林智仁教授2006年机器学习讲义:支持向量机解析
“林智仁06年机器学习暑期学校讲义,主要讲解支持向量机方法。”
在这份机器学习暑期学校的讲义中,林智仁教授深入浅出地介绍了支持向量机(Support Vector Machines,SVM)的相关概念和应用。SVM是一种强大的监督学习模型,主要用于分类和回归分析。在众多的分类方法中,SVM因其优秀的性能和相对简单的使用方式而受到广泛关注。
讲义首先概述了SVM的基本概念,强调了为什么选择SVM和内核方法。SVM在很多情况下与现有的分类方法相比具有竞争力,其优点在于能够构建一个能够最大程度地分离不同类别的决策边界,即最大间隔分类器。此外,SVM的使用相对较简单,适合初学者入门。内核技术是SVM的一个关键特性,它允许非线性变换,从而可以解决复杂的非线性问题,如回归、密度估计和kernel PCA等。
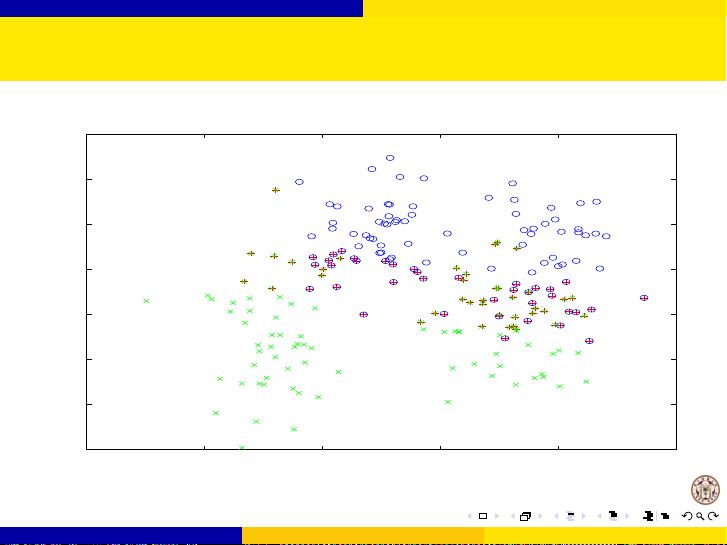
接下来,讲义详细阐述了SVM的原问题(Primal Problem)和对偶问题(Dual Problem)。在原问题中,SVM试图找到一个超平面,使得两类样本点到这个超平面的距离最大化。而在对偶问题中,SVM通过最大化间隔边界上的支持向量(Support Vectors)的间隔来求解。支持向量是离决策边界最近的训练样本,它们对模型的构建至关重要。
讲义还涵盖了训练线性和非线性SVM的过程。线性SVM直接在特征空间中寻找最优超平面,而非线性SVM则利用内核函数将数据映射到高维空间,实现非线性分类。常用的内核函数包括线性内核、多项式内核、高斯核(RBF)和Sigmoid内核等,不同的内核选择会影响模型的性能和复杂度。
在参数选择和实际问题部分,林教授讨论了如何选取合适的惩罚参数C和内核参数γ,以达到良好的泛化能力和避免过拟合。他还提到了在实际应用中可能遇到的问题,如数据预处理、特征选择、训练集大小的确定以及如何有效地处理大规模数据集。
此外,讲义还涉及了多类分类问题,SVM可以通过一对多(One-vs-One)或一对一(One-vs-All)策略来扩展到多于两个类别的分类任务。在多类分类中,需要构建多个二分类模型并综合它们的预测结果。
最后,林教授对SVM做了总结和讨论,回顾了SVM的主要优点和挑战,并鼓励学员们在实践中不断探索和优化SVM模型。
这份讲义为读者提供了全面且深入的SVM理论知识,是学习和理解支持向量机的宝贵资料。




2013-05-26 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

pds2010
- 粉丝: 1
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- MATLAB实现小波阈值去噪:Visushrink硬软算法对比
- 易语言实现画板图像缩放功能教程
- 大模型推荐系统: 优化算法与模型压缩技术
- Stancy: 静态文件驱动的简单RESTful API与前端框架集成
- 掌握Java全文搜索:深入Apache Lucene开源系统
- 19计应19田超的Python7-1试题整理
- 易语言实现多线程网络时间同步源码解析
- 人工智能大模型学习与实践指南
- 掌握Markdown:从基础到高级技巧解析
- JS-PizzaStore: JS应用程序模拟披萨递送服务
- CAMV开源XML编辑器:编辑、验证、设计及架构工具集
- 医学免疫学情景化自动生成考题系统
- 易语言实现多语言界面编程教程
- MATLAB实现16种回归算法在数据挖掘中的应用
- ***内容构建指南:深入HTML与LaTeX
- Python实现维基百科“历史上的今天”数据抓取教程
