2016年Usenix FAST存储技术会议全文
"FAST存储会议2016年全文"
FAST(Conference on File and Storage Technologies)是全球存储领域的顶级盛会,由USENIX协会主办,并得到了ACM SIGOPS的支持。2016年的会议在加利福尼亚州圣克拉拉举行,时间是2月22日至25日。这个资源包含了该年度会议的全部论文,涵盖了广泛的文件和存储技术主题,展示了当时研究领域的最新进展和创新。
参会者包括来自学术界和工业界的专家,他们共同讨论了存储系统设计、性能优化、数据持久化、容错机制、存储安全、闪存技术、分布式存储、云存储以及新兴的存储架构等多个关键议题。这些论文不仅反映了存储领域的最新研究趋势,也为业界提供了理论和实践的指导。
会议的赞助商包括银牌、金牌和青铜赞助商,以及一家白金赞助商,这些赞助商的参与体现了存储行业对这一活动的重视和支持。此外,媒体赞助商和产业合作伙伴如ACM Queue、ADMIN magazine、Linux Pro Magazine等,也通过报道和宣传扩大了会议的影响力,促进了存储技术的交流与传播。
FAST'16的参与者有机会接触到最新的研究成果,包括但不限于以下主题:
1. **高性能存储系统**:研究如何提升存储系统的吞吐量和I/O效率,减少延迟,以适应大数据和云计算环境的需求。
2. **新型存储介质**:探讨闪存和其他非易失性内存技术,以及它们如何改变传统存储架构。
3. **数据保护与恢复**:研究备份策略、故障恢复技术和数据冗余,确保数据的完整性和可用性。
4. **存储安全**:关注加密技术、访问控制和隐私保护,以应对日益增长的网络安全威胁。
5. **分布式存储**:分析分布式文件系统的设计与实现,解决大规模数据管理和共享问题。
6. **能源效率**:探索节能存储解决方案,降低数据中心的能耗。
7. **软件定义存储**:讨论如何通过软件定义的方式灵活配置和管理存储资源。
这些论文和讨论对于研究人员、工程师和系统管理员来说是非常宝贵的学习资料,他们可以从中获取灵感,改进现有系统,或者开发新的存储解决方案。FAST 2016年会议的全文集合是一个深入了解存储技术前沿的重要资源。

