小规模TCAM实现快速正则表达式匹配
46 浏览量
更新于2024-07-15
收藏 2.4MB PDF 举报
"这篇研究论文探讨了如何使用小型TCAM(Ternary Content Addressable Memory,ternary内容可寻址存储器)实现快速的正则表达式匹配。TCAM是一种现成的芯片,广泛用于现代网络设备中的深度包检测和安全设备任务,如包分类。文章提出了三种创新技术,包括转换共享、表合并和可变步进,以减少TCAM空间并提高正则表达式匹配速度。在实际测试中,这些技术能够将八个具有25000个状态的实际世界正则表达式集存储在0.59 Mb的TCAM芯片中,并实现高正则表达式匹配吞吐量。"
本文的焦点在于解决正则表达式匹配效率问题,特别是在现代网络和安全设备中。正则表达式匹配是深度包检测的重要组成部分,它允许设备识别和分析网络流量中的模式。然而,随着网络流量的增加和复杂性的提高,对快速且高效匹配的需求也相应增加。
TCAM作为一种特殊的内存类型,因其快速查找和匹配能力而被广泛应用于网络设备中。然而,大型TCAM的使用可能会导致成本和功耗的增加,因此,论文提出使用小型TCAM来实现高效的正则表达式匹配,这是对现有技术的一个重要补充。
首先,转换共享(Transition Sharing)技术旨在通过共享TCAM条目来减少存储需求。正则表达式转换可以有多个相同的前缀或后缀,这种共享可以减少存储这些重复部分所需的存储空间。
其次,表合并(Table Consolidation)是一种优化方法,它整合了多个相似或相关的正则表达式,将其合并到一个更大的表中,从而进一步节省TCAM空间。
最后,可变步进(Variable Striding)技术可能涉及到调整查询时的步进大小,以适应不同的正则表达式结构,从而提高匹配速度,尤其对于具有不同复杂度的正则表达式集合。
实验结果表明,这三项技术的有效结合使得小型TCAM可以存储大规模的确定有限自动机(DFA),并且仍然能够提供高的匹配性能。具体来说,八个具有25000个状态的DFA能够在0.59 Mb的TCAM中得到存储,这意味着在不牺牲性能的前提下,显著降低了硬件资源的需求。
该研究论文提出的策略为正则表达式匹配提供了新的解决方案,尤其是在资源有限的环境中,这对于优化现代网络设备的性能和效率具有重要意义。通过这些技术,可以实现更高效、更节省空间的正则表达式匹配,这对于网络监控、安全防护以及数据处理等领域都有重要的应用价值。
This article has been accepted for inclusion in a future issue of this journal. Content is final as presented, with the exception of pagination.
4 IEEE/ACM TRANSACTIONS ON NETWORKING
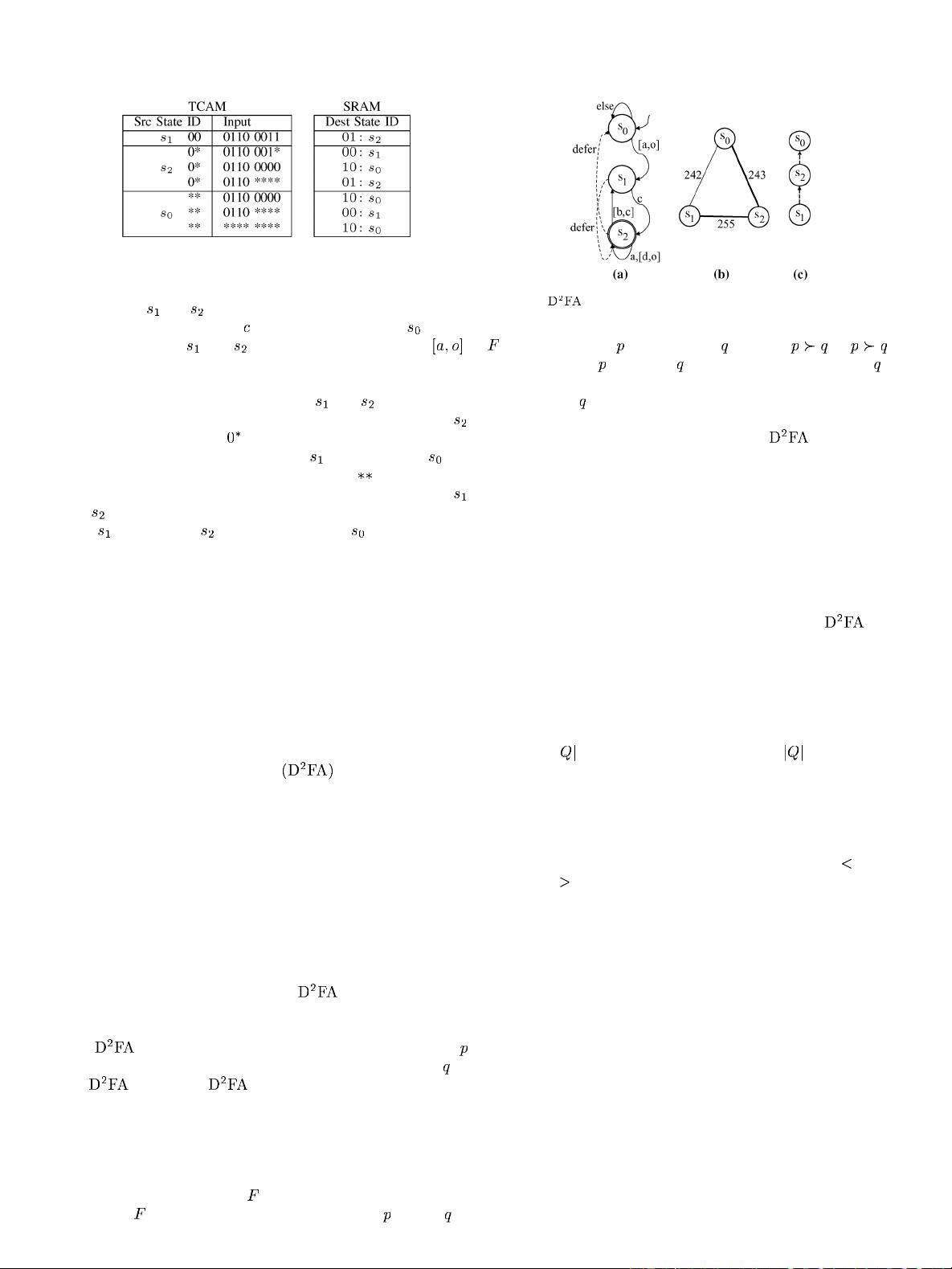
Fig. 2. TCAM table w ith shadow encoding.
source states and have the same destination state except for
the transitions on character
. L ikewise, source state differs
from source states
and only in the character range .
This implies there is a lot of state redundancy. The table in Fig. 2
shows how we can exploit state redundancy to further reduce re-
quired TCAM space. First, since states
and aremoresim-
ilar, we give them the state IDs 00 and 0 1, respectively. State
uses the ternary code of in the state ID fiel d of its TCAM
