理解并选择AWS分布式数据存储:冗余、挑战与AWS选项详解
64 浏览量
更新于2024-08-28
收藏 223KB PDF 举报
"本文是一篇针对普通读者的关于分布式数据存储的深入讲解,作者针对AWS众多数据存储选项产生的困扰进行剖析。文章分为三个部分:第一部分介绍了高可用性的基本概念和冗余的重要性,以及冗余在数据层带来的新问题。作者强调了在追求高可用性的同时,需要理解和权衡冗余带来的挑战。
第二部分详细讨论了关系型数据库(RDB)的传统优势,如高度一致性事务的支持,以及其随着时代发展所增加的新功能,如BLOB存储和地理空间扩展。然而,随着互联网的发展,RDB的局限性开始显现,特别是对于可用性、性能和扩展性的需求。性能问题在互联网时代变得更加关键,需要更大规模的技术来支撑,这与RDB原本依赖于垂直扩展(scale-up)的方式相冲突。
第三部分则是AWS特定的数据存储选项分析,作者将探讨如何根据不同的工作负载选择最合适的存储服务,如NoSQL数据库、对象存储、列式存储等,这些都是为了解决单机限制和满足现代应用的扩展性和性能需求而设计的。通过这一系列的讲解,读者不仅能理解各种存储选项的优缺点,还能学习到如何在实际场景中做出明智的选择。
总结来说,本文旨在帮助读者理解分布式数据存储的复杂性,引导他们基于业务需求和工作负载特性来挑选适合的AWS存储解决方案,以便在数据管理中实现最佳实践。"
讲给普通人听的分布式数据存储讲给普通人听的分布式数据存储
摘要:简单易懂,十分靠谱.AWS有这么多数据存储选项,针对你正确的工作负载选最适合你的那一个!
Neo,这就是让我们心烦的问题
为什么AWS有这么多的数据存储选项?我应该用哪个?这些是客户常见的问题。在这分成三部分的博客系列中,我将试图做
一些澄清。在第一部分,我会论述高可用性的基础,以及为什么冗余是实现高可用性的常用方法。我也简要地提到在数据层加
入冗余会带来新的问题。在本博客系列的第二部分,我会讨论这其中的一些问题,以及在克服这些问题时你需要考虑的取舍。
本博客系列的第三部分在这些信息的基础上,论述AWS特定的数据存储选项,以及每个存储选项的优化所针对的是哪些工作
负载。在你读完本博客系列的全部三部分之后,你就会赞同AWS提供了丰富的数据存储产品,并学会针对正确的工作负载选
