多策略Q-learn连续动作优化:智能游戏中的最优路径探索
需积分: 0 48 浏览量
更新于2024-07-01
收藏 2.72MB PDF 举报
本文主要探讨了在智能学习背景下,利用多策略Q-learning算法优化连续动作的游戏模型。游戏被视为智能学习的一个重要应用场景,研究者针对游戏中的玩家穿越最优路径问题进行了深入分析。
首先,针对固定环境参数的问题,构建了一个连续动作优化模型,该模型将地图数据转化为连通图矩阵,考虑背包容量、天气因素和生存条件等约束条件。采用精确购买策略,将时间维度引入Q矩阵,形成三维结构。动态ε-greedy策略被用于探索性学习,随着学习的进行,Q矩阵逐渐收敛,最终通过完全贪婪策略找到最优动作组合和每日物资剩余量。例如,第一关和第二关的最优策略展示了通过优化后的算法可以实现较高的资金保留。
在问题二中,作者引入天气的随机性,通过期望学习策略改进的Q-learning算法来适应变化的环境。在三维Q矩阵上增加天气维度,根据期望最优Q值进行经验学习,尽管面对天气变化,但特定关卡(如第三关)的最优路径保持不变,而第四关则显示天气因素对通关概率和收益有负面影响。
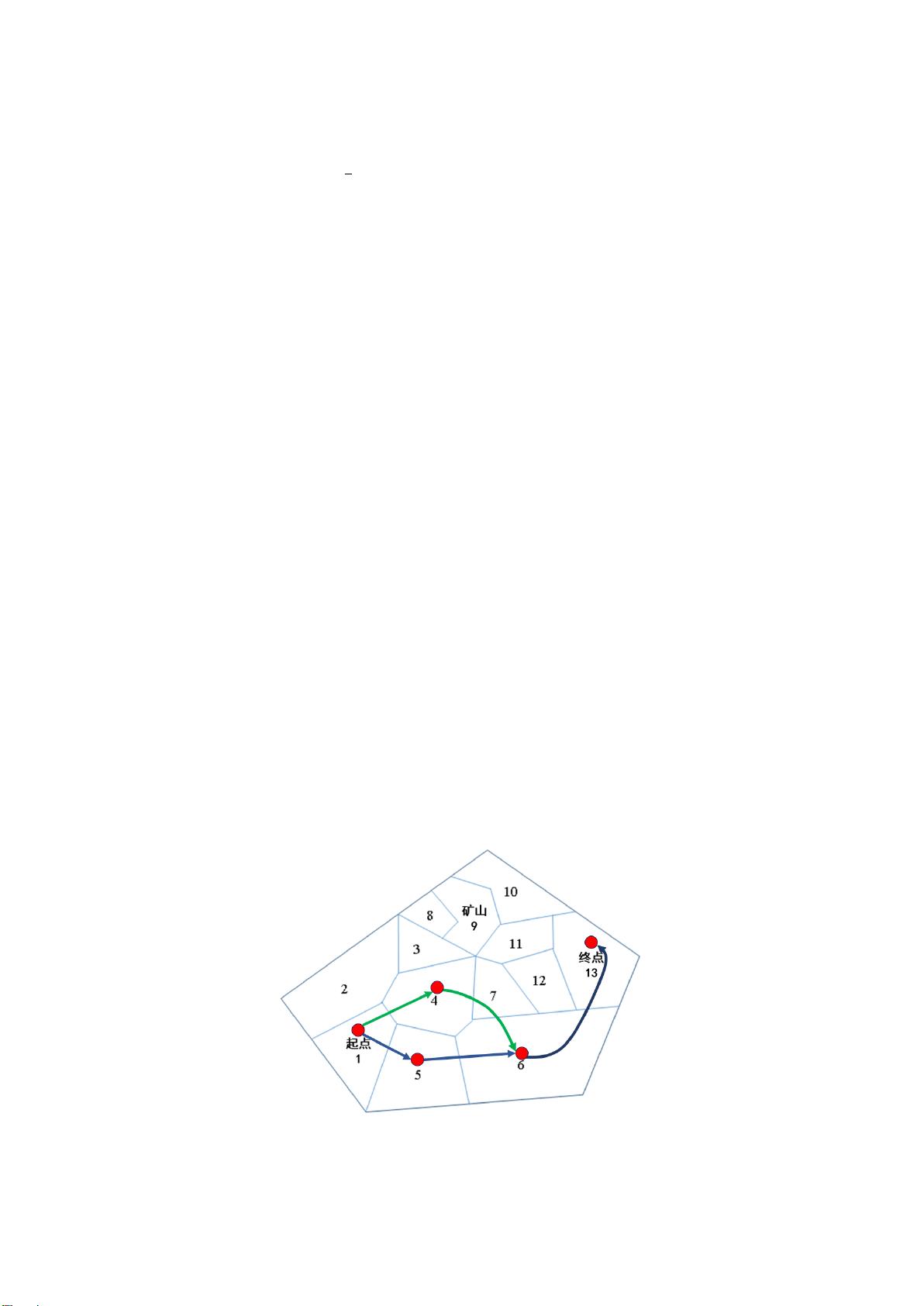
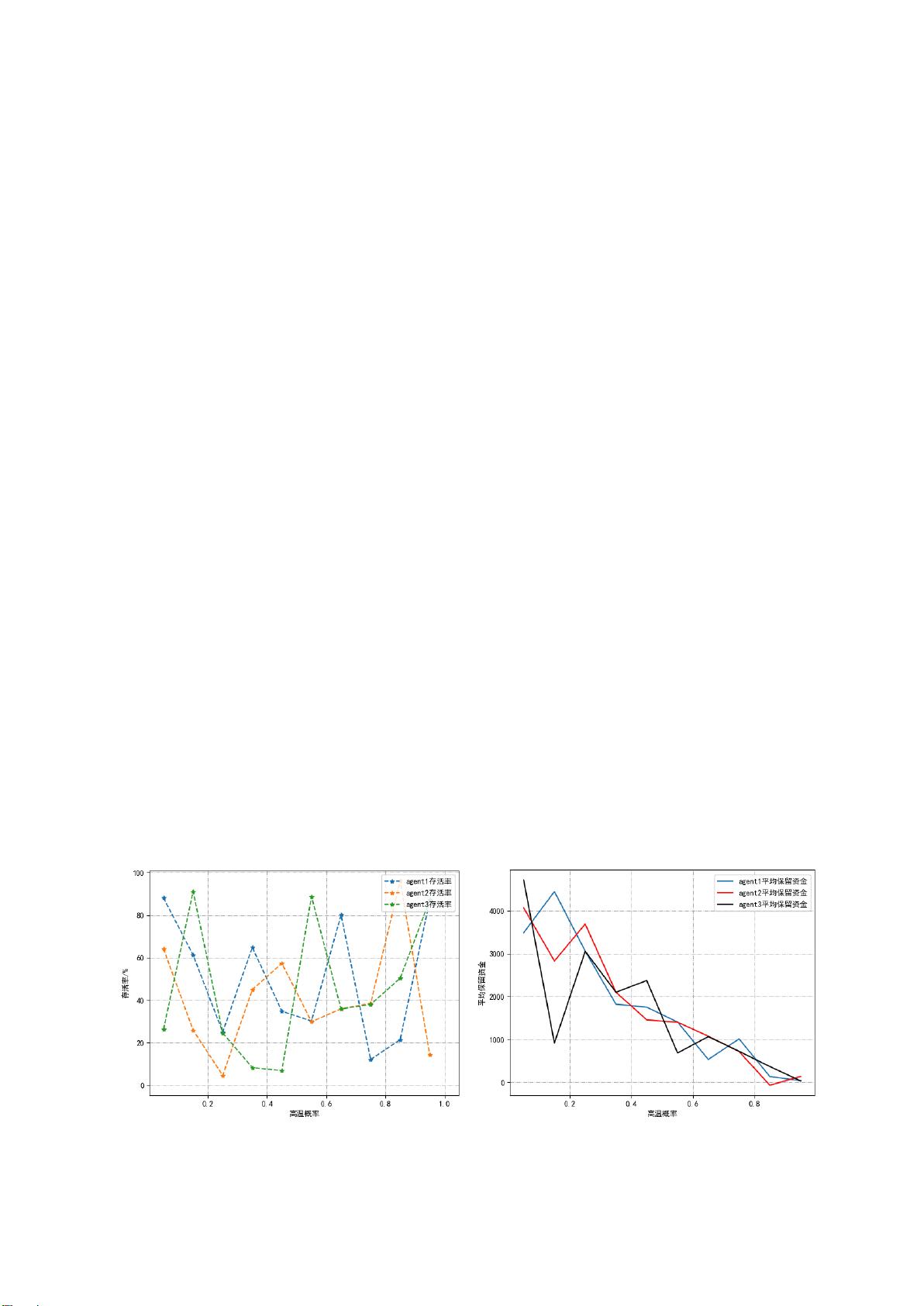
问题三涉及玩家间的竞争与合作。针对完全竞争情况,建立了静态完全信息博弈模型,证明了玩家的最优策略依然为[1,4,6,13]与[1,5,6,13],无论对手选择。在三人合作的第六关,研究者采用了Q-learning算法,并引入谦让策略,结果表明即使在困难天气条件下,通过团队协作,部分玩家也能保持较高的通关成功率。
本文的创新之处在于结合了期望学习策略,提高了算法在动态和不确定环境下的适应性,使得模型能够在各种游戏情境下寻找最优解。通过这些实例和策略分析,论文不仅展示了多策略Q-learning算法在连续动作游戏中的应用,也提供了在复杂环境和竞争合作情境下智能决策的理论支持。
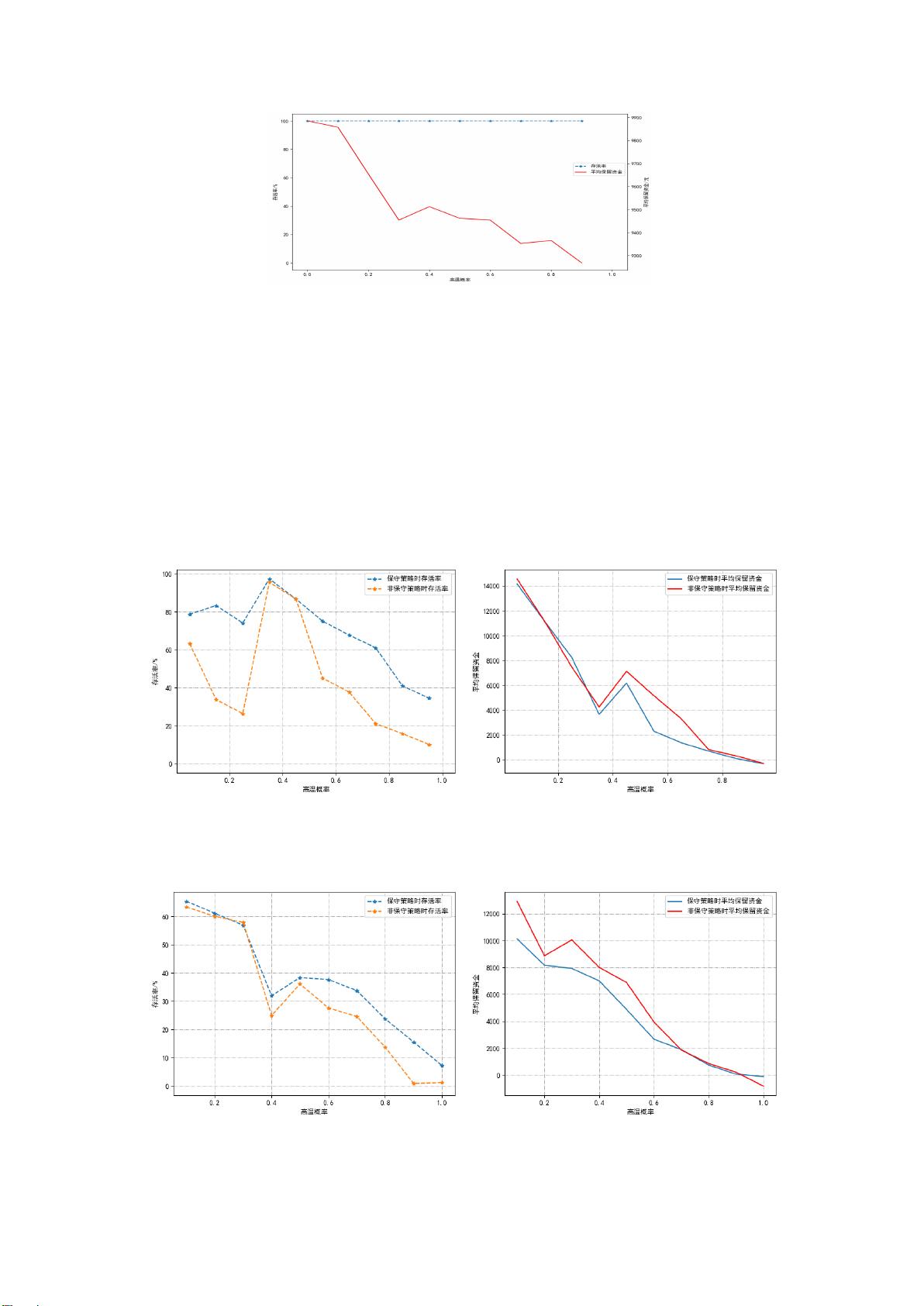
图 8 第三问学习策略结果仿真实验图
类似的,第四关中,根据附件信息可知 30 天内较少出现沙暴天气,即本组设定沙
暴概率为 p
1
分别为 0.05 和 0.1,并以高温天气出现概率 p
2
作为可调环境参数。对于不
同高温概率 p
2
情况下收敛所得的 Q 矩阵,以完全贪婪策略重复试验 N 次后,即可算得
玩家通关概率 p
survival
与平均保留资金 M
mean
。分别作出 p
survival
− p
2
图与 M
mean
− p
2
图如图 9 所示。图中的保守策略与非保守策略分别指代学习速率 λ 等于 0.8 与 1 时的学
习策略。
(a) 沙暴概率为 0.05 时天气与 agent 存活率关系 (b) 沙暴概率为 0.05 时天气与获得资金收益关系
(c) 沙暴概率为 0.1 时天气与 agent 存活率关系 (d) 沙暴概率为 0.1 时天气与获得资金收益关系
图 9 第四问学习策略结果仿真实验图
16

剩余94页未读,继续阅读
2022-08-04 上传
2023-05-24 上传
2023-09-01 上传
2023-09-21 上传
2023-07-28 上传
2023-12-24 上传
2023-09-11 上传

萱呀
- 粉丝: 30
- 资源: 354
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
