scikit-learn机器学习实战:从安装到核心概念解析
版权申诉
"scikit-learn学习笔记.pdf 是一本详尽介绍scikit-learn库的文档资料,涵盖了该库的基础知识、主要特点、安装方法以及多种机器学习算法的应用。"
scikit-learn是Python编程语言中广泛使用的机器学习库,它为数据科学家提供了丰富的工具来执行各种机器学习任务。这份学习笔记首先介绍了scikit-learn的基本信息,强调其简单易用、高效处理数据以及在NumPy、SciPy和matplotlib等科学计算库上的构建基础。此外,scikit-learn遵循商业开源协议BSD许可证,这意味着用户可以自由地使用、修改和分发代码。
文档接着详细阐述了scikit-learn的安装过程,以Ubuntu 14.04.1为例,说明了安装必要的依赖项和scikit-learn库的步骤。对于其他操作系统或环境,安装过程可能会有所不同,但通常可以通过包管理器或pip来完成。
在机器学习部分,文档涵盖了广泛的分类、聚类、回归和降维算法。分类是监督学习的一个分支,其中1.1至1.14章节讨论了如广义线性模型、支持向量机(SVM)、随机梯度下降(Stochastic Gradient Descent, SGD)、K近邻(K-Nearest Neighbors, KNN)、高斯过程(Gaussian Processes)、交叉分解(Cross-decomposition)、朴素贝叶斯(Naive Bayes)、决策树(Decision Trees)、集成方法(Ensemble methods)、多类和多标签算法(Multiclass and Multilabel algorithms)、特征选择(Feature selection)以及等距回归(Isotonic Regression)等算法。
除了分类,文档还介绍了无监督学习,如2.3章节的聚类(Clustering)。聚类旨在将数据集划分为具有相似性质的组。此外,3.2章节的模型选择和评估部分讲解了如何评估和优化模型性能,包括交叉验证(Cross-validation)、网格搜索(Grid Search)、管道(Pipeline)、特征组合(Feature Union)、模型评估(Model evaluation)、模型持久化(Model persistence)、验证曲线(Validation curves)等概念和技术。
在预处理方面,4.2章节提到了预处理数据的重要性,包括标准化、归一化和随机投影(Random Projection)等方法,这些都是在应用机器学习算法前对数据进行的常见处理步骤。这些预处理技术有助于提高模型的性能和泛化能力。
总而言之,这本scikit-learn学习笔记为学习者提供了一个全面的指南,不仅覆盖了基本的安装步骤,还包括了从数据预处理到模型训练和评估的完整流程,涉及多种机器学习算法及其在scikit-learn中的实现,是Python机器学习实践中不可或缺的参考资料。
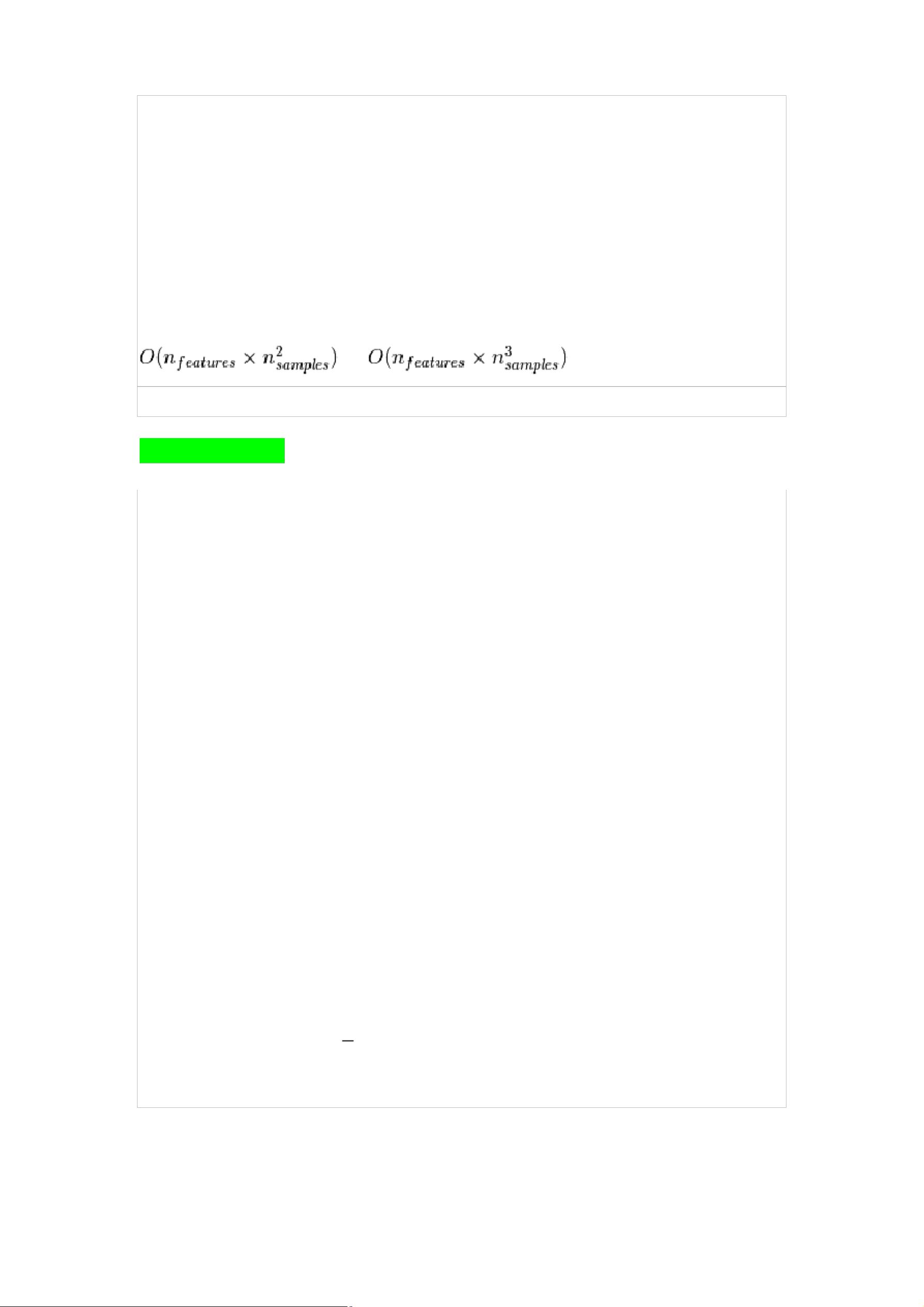
(2)根据(1)的随机子集拟合模型(base_estimator.fit),并检查模型是否有效
(is_model_valid)
