“藏经阁-云时代大数据管理引擎HAWQ++.pdf”主要介绍的是阿里云的HAWQ++,这是一个大数据管理引擎,其发展经历了从原生的Hadoop并行SQL引擎到HAWQ2.0,并在Apache孵化器中进行进一步发展。偶数科技的HAWQ++是对HAWQ的扩展和增强。
HAWQ,全称High-Performance Analytics Warehouse Query,最初是作为Hadoop生态系统中的一个SQL查询引擎设计的。它从GoH演进到HAWQAlpha,然后发展到HAWQ1.0和1.x版本。随着技术的进步,HAWQ进入了2.0时代,并成为了Apache Incubator项目的一部分,网址为http://hawq.incubator.apache.org。同时,偶数科技(Oushu)也对HAWQ进行了增强,推出了HAWQ++,更多信息可以在http://www.oushu.io上查看。
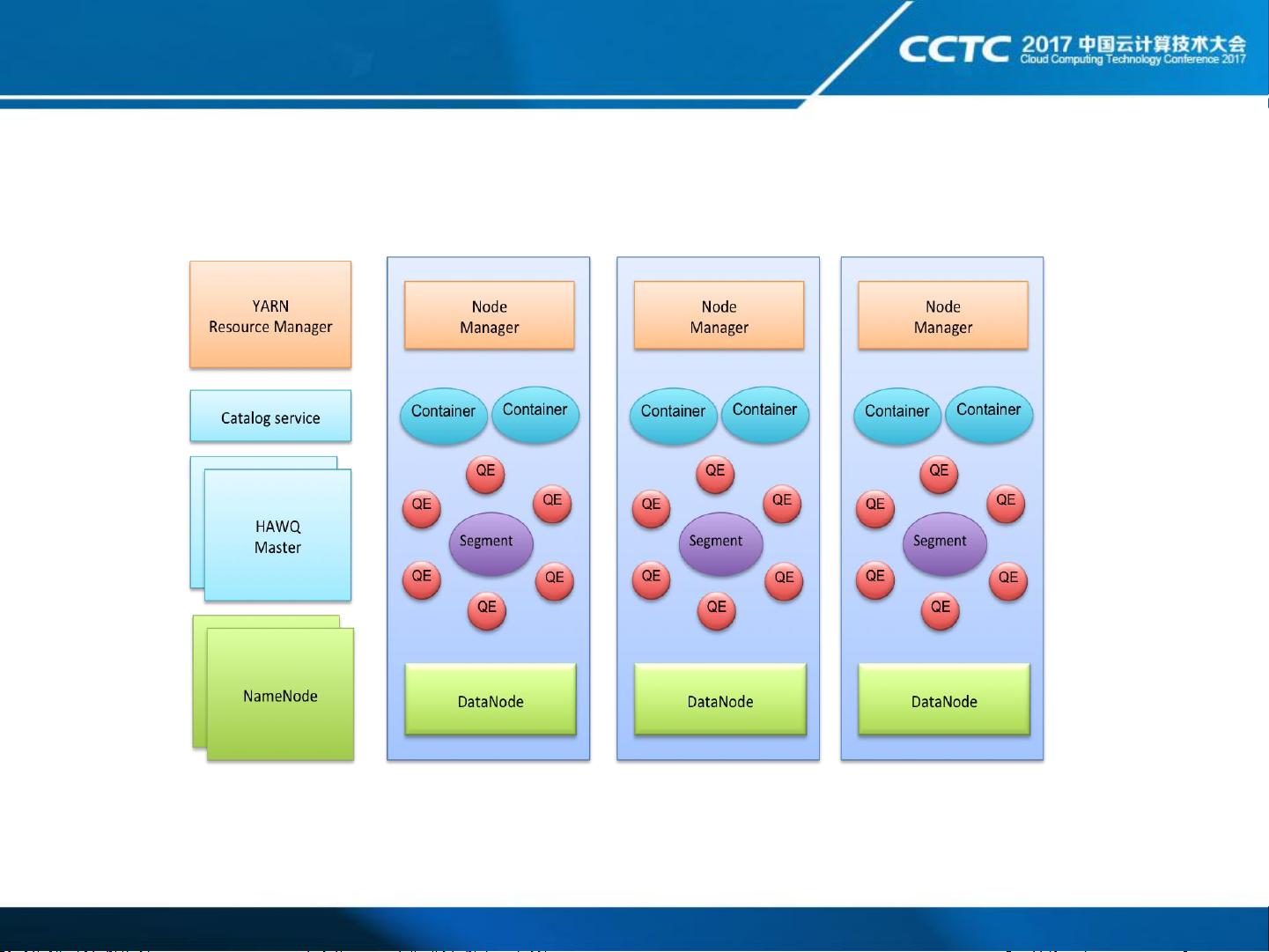
HAWQ的组件包括一系列服务,如Masters、Parser/Analyzer、Optimizer、Dispatcher等,与Yarn紧密集成,通过PhysicalSegment、VirtualSegment和DataNode协同工作,提供高效的数据管理和查询处理。HAWQ利用Yarn的资源管理能力,确保在分布式环境中稳定运行。
HAWQ的体系架构展示了其在Yarn上的运行方式,包括Master节点、Client、NodeManager、NameNode、Resource Manager以及Fault Tolerance Service等关键组成部分。HAWQ还依赖于Catalog Service和libYARN来协调与外部系统的交互,并通过HDFSCatalogCache和Interconnect实现高效的数据访问。
在查询处理方面,HAWQ的优化器能够处理复杂的SQL查询,例如示例中的分组聚合查询。通过Motion操作,如redistribute motion、broadcast motion和gather motion,HAWQ能有效地在不同节点之间移动数据以优化查询性能。
HAWQ的资源管理是其强大功能的关键。它具有三级资源管理模式:全局、内部和操作符级别资源管理,以及多级资源队列,能够精细地分配和管理CPU和内存资源,以适应不同用户和查询的需求。
在存储方面,HAWQ采用行式存储(Row-oriented)并支持AO(Append-Only)格式,配合Quicklz和zlib等压缩算法,以提高数据存储效率和查询性能。
HAWQ++作为云时代的大型数据管理引擎,提供了高性能的SQL查询、灵活的资源管理和高效的数据存储方案,是处理大规模数据分析的理想工具。对于需要在Hadoop环境中执行复杂SQL查询和管理大数据的企业,HAWQ++提供了强大的解决方案。


 我的内容管理
展开
我的内容管理
展开









