胶囊图神经网络:提升图嵌入性能
需积分: 45 158 浏览量
更新于2024-07-17
1
收藏 1.93MB PDF 举报
"胶囊图神经网络(Capsule Graph Neural Network, CapsGNN)是一篇于2019年在国际计算机视觉与模式识别会议(ICLR)上发表的研究论文。该工作由张欣怡和李辉(来自新加坡南洋理工大学电气与电子工程学院)提出,其研究背景是针对图神经网络(GNN)在生成图嵌入时存在的局限性。GNNs在学习高质量节点嵌入方面表现出色,被广泛应用于各种基于节点的任务,并在一些场景下达到了最先进的性能。然而,当将GNN学习到的节点嵌入用于生成全局的图嵌入时,传统的标量表示可能不足以有效地保留节点和图的复杂属性,从而导致图嵌入效果不理想。
作者受Capsule Neural Network (CapsNet, Sabouret al., 2017) 的启发,提出了CapsGNN。核心思想在于借鉴胶囊网络的结构,通过胶囊形式来提取节点特征,而非仅仅依赖单一的标量表示。胶囊网络的特点在于它能够捕捉和表达物体的不同部分及其相对关系,这使得CapsGNN能够在处理图数据时更好地捕捉图形结构的全局信息。
CapsGNN利用路由机制,通过对胶囊进行动态分配和聚合,生成多个图嵌入,每个嵌入代表图的不同方面或层次,这样不仅增加了模型的表达能力,还能更好地反映出图的内在复杂性和结构特征。这种方法旨在改进现有的GNN方法,提升图嵌入的质量和适应性,使之更适用于各种图数据分析任务,如社区检测、节点分类和图聚类等。该研究在图神经网络领域引入了新的视角和方法,有望推动图学习算法的进一步发展和优化。"
Published as a conference paper at ICLR 2019
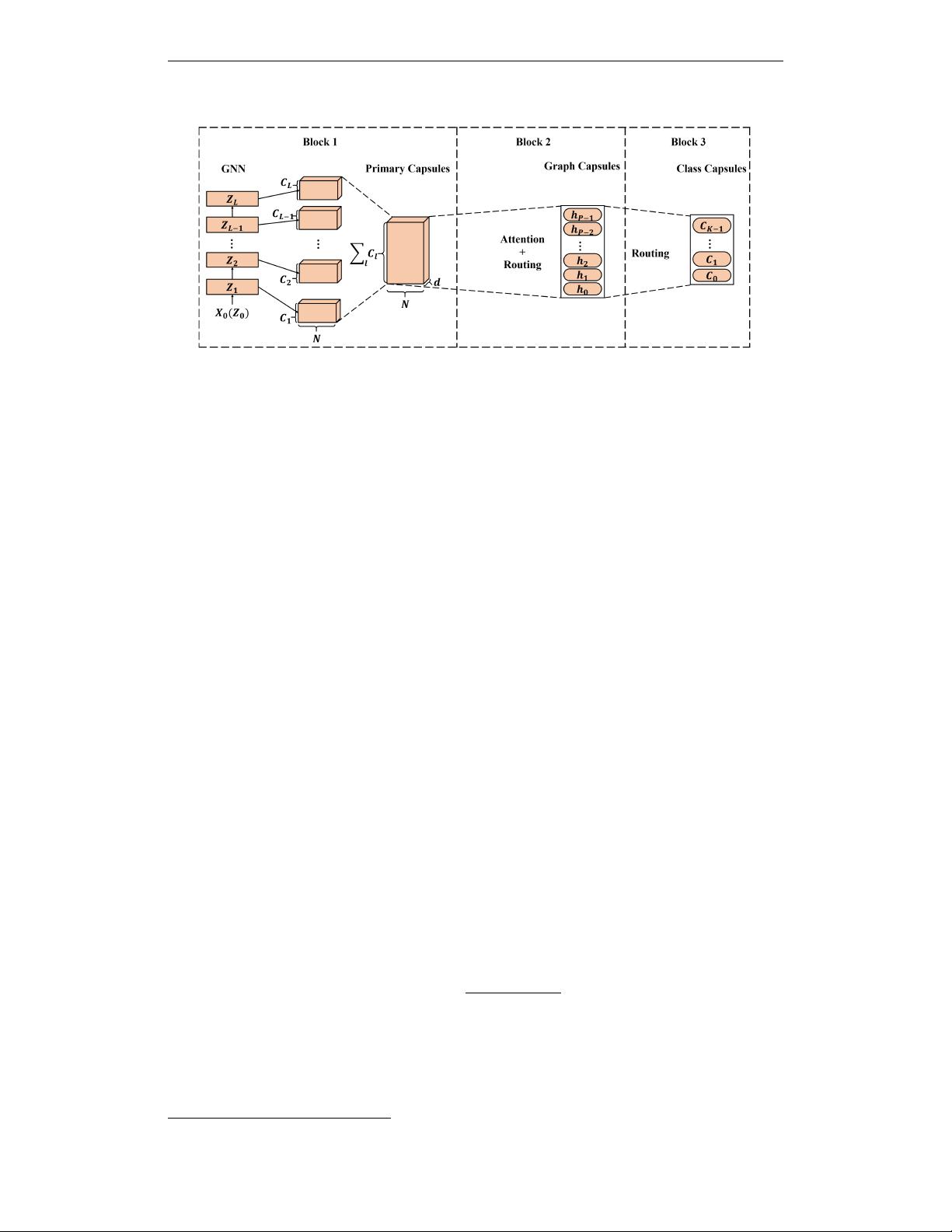
Figure 1: Framework of CapsGNN. At first, GNN is used to extract node embeddings and form
primary capsules. Attention module is used to scale node embeddings which is followed by Dynamic
Routing to generate graph capsules. At the last stage, Dynamic Routing is applied again to perform
graph classification.
where W
l
ij
∈ R
d×d
0
is the trainable weights matrix. It serves as the channel filters from the ith
channel at the lth layer to the jth channel at the (l + 1)th layer. Here, we choose f (·) = tanh(·)
as the activation function. Z
l+1
∈ R
N×d
0
, Z
0
= X,
˜
A = A + I
1
and
˜
D =
P
j
˜
A
ij
. To
preserve features of sub-components with different sizes, we use nodes features extracted from all
GNN layers to generate high-level capsules.
3.2 HIGH-LEVEL GRAPH CAPSULES
After getting local node capsules, global routing mechanism is applied to generate graph capsules.
The input of this block contains N sets of node capsules, each set is S
n
= {s
11
, .., s
1C
1
, ..., s
LC
L
},
s
lc
∈ R
d
, where C
l
is the number of channels at the lth layer of GNN, d is the dimension of each
