Lucene原理与代码分析详解
需积分: 26 53 浏览量
更新于2024-07-26
收藏 4.73MB PDF 举报
"Lucene 原理与代码分析完整版.pdf"
Lucene 是一个高性能、全文本搜索引擎库,由Apache软件基金会开发并维护。它是一个Java实现的开源工具,允许开发者在自己的应用中添加强大的搜索功能。Lucene的运作机制基于全文检索的基本原理,包括索引构建和查询处理两个主要阶段。
**全文检索的基本原理**
1. **总论**:全文检索是一种通过索引来快速查找文档中包含特定词汇的技术。Lucene通过建立倒排索引(Inverted Index)来加速搜索过程。
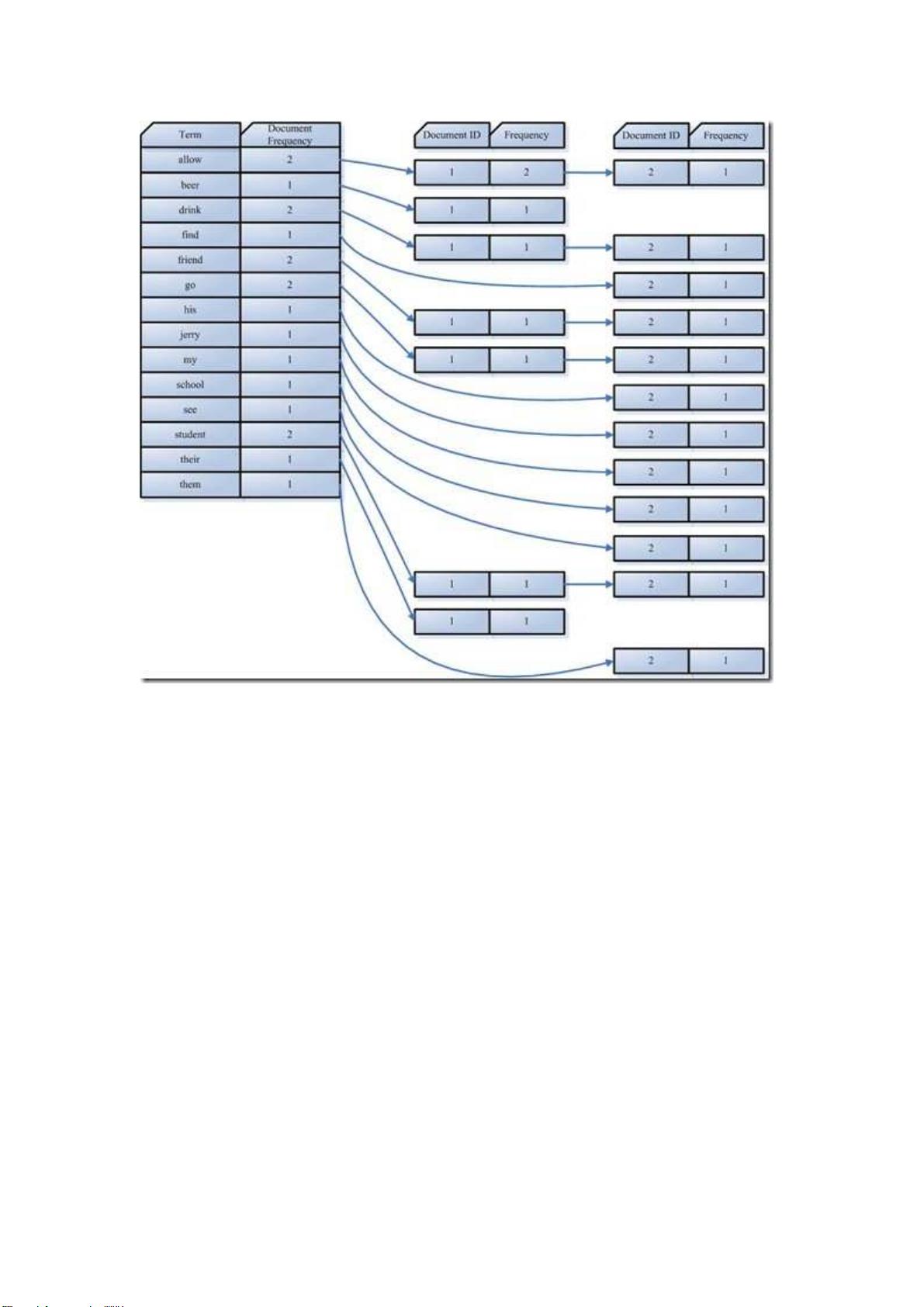
2. **索引里面究竟存些什么**:索引主要存储两部分数据,字典(Dictionary)和文档倒排列表(Posting List)。字典包含所有独特的词元(Term),而文档倒排列表记录了每个词元出现在哪些文档以及在文档中的位置。
3. **创建索引**:索引过程包括四个步骤:
- 将原文档转换成词元。
- 对词元进行语言处理,如词干提取、停用词过滤等。
- 创建词元到文档的映射,即倒排索引。
- 整理索引数据结构,如排序和压缩,以提高搜索效率。
**搜索过程**
1. **用户输入查询**:用户提交查询字符串,系统对其进行词法和语法分析,同时可能涉及语言处理。
2. **查询处理**:查询语句被解析成词元,然后在索引中查找匹配的文档,生成初始的候选结果集。
3. **相关性计算**:使用向量空间模型(VSM)计算每个文档与查询的相似度,通过TF-IDF等权重算法对结果进行排序。
**Lucene的总体架构**
Lucene的架构主要包括以下几个组件:
- 分析器(Analyzer):负责将原始文本拆分成可搜索的词元。
- 索引器(IndexWriter):创建和更新索引。
- 查询解析器(QueryParser):处理用户的查询,生成查询对象。
- 搜索器(Searcher):执行查询并返回结果。
**Lucene的索引文件格式**
索引文件包含各种数据结构,如字典文件、文档频率文件、位置文件等,采用特定的编码规则,如前缀后缀编码(Prefix+Suffix)、差值编码(Delta)和或然跟随规则等,以节省存储空间并提高读取速度。
**代码分析篇**
这部分深入到Lucene的源码层面,分析其内部实现细节,包括索引文件的具体编码方式、搜索算法的实现以及各组件间的交互逻辑等。
理解Lucene的工作原理和代码实现对于优化搜索性能、自定义分析流程和解决搜索相关问题至关重要。通过深入学习,开发者可以更好地利用Lucene来构建高效、定制化的搜索解决方案。

