深入解析transformer神经网络:结构、应用及序列到序列模型介绍
下载需积分: 5 | PPTX格式 | 7.46MB |
更新于2024-03-12
| 40 浏览量 | 举报
长短期记忆神经网络(LSTM)和transformer模型是目前在自然语言处理领域应用广泛的神经网络模型。在序列到序列(Sequence-to-Sequence)任务中,我们需要处理输入和输出数据都为序列的情况。全连接神经网络和卷积神经网络处理的是互相独立且完整的样本,而在序列到序列任务中,输入和输出都是向量序列,因此需要使用特定的模型来解决这类问题。
在序列到序列任务中,常见的模型有以下几种类型:输入向量序列与输出向量序列长度一致,如词性分析;输入向量序列长度不定,输出向量序列长度为1,如文本分类;输入和输出向量序列长度均不固定,如机器翻译。对于语音数据,常用的编码方法是将语音数据分段提取特征,得到语音的向量序列;对文本数据,则常常将每个单词映射为特征向量,这一过程被称为Word Embedding,使得具有相似语义的单词在特征空间中距离较近。
transformer模型是一种基于自注意力机制的神经网络结构,能够更好地处理序列到序列任务。在transformer模型中,输入序列和输出序列通过多层的encoder-decoder结构相互转换,并利用自注意力机制来捕捉序列中的长距离依赖关系。transformer模型的核心是self-attention机制,它能够在计算编码器和解码器之间的关联时对输入序列的不同部分赋予不同的重要性。
在transformer模型中,encoder由多个相同的encoder模块堆叠而成,每个encoder模块包含一个self-attention层和一个全连接前馈网络。decoder也由多个相同的decoder模块堆叠而成,每个decoder模块包含三个部分:一个self-attention层用于捕捉输入序列的依赖关系,一个encoder-decoder attention层用于对编码器输出进行关联,一个全连接前馈网络用于生成输出序列中的下一个元素。
总的来说,transformer模型通过自注意力机制实现了对序列中各个元素之间复杂依赖关系的建模,使得在自然语言处理领域的任务中取得了令人瞩目的成绩。长短期记忆神经网络和transformer模型的结合将进一步推动自然语言处理技术的发展,为机器翻译、情感分析等任务提供更加准确和高效的解决方案。