entries to share transitions with state
. We give state the
state ID of 10, and i t uses the ternary code of
in the state ID
field of its TCAM entries to share transitions with both states
and . Second, we order the state tables in the TCAM so that
state
is first, state is second, and state is last. This fa-
cilitates the shar ing of transitions among different states where
earlier states have incomplete tables deferring some transitions
to later tables.
In the rest of this section, we solve the following three prob-
lems in order to implem e nt shadow encoding: 1) Find the best
order of the state tables in the TCAM (any order is allowed).
2) Choose binary IDs and ternary codes for each state given the
state table order. 3) Identify entries to remove from each state
table.
Our shadow encoding techniqu e builds upon prior work with
default tran s itions [3], [5]–[7] b y exploiting the same state r e-
dundancy observation and using their concepts of default tran-
sitions and Delayed input DFAs
. However, our final
technical solutions are different because we work w ith TCAM,
whereas prior techniques work w ith RAM. For example, t he
concept of a ternary state code has no meaning when working
with RAM. The key advantage of shadow enco ding in TCAM
over prior default transition work is speed. Shado w encoding in
TCAM incurs no delay, whereas prior default transition tech-
niques incur significant delay because a DFA may have to tra-
verse multiple default transitions before con s um ing an input
character.
2) Determining Table Order: We first describe how we com-
pute the order of tables within the TCAM. We use some con-
cepts such as default transitions and
that were originally
definedbyKumaret al. [5] and subs equen tly refined in [3], [6],
and [7].