16
到相同的转换。
语言处理组件(linguistic processor)的结果称为词(Term)。
在我们的例子中,经过语言处理,得到的词(Term)如下:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,
“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
也正是因为有语言处理的步骤,才能使搜索 drove,而 drive 也能被搜索出来。
第四步
第四步第四步
第四步:
::
:将得到的词
将得到的词将得到的词
将得到的词(Term)传给索引组件
传给索引组件传给索引组件
传给索引组件(Indexer)。
。。
。
索引组件(Indexer)主要做以下几件事情:
1. 利用得到的词
利用得到的词利用得到的词
利用得到的词(Term)创建一个字典
创建一个字典创建一个字典
创建一个字典。
。。
。
在我们的例子中字典如下:
Term Document ID
student 1
allow 1
go 1
their 1
friend 1
allow 1
drink 1
beer 1
my 2
friend 2


剩余526页未读,继续阅读
2018-04-19 上传
2021-09-18 上传
2023-05-25 上传
2023-06-01 上传
2023-05-30 上传
2023-05-10 上传
2023-06-11 上传
2024-05-26 上传
2023-05-29 上传

xyhexx
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 计算机软件-编程源码-金科信进销存软件.zip
- positions:GLPI的插件位置
- 强大的电子类工具资料聚合应用 电路专家 for Android .rar
- loicsammut_5_05032021
- bjpglib27_back_code_源码
- lucene-misc-7.3.1.jar中文-英文对照文档.zip
- 基于java的-653-学生综合测评系统--LW-源码.zip
- [江苏]绿色社区+公园生活住宅商业投标方案
- 【创新发文无忧】Matlab实现牛顿拉夫逊优化算法NRBO-DELM的故障诊断算法研究.rar
- 行业分类-设备装置-多媒体数据传输方法.zip
- reacticons-batch:甚至是React堆!
- 使用原子预选择实现音频匹配追踪算法的资料概述-综合文档
- user_dashboard
- SSMS_JavaEE_MYSQL_jsp_
- 行业分类-设备装置-大豆蛋白型水性装饰纸油墨的制造方法.zip
- netty-codec-4.1.16.Final.jar中文-英文对照文档.zip