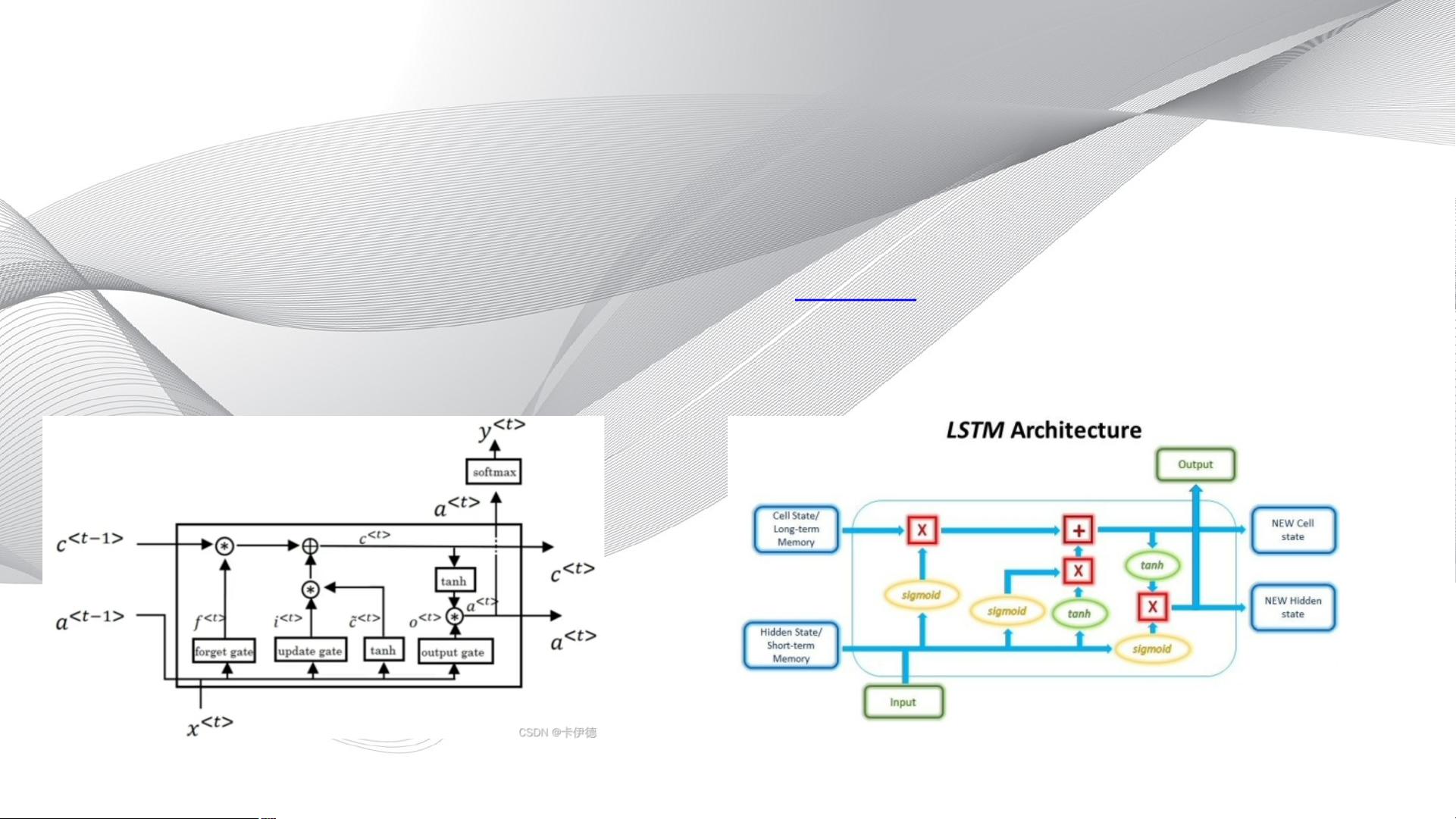
16.2 长短期记忆网络LSTM
RNN的缺陷
• 介绍RNN中,虽然实现了对序列数据的处理,但其自身的结构却存在严重的缺陷
• 1.当模型的参数值较大时,经过指数缩放后
得到一个很大的梯度值,使得网络参数剧烈
地调整,而这种大幅度调整往往使得模型泛
化性能更差,进而得到更大的训练误差,造
成恶性循环,最终模型无法收敛。这种情况
称为梯度爆炸;
• 2.当模型的参数值较小时,经
过指数级缩放后趋于零,此时
网络参数将几乎不发生变化,
即模型收敛到一定程度后就难
以继续优化了,这种情况称为
梯度消失。
• 为了避免发生梯度爆炸与梯度消失问题,RNN一般仅适用于处理长度较短的序列数据,也
可说RNN只具有“短期记忆”的能力。

剩余57页未读,继续阅读
相关推荐




雨下成一朵花
- 粉丝: 1379
 我的内容管理
展开
我的内容管理
展开







最新资源
- 自动生成CAD模型文件的测试流程
- 掌握JavaScript中的while循环语句
- 宜科高分辨率编码器产品手册解析
- 探索3CDaemon:FTP与TFTP的高效传输解决方案
- 高效文件对比系统:快速定位文件差异
- JavaScript密码生成器的设计与实现
- 比特彗星1.45稳定版发布:低资源占用的BT下载工具
- OpenGL光源与材质实现教程
- Tablesorter 2.0:增强表格用户体验的分页与内容筛选插件
- 设计开发者的色值图谱指南
- UYA-Grupo_8研讨会:在DCU上的培训
- 新唐NUC100芯片下载程序源代码发布
- 厂家惠新版QQ空间访客提取器v1.5发布:轻松获取访客数据
- 《Windows核心编程(第五版)》配套源码解析
- RAIDReconstructor:阵列重组与数据恢复专家
- Amargos项目网站构建与开发指南