择正确的选择。
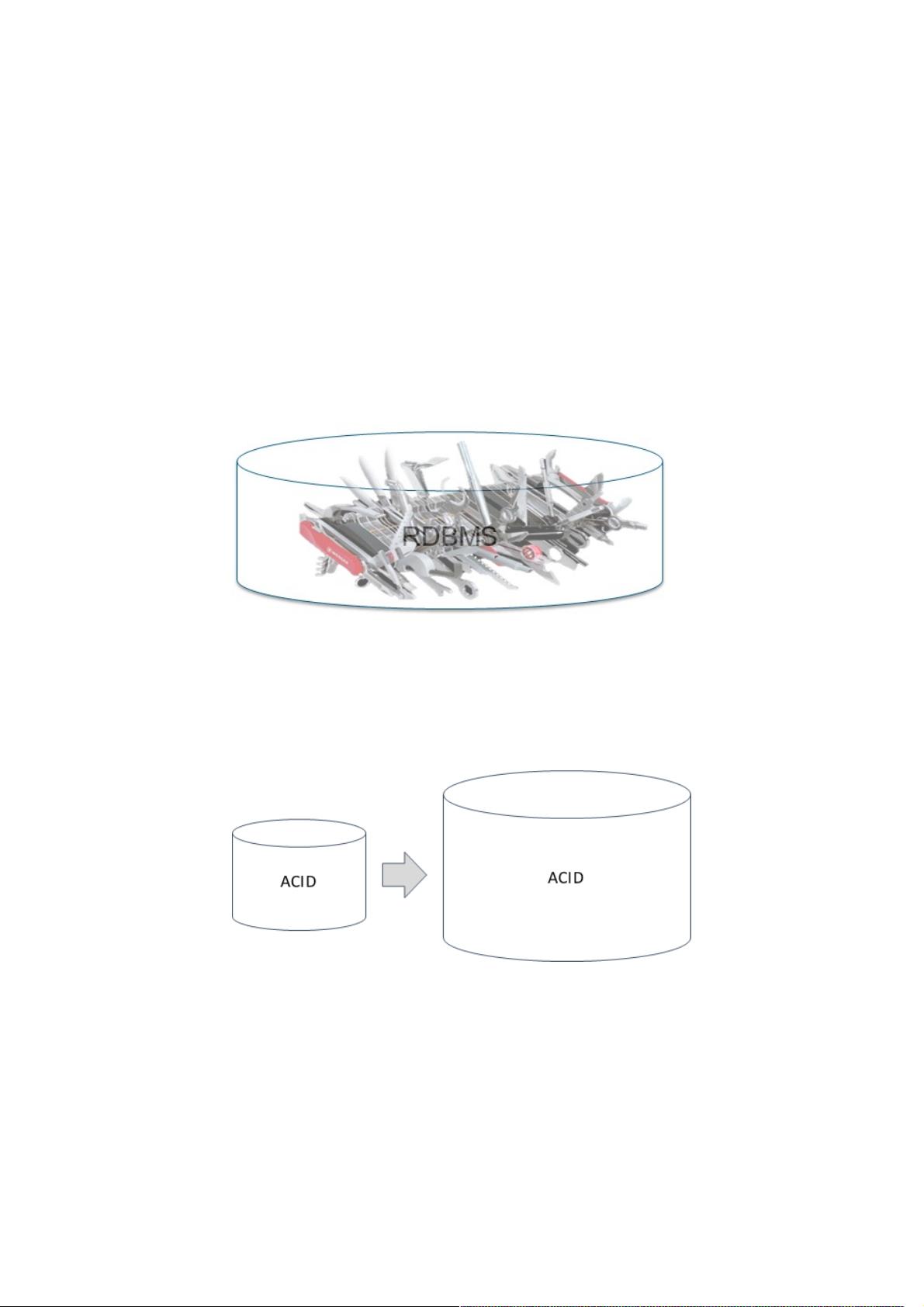
关系型数据库到底有什么问题?
正如你们中的很多人可能已经知道的,关系型数据库(RDB)技术自从1970年代就已经存在,直到1990年代末一直是结构化
存储的事实标准。RDB几十年来很出色地支持了高度一致性事务的工作负载,并依然保持强劲。随着时间的推移,该项古老
的技术为应对客户的需求获得了新的能力,比如BLOB存储、XML/文档存储、全文检索、在数据库中执行代码、使用星形数据
结构的数据仓库、以及地理空间扩展。只要一切都能挤进关系型数据结构的定义中,并且适合于单机,就可以在关系型数据库
中实现。
然后,互联网的商业化发生了,并且彻底改变了一切,使得关系型数据库不再能够满足所有的存储需求。相比于一致性,可用
性、性能和扩展正在变得同样重要--有时甚至更重要。
性能一直很重要,但是随着互联网商业化的出现,改变的是规模。事实证明,要达到规模化的性能,要求的技巧和技术是前互
联网时代无法接受的。关系型数据库围绕着ACID(原子性Atomicity、一致性Consistency、隔离性Isolation和持久性
Durability)的概念而建立,实现ACID最简单的方法就是把一切保持在单机上。因此,传统的RDB规模化的方法是垂直扩展
(scale up),用白话说,就是使用更大的机器。
哦-哦,我想我需要一台更大的机器
使用一台更大的机器的解决方案一直很好,直到互联网带来的负载大到单机无法处理。这迫使工程师们想出巧妙的技术来克服
单机的限制。有许多不同的方法,各有其优缺点:主—副、集群、表联合与分区(table federation and partitioning)、水平
分区(sharding,可以认为是分区的特例)。
下载后可阅读完整内容,剩余3页未读,立即下载
2023-08-28 上传
2012-05-30 上传
点击了解资源详情
点击了解资源详情
2024-11-12 上传
2024-11-12 上传
2024-11-12 上传

weixin_38595850
- 粉丝: 7
- 资源: 900
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
