混沌时间序列预测:教学学习优化与差分进化融合算法
147 浏览量
更新于2024-07-15
收藏 732KB PDF 举报
"本文提出了一种混合教学学习优化(Teaching-Learning-Based Optimization, TLBO)和差分进化(Differential Evolution, DE)算法用于混沌时间序列预测的新方法。该方法将两种算法的优势结合,旨在解决混沌系统预测中的非线性、多变量和多模态优化问题,以避免陷入局部最优。"
在混沌理论中,时间序列预测是一个具有挑战性的领域,因为混沌系统表现出高度的敏感性和复杂性。混沌时间序列预测问题的特性使其成为近年来研究的热点。基于相空间重构的预测方法已被广泛应用于多个科研领域,但预测混沌系统本质上是一个非线性、多变量且多模态的优化问题,这要求使用能够全局搜索的优化技术来规避局部最优解。
教学学习优化算法(TLBO)是一种模拟教师指导学生学习过程的全局优化算法,它通过模仿教师传授知识和学生之间相互学习的过程来寻找最优解。然而,当面对复杂的优化问题时,TLBO可能会陷入停滞状态,即无法进一步改善解决方案。
差分进化算法(DE)则是一种强大的全局优化工具,尤其擅长处理连续函数优化问题。DE通过变异、交叉和选择操作,能够有效地探索解决方案空间,从而跳出局部最优。
本文提出的新混合算法TLBO-DE,将DE的全局搜索能力与TLBO的学习机制相结合。DE被用来更新个体的先前最佳位置,促使TLBO跳出可能的停滞状态,同时利用TLBO的适应度函数和学习策略来引导种群向更好的解决方案演化。这种融合使得算法在处理混沌时间序列预测时,既能保持全局搜索能力,又能有效避免陷入局部最优。
通过实验验证,TLBO-DE在混沌时间序列预测上的表现优于单独使用TLBO或DE,证明了该混合算法的有效性和优势。这种混合方法为混沌系统的预测提供了一个新的视角,对于提高混沌时间序列预测的精度和稳定性具有重要意义,也为其他复杂优化问题提供了潜在的解决方案。
2.2.3 Selection operation
The one-to-one greedy selection is employed by means of
comparing a parent and its corresponding offspring. And
this strategy enhances diversity in comparison to other
selection strategies such as tournament selection, rank
based selection and fitness proportional selection. The
selection operation at the K-th generation is described as
X
Kþ1
i
¼
U
K
i
if f ðU
K
i
Þf ðX
K
i
Þ
X
K
i
if f ðU
K
i
Þ[ f ðX
K
i
Þ
ð7Þ
where f(X) is the objective function value of each trial
vector.
2.3 Hybrid teaching–learning-based optimization
(TLBO–DE)
An efficient evolutionary algorithm should make use of
both the local information of solutions found so far and
the global information about the search space. The local
information of solutions found so far can be helpful for
exploitation, while the global information can guide the
search for exploring promising areas. The search in
TLBO is mainly based on the global information, and
TLBO has the advantage that learners will converge to a
single attractor Teacher. DE is mainly based on the dis-
tance and direction information which is a kind of local
information. DE has the advantage of not being biased
toward any prior defined guider which make DE can
maintain the diversity of population and explore local
search. The key reason for employing the hybridization is
that the hybrid algorithm can take advantage of the
strengths of each individual technique while simulta-
neously overcoming its main limitations. That is, instead
of employing a single modification learner in TLBO, we
use the integration of two modification learners in TLBO–
DE. The first is the classical modification learner of
TLBO, and the second is generated using the DE muta-
tion rules for learner. The detailed learning processes are
described below.
2.3.1 Teacher phase
To balance the global and local search ability, a modified
interactive learning strategy is proposed in teacher phase.
In this learning method, each learner is randomly assigned
to an interactive learning strategy (the learning strategy of
Teacher Phase in the standard TLBO or differential
learning based on DE).
In TLBO–DE, the updating formula of the learning for a
learner X
i
in teacher phase is proposed by the hybridization
of the learning strategy of Teacher Phase and the differ-
ential learning as follows
newX
i;j
¼ u V
1;j
ðtÞþð1 uÞV
2;j
ðtÞð8Þ
where u called the hybridization factor is a random number
in the range [0, 1] for the j-th dimension, V
1,j
is the learners
which is calculated according to Eq. (2) and V
2,j
is the
learners which is calculated according to Eq. (5).
2.3.2 Learner phase
At the same time, in the learner phase, learners also learn
from interaction between themselves. In this learning
method, one of learners randomly learns from the other
learner in the population. Let newX
i
represent the interac-
tive learning result of the learner X
i
and it can be expressed
as follows:
newX
i;j
¼ u V
1;j
ðtÞþð1 uÞV
2;j
ðtÞð9Þ
where u called the hybridization factor is a random number
in the range [0, 1] for the j-th dimension, V
1,j
is the learners
which is calculated according to Eq. (3) and V
2,j
is the
learners which is calculated according to Eq. (5).
