Hadoop RPC详解与Avro集成探索
13 浏览量
更新于2024-08-28
收藏 229KB PDF 举报
本文主要探讨了Hadoop RPC(Remote Procedure Call)机制以及如何将Avro引入到Hadoop RPC中进行初步研究。Hadoop RPC是分布式系统中常用的一种通信方式,它允许在分布式环境中通过网络调用远程服务,而无需关心底层网络细节。RPC的核心组成部分包括Server端和Client端的交互。
Hadoop的RPC Server是一个抽象的RPC服务提供者,它包含以下几个关键组件:
1. **Server.Listener**:这是RPC Server的主要接收端,负责监听RPC Client的连接请求,并在接收到数据后将其封装成Call对象并放入Call队列中。这个操作由Listener线程执行,确保高效处理多个请求。
2. **Server.Handler**:作为Call处理者,它从Call队列中按先进先出(FIFO)原则取出Call,然后调用对应的远程方法,通过JDK的Method类实现业务逻辑。
3. **Server.Responder**:负责异步非阻塞地向RPC Client发送响应,确保响应的及时性和系统的并发性能。
4. **Server.Connection**:负责接收和解析RPC Client的数据,将数据包转换成Call对象。
在引入Avro时,一种可能的做法是利用Avro的序列化和反序列化能力,提高数据传输的效率和一致性。Avro支持自定义数据类型和数据格式,这对于RPC服务来说非常有用,因为可以确保跨节点的数据交换标准。在Hadoop RPC中整合Avro,可能涉及到以下步骤:
- **数据序列化**:在Client端,使用Avro库将请求对象序列化为字节流;在Server端,反序列化这些字节流以恢复原始请求。
- **Avro协议定义**:为了确保双方能理解对方发送的数据,需要预先定义一个共享的Avro schema,描述数据结构。
- **Avro Call对象**:将序列化的数据包装成Hadoop RPC的Call对象,以便于在服务器上正确处理。
- **Avro响应生成**:RPC服务在处理完请求后,使用Avro生成相应的响应,再序列化为字节流。
通过引入Avro,Hadoop RPC能够更好地支持复杂的数据交换,提高系统的灵活性和数据一致性。然而,需要注意的是,集成Avro可能会增加系统的复杂性,需要额外的配置和优化工作,尤其是在大规模集群环境中。此外,Avro的性能开销也需考虑,尤其是在处理大量数据或频繁调用的情况下。
hadooprpc机制机制&&将将avro引入引入hadooprpc机制初探机制初探
1 RPC
RPC(Remote Procedure Call)——远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络