优模型。
使用:model_ransac = linear_model.RANSACRegressor(linear_model.LinearRegression())
(3)通过计算估计模型的方法来分类数据
(4)如果临近样本数是最大的,并且当前的评估模型有同样的数则保存模型为最
1.1.15 多项式回归
机器学习中的常见模式,使用线性模型训练数据的非线性函数
1.2 支持向量机
拟合出来的模型为一个超平面
解决与样本维数无关,适合做文本分类
解决小样本、非线性、高维
是用于分类、回归、孤立点检测的监督学习方法的集合。
优点:
缺点:
不适用于特征数远大于样本数的情况
不直接提供概率估计
有效的高维空间
维数大于样本数的时候仍然有效
在决策函数中使用训练函数的子集
通用(支持不同的内核函数:线性、多项式、s 型等)
接受稠密和稀疏的输入
1.2.1 Classification
由 SVC、NuSVC 或 LinearSVC 实现,可进行多类分类
LinearSVC 只支持线性分类
SVC 和 NuSVC 实现一对一,LinearSVC 实现一对多
使用:
clf = svm.SVC()
lin_clf = svm.LinearSVC()
SVC、NuSVC 和 LinearSVC 均无 support_、support_vectors_和 n_support_属性
1.2.2 回归
剩余49页未读,继续阅读
2022-06-27 上传
2018-05-14 上传
2017-10-31 上传
2021-02-04 上传
2022-07-01 上传
2023-06-20 上传
2021-05-07 上传
2021-05-24 上传

春哥111
- 粉丝: 1w+
- 资源: 6万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- QGitTag:Qt5的一个库,它使用GitHub API提供有关标签的信息
- C#图表分析显示彩票中奖情况
- RevMan-HAL:RevMan HAL是用于自动将文本添加到RevMan文件中特殊部分的工具。 现在,您还可以在不同阶段之间进行选择。 要下载,请点击自述文件中的链接
- slmp协议说明.zip
- 毕业设计&课设-非线性反馈控制的MATLAB仿真代码.zip
- eslint-config:为ESLintReact特定的掉毛规则
- 面积守恒flash数学课件
- git-stat:用于从github获取统计信息的命令行应用程序
- protoc-3.13.0-win64.rar
- l-曲线matlab代码-SlushFund-2.0---Active-Interface-Tracking:多相无功传输代码
- ES-2Sem-2021-Grupo52:ES项目
- bucketfish-docker:用于使用Docker编译Barrelfish以及与Gitlab CI Runners集成的设置
- 毕业设计&课设-基本遗传算法MATLAB程序.zip
- Shopee-Case-Study
- VitamioPlayer.rar
- yserial:NoSQL y_serial Python模块–使用SQLite仓库压缩对象
