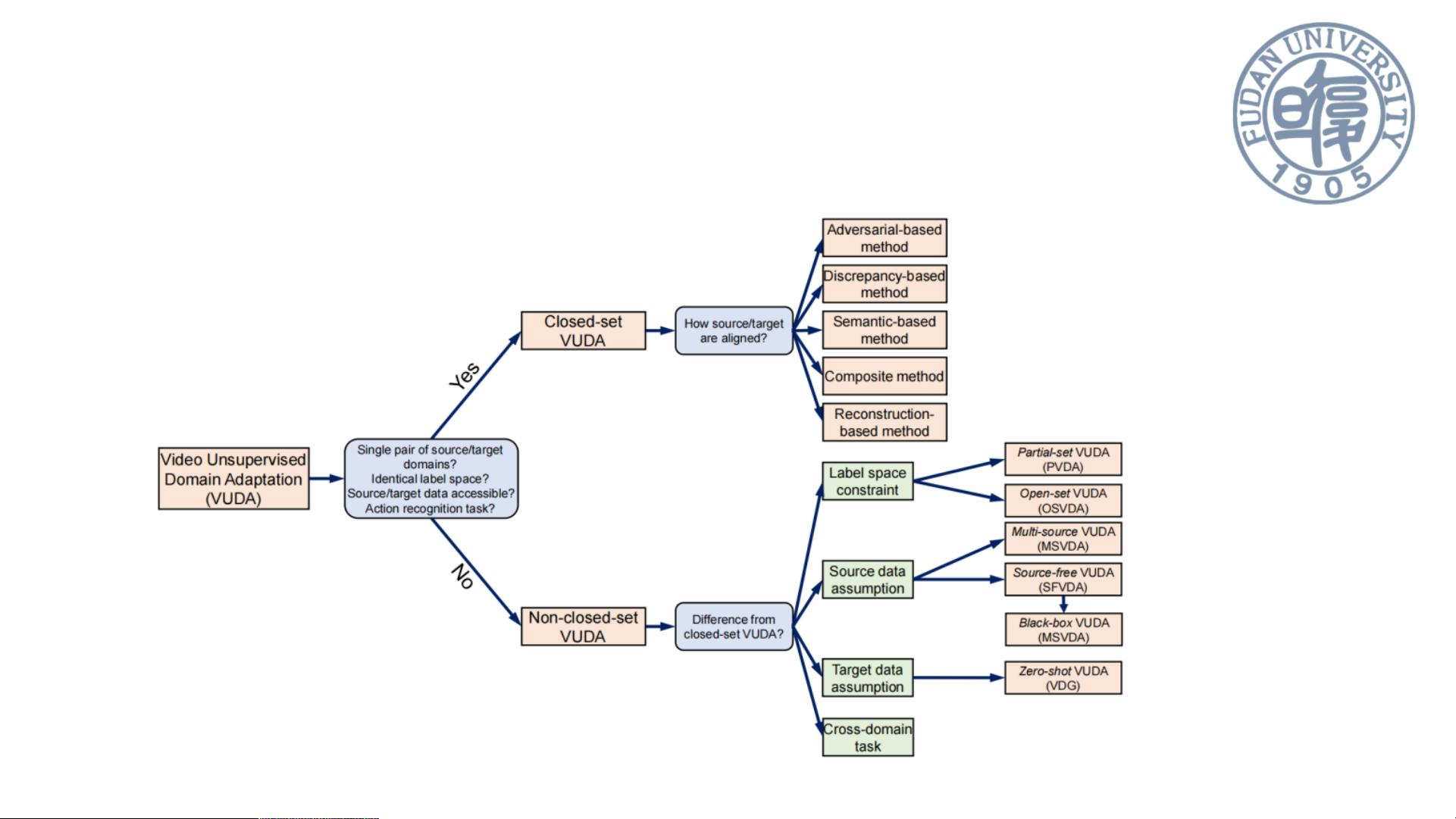
"本文主要探讨了视频无监督域自适应(VUDA)技术,这是一个针对视频数据集之间领域差异导致的模型性能下降问题的研究领域。VUDA旨在通过减少域偏移,提高视频模型的泛化能力和迁移性,适应无标记的目标视频域。文章列举了VUDA方法的五种主要类别,包括对抗方法、差异方法、语义方法、复合方法和基于重构的方法,并引用了三篇代表性论文:Spatio-temporal contrastive domain adaptation for action recognition (CVPR2021),Partial video domain adaptation with partial adversarial temporal attentive network (ICCV2021),以及Interact before align: Leveraging cross-modal knowledge for domain adaptive action recognition (CVPR2022)。特别是最后一篇论文,提出了跨模态交互式对齐(CIA)策略,强调了不同模态(如RGB、光流和音频)之间的互补性和可转移性,通过增强各模态的可转移知识来提升动作识别的准确性。"
视频无监督域自适应(VUDA)是解决视频模型在实际应用中的性能下降问题的关键技术,它主要应对的是由于训练数据(源域)和实际应用环境(目标域)之间的差异。由于视频数据集的标注成本高,使用无监督学习方法能有效地利用未标注的视频数据。VUDA方法的五种类别提供了不同途径来减小领域差异:
1. 基于对抗的方法利用生成器和域鉴别器的对抗训练,使生成的特征难以区分其来源,从而达到领域不变性。
2. 基于差异的方法通过计算源域和目标域之间的差异,利用度量学习方法优化两者间的匹配。
3. 基于语义的方法借助如互信息、聚类或对比学习等手段,确保领域不变特征满足语义约束。
4. 复合方法结合了上述多种方法的目标,寻求最优的域不变特征。
5. 基于重构的方法依赖于编码器,通过重构目标数据来提取领域不变特征。
在CVPR2022提出的跨模态交互式对齐(CIA)方法中,多模态信息(如RGB、光流和音频)被看作是互补的,它们各自的可转移性不同。通过MC模块,不同模态在对齐前互相学习,提升各自的可转移性,以更准确地识别动作。这种交互作用增强了模型在不同域间的泛化能力,尤其是在多模态信息结合的情况下,如音频可以帮助识别动作的动词,而RGB则有助于识别物体,两者的协同作用能够提高动作识别的准确性。
VUDA方法类别
剩余24页未读,继续阅读
2021-05-04 上传
2019-08-16 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-10-31 上传

猫头丁
- 粉丝: 2w+
- 资源: 21
 我的内容管理
展开
我的内容管理
展开







最新资源
- [PHP.5.&.MySQL.5基础与实例教程.随书光盘].PHP.5.&.MySQL.5
- [PHP.5.&.MySQL.5基础与实例教程.随书光盘].PHP.5.&.MySQL.5
- Core J2EE Patter.pdf
- 深入浅出struts2
- S7-200自由口通讯文档
- 在tomcat6.0里配置虚拟路径
- LR8.1 操作笔记
- ASP的聊天室源码,可进行聊天
- RealView® 编译工具-汇编程序指南(pdf)
- Java连接Mysql,SQL Server, Access,Oracle实例
- 易我c++,菜鸟版c++教程。
- 软件性能测试计划模板
- SUN Multithread Programming
- 城市酒店入住信息管理系统论
- Learning patterns of activity using real-time tracking.pdf
- bus hound5.0使用 bus hound5.0使用 bus hound5.0使用