技术的协议。
2 hadoop.ipc
2.1 Server
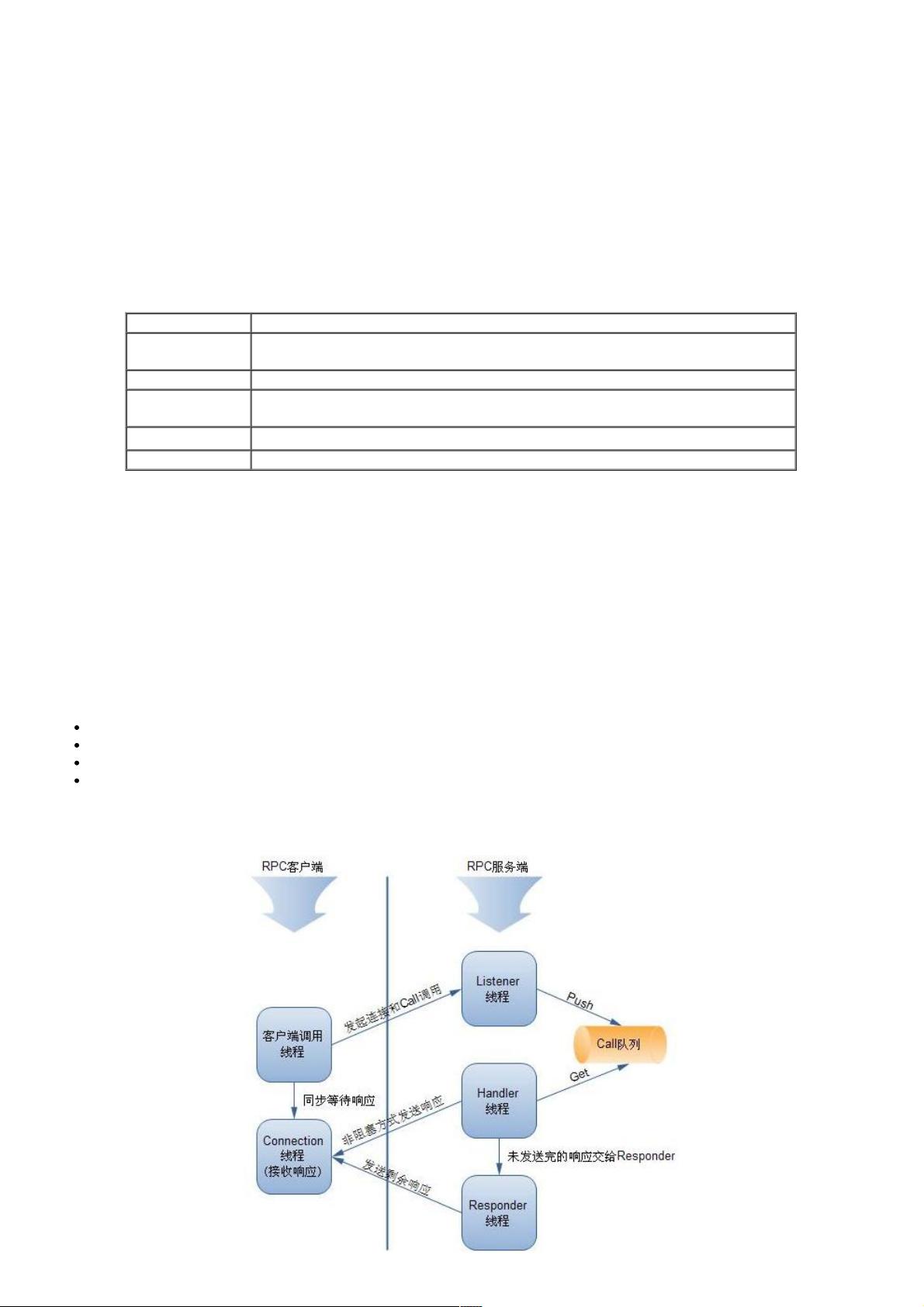
RPC Server实现了一种抽象的RPC服务,同时提供Call队列。
RPC Server结构
结构结构 功能功能
Server.Listener
RPC Server的监听者,用来接收RPC Client的连接请求和数据,其中数据封装成
Call后PUSH到Call队列。
Server.Handler RPC Server的Call处理者,和Server.Listener通过Call队列交互。
Server.Responder
RPC Server的响应者。Server.Handler按照异步非阻塞的方式向RPC Client发送响
应,如果有未发送出的数据,交由Server.Responder来完成。
Server.ConnectionRPC Server数据接收者。提供接收数据,解析数据包的功能。
Server.Call 持有客户端的Call信息。
RPC Server主要流程
RPC Server作为服务提供者由两个部分组成:接收Call调用和处理Call调用。
接收Call调用负责接收来自RPC Client的调用请求,编码成Call对象后放入到Call队列中。这一过程由Listener线程完成。具体
步骤:
1. Listener线程监视RPC Client发送过来的数据。
2. 当有数据可以接收时,调用Connection的readAndProcess方法。
3. Connection边接收边对数据进行处理,如果接收到一个完整的Call包,则构建一个Call对象PUSH到Call队列中,由
Handler线程来处理Call队列中的所有Call。
处理Call调用负责处理Call队列中的每个调用请求,由Handler线程完成:
Handler线程监听Call队列,如果Call队列非空,按FIFO规则从Call队列取出Call。
将Call交给RPC.Server处理。
借助JDK提供的Method,完成对目标方法的调用,目标方法由具体的业务逻辑实现。
返回响应。Server.Handler按照异步非阻塞的方式向RPC Client发送响应,如果有未发送出的数据,则交由
Server.Responder来完成。
交互过程如下图所示:
下载后可阅读完整内容,剩余7页未读,立即下载
2015-07-21 上传
2019-04-24 上传
点击了解资源详情
2021-04-14 上传
2021-01-07 上传
2021-04-08 上传
2021-04-28 上传
2020-06-11 上传
2021-05-09 上传

weixin_38740397
- 粉丝: 6
- 资源: 854
 我的内容管理
展开
我的内容管理
展开