USENIX Association 14th USENIX Conference on File and Storage Technologies (FAST ’16) 5
second pass replays the logical entries in the log. After
the next checkpoint, the log is discarded, and the refer-
ence counts on all nodes referenced by the log are decre-
mented. Any nodes whose reference count hits zero (i.e.
because they are no longer referenced by other nodes in
the tree) are garbage collected at that time.
Implementation. BetrFS 0.2 guarantees consistent re-
covery up until the last log flush or checkpoint. By de-
fault, a log flush is triggered on a sync operation, every
second, or when the 32 MB log buffer fills up. Flush-
ing a log buffer with unbound log entries also requires
searching the in-memory tree nodes for nodes contain-
ing unbound messages, in order to first write these nodes
to disk. Thus, BetrFS 0.2 also reserves enough space at
the end of the log buffer for the binding log messages.
In practice, the log-flushing interval is long enough that
most unbound inserts are written to disk before the log
flush, minimizing the delay for a log write.
Additional optimizations. Section 5 explains some op-
timizations where logically obviated operations can be
discarded as part of flushing messages down one level of
the tree. One example is when a key is inserted and then
deleted; if the insert and delete are in the same message
buffer, the insert can be dropped, rather than flushed to
the next level. In the case of unbound inserts, we allow
a delete to remove an unbound insert before the value
is written to disk under the following conditions: (1) all
transactions involving the unbound key-value pair have
committed, (2) the delete transaction has committed, and
(3) the log has not yet been flushed. If these conditions
are met, the file system can be consistently recovered
without this unbound value. In this situation, BetrFS 0.2
binds obviated inserts to a special NULL node, and drops
the insert message from the B
ε
-tree.
4 Balancing Search and Rename
In this section, we argue that there is a design trade-off
between the performance of renames and recursive di-
rectory scans. We present an algorithmic framework for
picking a point along this trade-off curve.
Conventional file systems support fast renames at the
expense of slow recursive directory traversals. Each file
and directory is assigned its own inode, and names in
a directory are commonly mapped to inodes with point-
ers. Renaming a file or directory can be very efficient,
requiring only creation and deletion of a pointer to an in-
ode, and a constant number of I/Os. However, searching
files or subdirectories within a directory requires travers-
ing all these pointers. When the inodes under a directory
are not stored together on disk, for instance because of
renames, then each pointer traversal can require a disk
seek, severely limiting the speed of the traversal.
BetrFS 0.1 and TokuFS are at the other extreme. They
index every directory, file, and file block by its full path
in the file system. The sort order on paths guarantees that
all the entries beneath a directory are stored contiguously
in logical order within nodes of the B
ε
-tree, enabling fast
scans over entire subtrees of the directory hierarchy. Re-
naming a file or directory, however, requires physically
moving every file, directory, and block to a new location.
This trade-off is common in file system design. In-
termediate points between these extremes are possible,
such as embedding inodes in directories but not moving
data blocks of renamed files. Fast directory traversals re-
quire on-disk locality, whereas renames must issue only
a small number of I/Os to be fast.
BetrFS 0.2’s schema makes this trade-off parameteri-
zable and tunable by partitioning the directory hierarchy
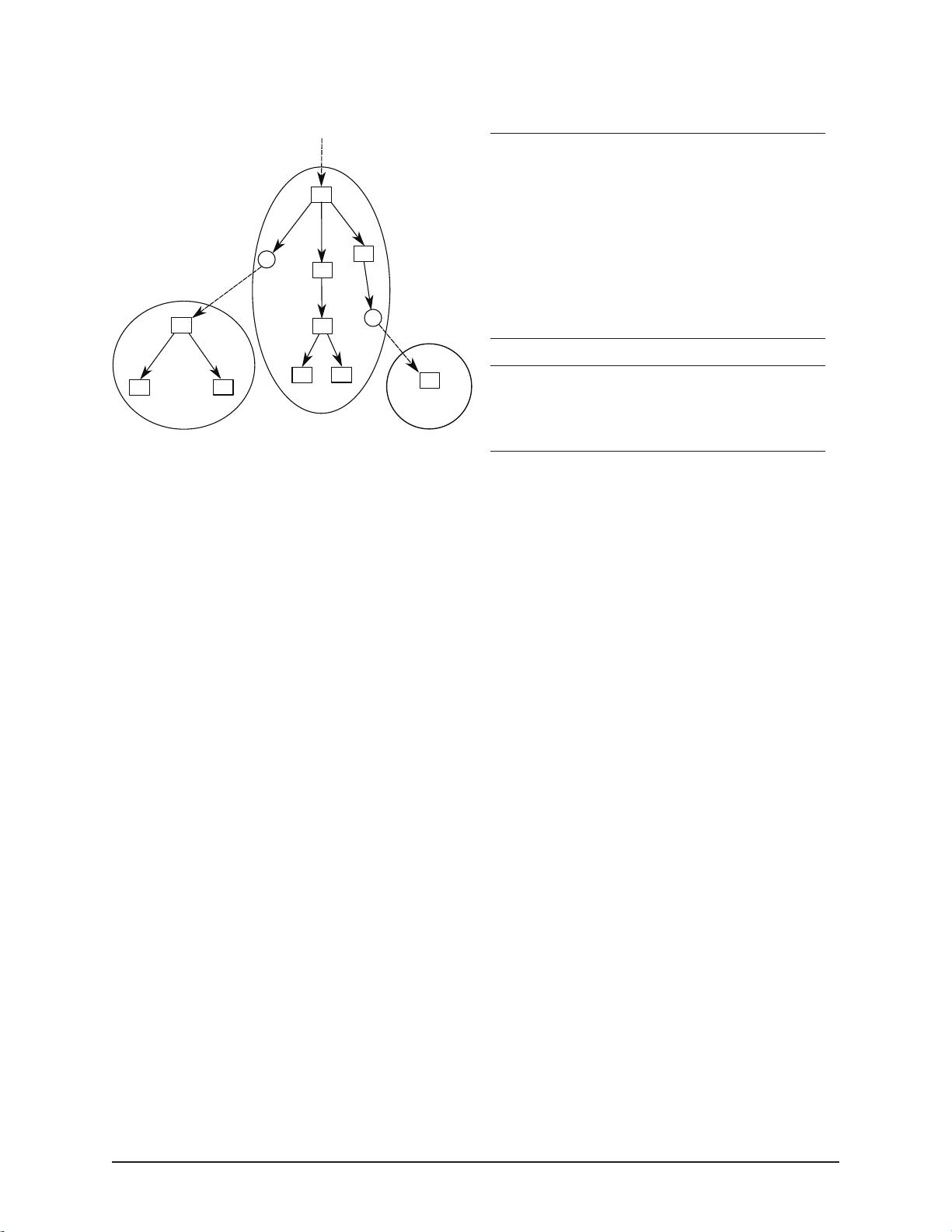
into connected regions, which we call zones. Figure 2a
shows how files and directories within subtrees are col-
lected into zones in BetrFS 0.2. Each zone has a unique
zone-ID, which is analogous to an inode number in a tra-
ditional file system. Each zone contains either a single
file or has a single root directory, which we call the root
of the zone. Files and directories are identified by their
zone-ID and their relative path within the zone.
Directories and files within a zone are stored together,
enabling fast scans within that zone. Crossing a zone
boundary potentially requires a seek to a different part of
the tree. Renaming a file under a zone root moves the
data, whereas renaming a large file or directory (a zone
root) requires only changing a pointer.
Zoning supports a spectrum of trade-off points be-
tween the two extremes described above. When zones
are restricted to size 1, the BetrFS 0.2 schema is equiv-
alent to an inode-based schema. If we set the zone size
bound to infinity (∞), then BetrFS 0.2’s schema is equiv-
alent to BetrFS 0.1’s schema. At an intermediate set-
ting, BetrFS 0.2 can balance the performance of direc-
tory scans and renames.
The default zone size in BetrFS 0.2 is 512 KiB. In-
tuitively, moving a very small file is sufficiently inex-
pensive that indirection would save little, especially in
a WOD. On the other extreme, once a file system is
reading several MB between each seek, the dominant
cost is transfer time, not seeking. Thus, one would ex-
pect the best zone size to be between tens of KB and a
few MB. We also note that this trade-off is somewhat
implementation-dependent: the more efficiently a file
system can move a set of keys and values, the larger a
zone can be without harming rename performance. Sec-
tion 7 empirically evaluates these trade-offs.
As an effect of zoning, BetrFS 0.2 supports hard links
by placing a file with more than 1 link into its own zone.
Metadata and data indexes. The BetrFS 0.2 meta-
5


剩余379页未读,继续阅读
2014-10-12 上传
2020-07-08 上传
2014-10-12 上传
2017-03-26 上传
点击了解资源详情
点击了解资源详情

muplj
- 粉丝: 1
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
