深度学习框架预测慢性疾病:结合电子健康记录文本与结构信息
需积分: 9 80 浏览量
更新于2024-07-09
收藏 1.15MB PDF 举报
"《利用医疗记录预测慢性疾病:深度学习方法的探索》(DeepEHR: Chronic Disease Prediction Using Medical Notes)是一篇由Jingshu Liu、Zachariah Zhang和Narges Razavian合作的研究论文,发表于纽约大学的研究成果。该研究强调了早期预防可控制疾病的必要性,因为这有利于疾病的更好管理、更有效的干预措施以及卫生保健资源的高效分配。
在传统的电子健康记录(EHR)中,大量的信息被结构化字段所占据,而自由文本的医疗笔记往往被忽视。然而,这些非结构化的笔记包含着丰富的临床细节,对于疾病预测具有重要意义。作者提出了一种通用的多任务框架,旨在结合医疗笔记的自由文本和结构化信息,以提高疾病发病预测的准确性。
论文的核心贡献是应用深度学习技术,包括卷积神经网络(CNN)、长短时记忆网络(LSTM)以及层次模型,来处理医学笔记中的文本数据。与传统的基于文本的预测模型相比,这种方法避免了针对特定疾病的特征工程,能够更好地处理否定表述和其他复杂语言现象,从而提升了模型的泛化能力和预测性能。
作者们通过对比实验展示了这些深度学习架构在疾病预测任务中的表现,并且证明了他们的方法能够在处理大量非结构化医疗笔记时展现出优势。这项工作不仅推动了医疗健康领域的AI应用,也为未来研究如何更好地利用EHR中的丰富信息提供了新的视角和实践指南。这篇论文为慢性疾病预测的准确性和效率提升提供了一种创新且实用的解决方案。"
DEEP EHR: CHRONIC DISEASE PREDICTION USING MEDICAL NOTES
4. Methods
4.1 Baselines
We use three different baselines to evaluate the contribution of text data, the deep learning architecture
and their combination. Firstly, we train an L1-regularized logistic regression model with all available
demographic features and lab values averaged within the history window. Secondly we train an
LSTM model with all available demographic features and lab values at each encounter, to provide a
more fair comparison with other deep learning models with additional text data. The last baseline is
an L1-regularized logistic regression with TF-IDF N-gram features in the text. This baseline shows
the value of deep learning in modeling complicated text. We use the 20k most frequent 1-, 2-, and
3-grams. We utilize the sklearn’s implementation of logistic regression for this task Pedregosa et al.
(2011).
4.2 Learning Continuous Embedding of Vocabulary
In our first analysis we use embeddings previously trained on the PubMed dataset Pyysalo and
Ananiadou (2013). We then train new embeddings directly on the NYU Langone Center medical
notes, as the style and abbreviations present in clinical notes are distinct from medical publications