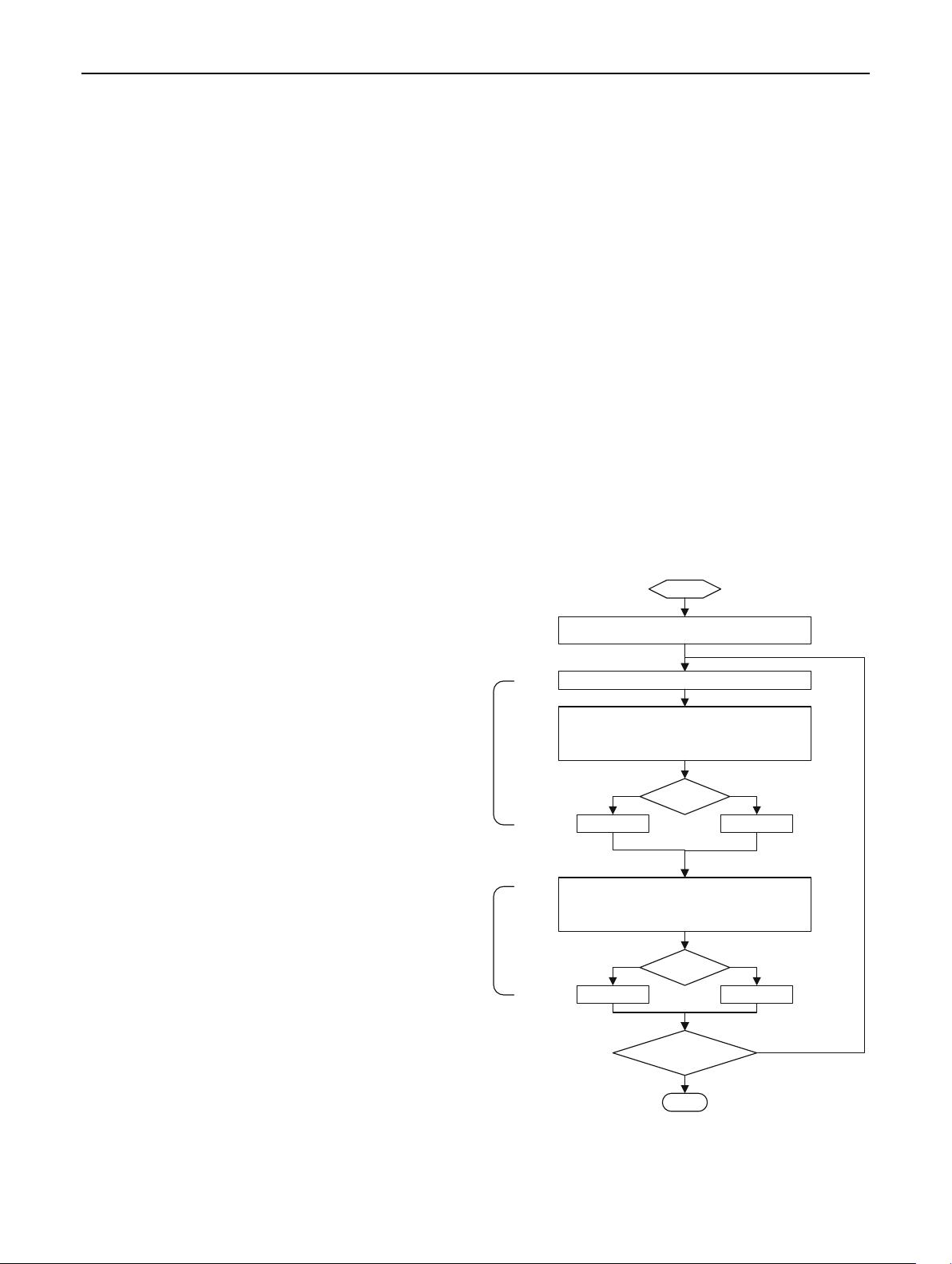
As previously analyzed, the complete flowchart of the
TLBO–DE algorithm is shown in Fig. 1.
Begin
Initialize learners size(NP), dimension(D)
Modify each learner X
i
in the class
V
1j
= Learning strategy of Teacher Phase
V
2j
= DE Learning
newX
i j
= u*V
1j
+(1-u)*V
2j
newX
i
better X
i
Modify each learner X
i
in the class
V
1j
= Learning strategy of Learner Phase
V
2j
= DE Learning
newX
i j
= u*V
1j
+(1-u)*V
2j
X
i
= newX
i
X
i
= X
i
Yes No
newX
i
better X
i
X
i
= newX
i
Yes No
X
i
= X
i
termination
criteria satisfied
No
End
Yes
Calculate the Teacher and Mean
Learner
Phase
Teacher
Phase
Fig. 1 Flow chart showing the working of TLBO–DE algorithm
Neural Comput & Applic
123
剩余15页未读,继续阅读
2018-05-27 上传
2021-02-08 上传
2021-02-10 上传
2021-04-22 上传
2021-06-01 上传
2021-02-11 上传
2021-02-07 上传
2021-02-21 上传
2021-02-21 上传

weixin_38606169
- 粉丝: 4
- 资源: 957
 我的内容管理
展开
我的内容管理
展开







最新资源
- 掌握Jive for Android SDK:示例应用的使用指南
- Python中的贝叶斯建模与概率编程指南
- 自动化NBA球员统计分析与电子邮件报告工具
- 下载安卓购物经理带源代码完整项目
- 图片压缩包中的内容解密
- C++基础教程视频-数据类型与运算符详解
- 探索Java中的曼德布罗图形绘制
- VTK9.3.0 64位SDK包发布,图像处理开发利器
- 自导向运载平台的行业设计方案解读
- 自定义 Datadog 代理检查:Python 实现与应用
- 基于Python实现的商品推荐系统源码与项目说明
- PMing繁体版字体下载,设计师必备素材
- 软件工程餐厅项目存储库:Java语言实践
- 康佳LED55R6000U电视机固件升级指南
- Sublime Text状态栏插件:ShowOpenFiles功能详解
- 一站式部署thinksns社交系统,小白轻松上手