A
is a DFA with default transitions where each state
can have at most one default transition to one other state in
the
.Inalegal , the directed graph consisting of
only default transitions must be acyclic; we call this graph a
deferment forest. It is a forest rather than a tree since mo re than
one node may not have a default transition. We call a tree in a
deferment forest a deferment tree.
We determine the order of state tab les in TCAM by con-
structing a deferment forest
and then using the partial order
defined by
. If there is a directed path from state to stat e in
Fig. 3. (a) , (b) SRG, and (c) deferm ent tree of the DFA in Fig. 1.
, we say that state defers to state , d enoted .If ,
we say that state
is in state ’s shadow. Specifically, state ’s
transition table must be placed after the transition tables of all
states in state
’s shadow.
Our algorithm to compute a deferment forest that minimizes
the TCAM representation o f the resu lti ng
builds upon
algorithms from prior work [3], [5]–[7], but there are several
key differences. First, u nlike prior work, we do not pay a speed
penalty for long default transition paths. Thus, we achieve better
transition sharing than prior work. Second, t o maximize the po-
tential gains f ro m our variable striding technique described in
Section V and table consolidation, we choose states that have
lots of self-loop s to be the roots of our deferment trees. Prior
work has typically chosen roots in order to minimize the dis-
tance from a leaf node to a root, though Becchi and Crowley
do consider related criteria w hen constructing their
[3].
Third, we explicitly ig nor e tra nsit ion s har ing bet w een st ates th at
have few transitions in common. This has been done implicitly
in the past, but we show how doing so leads to better results
with table consolidation.
Our algorithm consists of four steps. First, we construct a
space reduction graph (SRG) [5] f ro m a given DFA. Given a
DFA with
states, an SRG is a clique with vertices each
representing a distinct state. The weight of each edge is the
number of comm on outgoing transitions between the two con-
nected states. Second, w e trim away edges with small weight
from the SRG. In our experim ents, we use a cutoff of 10. This
pruning is effective because the distribution of edge weights in
our experiments is bim odal: usually either very small (
10) or
very large (
180). Using these low weight edges as default tran-
sitions leads to m ore TCAM entries and reduces the number
of deferment trees which hinders our table consolidation tech-
nique (Section IV). Third, we compute a deferme nt forest b y
running Kruskal’s algorithm to find a maximum weight span-
ning forest. Fourth, for each deferment tree, we pick the state
that has largest number of transiti ons going back to itself as the
root. Fig. 3(b) and (c) shows the SRG and the defermen t tree,
respectively, for the DFA in Fig. 1.
In most deferment trees, m ore than 128 (i.e., half) of the root
state’s outgoing transitions lead back to the r oot state; we call
such a s tate a self-looping state. Based on the pigeonhole prin-
ciple and the observed bimodal distribution, each deferment tree
typically has exactly one self-looping state, and it is the root
state. We choose self-looping states as ro ots to improve the ef-
fectiveness of variable striding, which we describe in Section V.
When we apply Kruskal’s algorithm, we use a tie-breaking
strategy because many edges have the same weight. To have
most deferment trees centered around a self-looping state, we
剩余15页未读,继续阅读
2021-01-14 上传
2021-07-13 上传
2022-09-20 上传
2021-05-09 上传
2022-09-14 上传
2015-05-04 上传
2021-10-08 上传
2010-11-08 上传

weixin_38682953
- 粉丝: 7
- 资源: 986
 我的内容管理
展开
我的内容管理
展开







最新资源
- zlib-1.2.12压缩包解析与技术要点
- 微信小程序滑动选项卡源码模版发布
- Unity虚拟人物唇同步插件Oculus Lipsync介绍
- Nginx 1.18.0版本WinSW自动安装与管理指南
- Java Swing和JDBC实现的ATM系统源码解析
- 掌握Spark Streaming与Maven集成的分布式大数据处理
- 深入学习推荐系统:教程、案例与项目实践
- Web开发者必备的取色工具软件介绍
- C语言实现李春葆数据结构实验程序
- 超市管理系统开发:asp+SQL Server 2005实战
- Redis伪集群搭建教程与实践
- 掌握网络活动细节:Wireshark v3.6.3网络嗅探工具详解
- 全面掌握美赛:建模、分析与编程实现教程
- Java图书馆系统完整项目源码及SQL文件解析
- PCtoLCD2002软件:高效图片和字符取模转换
- Java开发的体育赛事在线购票系统源码分析