available at PubMed. We adopt StarSpace Wu et al. (2017) as a general-purpose neural model for
efficient learning of entity embeddings. In particular, we label the notes from each encounter with
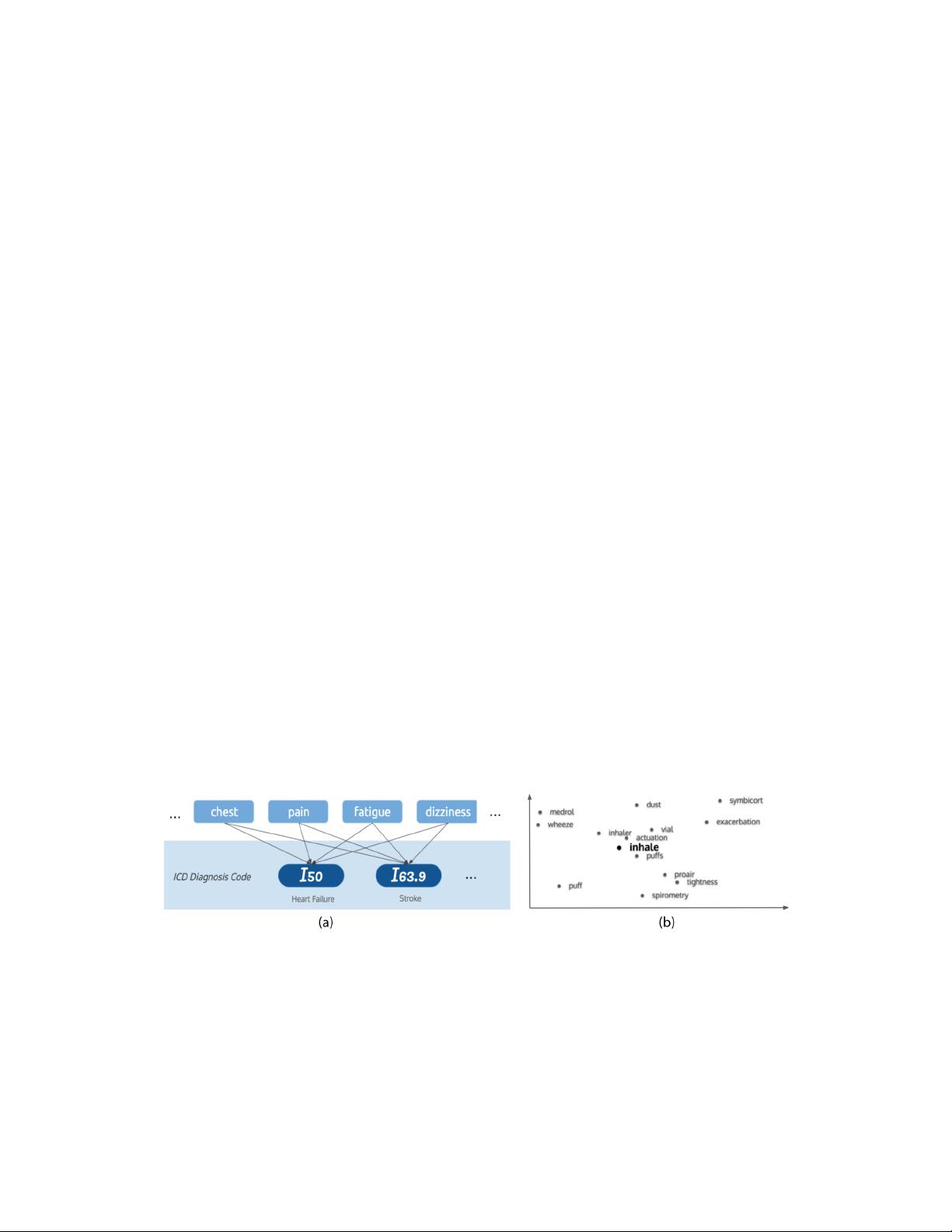
the ICD-10 diagnosis codes of the same encounter, as shown in Figure 2 (a). Under StarSpace’s
bag-of-word approach, the encounter is represented by aggregating the embedding of individual
words (we used the default aggregation method where the encounter is the sum of embeddings of
all words divided by the squared root of number of words). Both the word embeddings and the
diagnosis code embeddings are trained so that the cosine similarity between the encounter and its
diagnoses is ranked higher than that between the encounter and a set of different diagnoses. Thus
words related to the same symptom are placed close to each other in the embedding space. For
example, figure 2 (b) shows neighbours of the word "inhale" by t-SNE projection of the embeddings
to the 2-dimensional space. We find that the bag-of-word style embedding creates representations
better for disease prediction than using a standard skip-gram objective.
Figure 2: Illustration of StarSpace: (a) embeddings are trained with labeled bag-of-words approach.
(b) StarSpace word embedding example under t-SNE projection.
Utilizing all available notes except for those on patients in the validation or the test set, we
obtain a much larger embedding training set than that of the prediction task. We find that the
StarSpace embeddings trained on clinical notes outperform the pre-trained PubMed embeddings in
the downstream prediction task, as shown in Table 2. We test a set of 300-dimension embeddings and
5
剩余23页未读,继续阅读
2021-06-07 上传
2014-11-26 上传
2023-07-23 上传
2017-11-10 上传
2022-01-31 上传
2024-09-07 上传
2023-04-18 上传
2023-03-16 上传
2023-03-31 上传

Data+Science+Insight
- 粉丝: 1w+
- 资源: 54
 我的内容管理
展开
我的内容管理
展开







