
Eur. Phys. J. C (2018) 78:392 Page 3 of 11 392
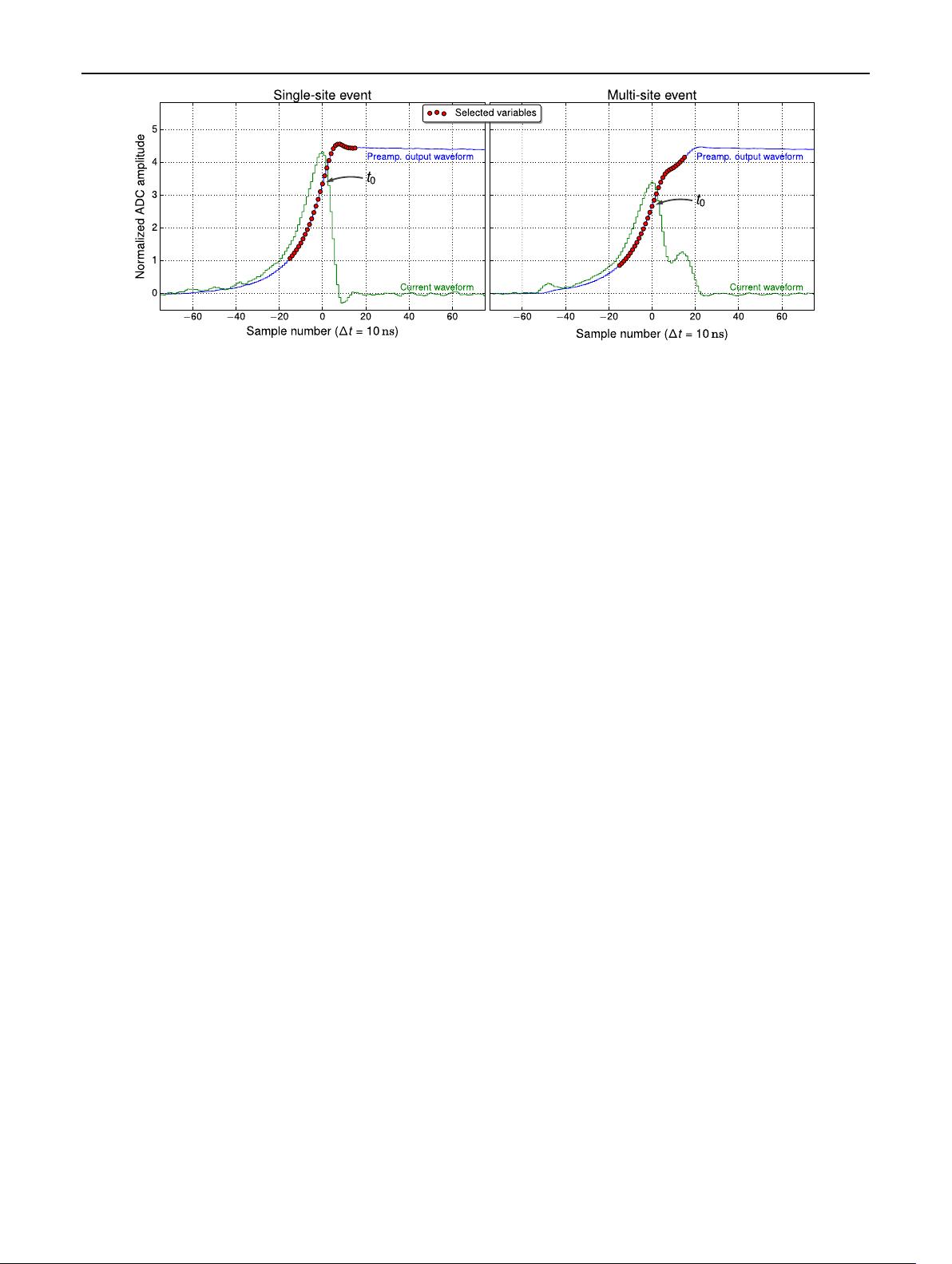
Fig. 3 Pulse shapes from typical single-site (left) and multi-site (right)
events. The current pulses (in green) were obtained by digital differenti-
ation of the preamplifier output (in blue) and smoothing with a moving
average filter (width of 50 ns). Red points represent the amplitudes
selected to perform the PSA. t
0
indicates the amplitude, which corre-
sponds to the maximal current of the pulse
corresponding to the maximal current (time t
0
). The extrac-
tion procedure is illustrated in Fig. 3.