capsule. The output of this block is a set of graph capsules H ∈ R
P ×d
0
. Each of the capsules
reflects the properties of the graph from different aspects. The length of these capsules reflects
the probability of the presence of these properties and the angle reflects the details of the graph
properties. Before generating graph capsules with node capsules, an Attention Module is introduced
to scale node capsules.
Attention Module. In CapsGNN, primary capsules are extracted based on each node which means
the number of primary capsules depends on the size of input graphs. In this case, if the routing
mechanism is directly applied, the value of the generated high-level capsules will highly depend on
the number of primary capsules (graph size) which is not the ideal case. Hence, an Attention Module
is introduced to combat this issue.
The attention measure we choose is a two-layer fully connected neural network F
attn
(·). The num-
ber of input units of F
attn
(·) is d × C
all
where C
all
=
P
l
C
l
and the number of output units equals
to C
all
. We apply node-based normalization to generate attention value in each channel and then
scale the original node capsules. The details of Attention Module is shown in Figure 2 and the
procedure can be written as:
scaled(s
(n,i)
) =
F
attn
(
˜
s
n
)
i
P
n
F
attn
(
˜
s
n
)
i
s
(n,i)
(3)
where
˜
s
n
∈ R
1×C
all
d
is obtained by concatenating all capsules of the node n. s
(n,i)
∈ R
1×d
represents the ith capsule of the node n and F
attn
(
˜
s
n
) ∈ R
1×C
all
is the generated attention value. In
this way, the generated graph capsules can be independent to the size of graphs and the architecture
will focus on more important parts of the input graph.
1
I represents identity matrix.
4
剩余15页未读,继续阅读
2024-07-20 上传
2020-04-08 上传
2024-04-11 上传
2024-03-25 上传
2023-06-09 上传
2023-05-27 上传
2023-03-24 上传
2023-07-25 上传

小牧户
- 粉丝: 0
- 资源: 13
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