In the course of this study we also found that the 31 sam-
ples can be divided into 4 groups and consecutively summed
together. This is most likely due to the fact that sampling rate
oftheusedFADCis4× faster than preamplifier bandwidth.
The operation of samples summing also effectively reduces
the dimensionality of the problem (from 31 dimension to 4),
which in turn decreases the level of the classifier complexity
(e.g. number of neurons in the MLP). Lower complexity clas-
sifiers require less computation time and also are less prone
to overtraining.
3.1 Multi-layer perceptron neural network
In the course of this study we found that a method based
on an MLP neural network has shown the best separation
efficiency. Many detailed descriptions of this kind of neural
network are available in the literature (e.g. [9,14]), a short
summary will be provided here for a better understanding of
the PSD method.
A conceptual drawing of an MLP neural network is shown
in Fig. 4 (the so-called “bias neurons” were not drawn). The
network consists of several layers. The first one is an input
layer – in the described method its role was to normalize (val-
ues between −1 and 1) each of the input variables. A simple
linear transformation was used for this purpose (denoted with
a straight line in a circle in Fig. 4).
The normalized values (y
1
, y
2
,...y
n
, where n is a num-
ber of input variables) are then “fed” to the next layer. This is
the so-called “hidden layer” and this is where the classifica-
tion process really takes place. Each connection between the
neurons in the input and the hidden layers has a number w
k
ij
associated with it, called the “weight” (i is an index of neu-
ron in the previous layer, j is a similar index, but in a current
layer, and k is the index of the previous layer). Additionally,
each neuron is characterized with a (usually) non-linear func-
tion (called the “activation function”). To calculate the output
value of a given neuron, we consider all connections between
neurons from the previous layer, where the output values are
already calculated (e.g. the normalized values from the input
layer). Then, each weight is multiplied by the previous layer
output values and the products are summed together. After
this operation, the activation function is applied to the sum
(in this case it was hyperbolic tangent). The single neuron
response is summarized in the inset in Fig. 4.
It should be mentioned that in principle more hidden layers
can be used. However, the Stone–Weierstrass theorem states
that the feedforward perceptron neural network can approx-
imate any non-linear function (the precision depends on a
number of neurons used in the layer) using just one hidden
layer [9]. The only requirement is that the neuron activation
should be non-linear itself [15].
The last step in the response calculation takes place in the
output layer. The principle of a neuron response calculation
is the same as in previous layers. In this specific case (the
neural network used in this work), the activation function
is a sigmoid, in contrast to the hyperbolic tangent functions
from the hidden layer. Since the output of the sigmoid can
only take values between 0 to 1, the response is normalized
to this range.
For the training process of the neural network, sets of
background and signal events must be selected. Their purpose
is to set the neuron values in the network in such way that
after classification of the training events the network will
output the value close to 1 for events from signal set and 0
for their background counterparts.
123
剩余10页未读,继续阅读

weixin_38734361
- 粉丝: 6
- 资源: 904
 我的内容管理
展开
我的内容管理
展开







最新资源
- 李兴华Java基础教程:从入门到精通
- U盘与硬盘启动安装教程:从菜鸟到专家
- C++面试宝典:动态内存管理与继承解析
- C++ STL源码深度解析:专家级剖析与关键技术
- C/C++调用DOS命令实战指南
- 神经网络补偿的多传感器航迹融合技术
- GIS中的大地坐标系与椭球体解析
- 海思Hi3515 H.264编解码处理器用户手册
- Oracle基础练习题与解答
- 谷歌地球3D建筑筛选新流程详解
- CFO与CIO携手:数据管理与企业增值的战略
- Eclipse IDE基础教程:从入门到精通
- Shell脚本专家宝典:全面学习与资源指南
- Tomcat安装指南:附带JDK配置步骤
- NA3003A电子水准仪数据格式解析与转换研究
- 自动化专业英语词汇精华:必备术语集锦
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


