Transformer模型:注意力即一切
版权申诉
《Attention Is All You Need》是Ashish Vaswani等人于2017年在Google Brain团队发布的论文,标志着自然语言处理(NLP)领域一个重要的转折点。该研究论文主要关注的是深度学习中的序列转导模型,这些模型通常依赖于复杂的递归或卷积神经网络架构,包括编码器和解码器的设计。传统的模型结构中,编码器负责处理输入序列,而解码器负责生成目标序列,两者之间通过复杂的循环或者卷积层进行交互。
然而,这篇论文提出了Transformer这一新颖的网络结构,其核心创新在于完全摒弃了循环和卷积的机制,转而依赖于注意力机制。注意力机制允许模型在处理序列时,能够根据输入上下文动态地分配权重,而非固定地依赖于前一个时间步的信息。这使得Transformer能够在不牺牲性能的情况下,显著提高模型的并行化程度,因为每个位置可以独立计算其与输入序列的注意力权重。
实验结果表明,Transformer在机器翻译任务中表现出色,尤其是在英文到德文的WMT2014评测中,模型达到了28.4 BLEU分数,这比当时已有的最佳成绩有了显著提升。这一突破性成果证明了注意力机制在序列转导任务中的优越性,不仅在质量上超越了传统方法,而且在训练效率上也有显著优势。
Transformer的成功推广了注意力机制在NLP领域的应用,引领了后续许多模型设计的新潮流,如BERT、GPT等预训练模型,它们都深受Transformer架构的影响。这种简洁且高效的网络结构极大地推动了自然语言处理技术的发展,使得模型能够处理更长的序列,解决更大规模的问题,并且在实际部署中更加高效。此外,Transformer还启发了其他领域,如计算机视觉和强化学习,展示了注意力机制的强大通用性。Attention Is All You Need是自然语言处理史上一个里程碑式的贡献,它的出现彻底改变了序列模型的设计范式。
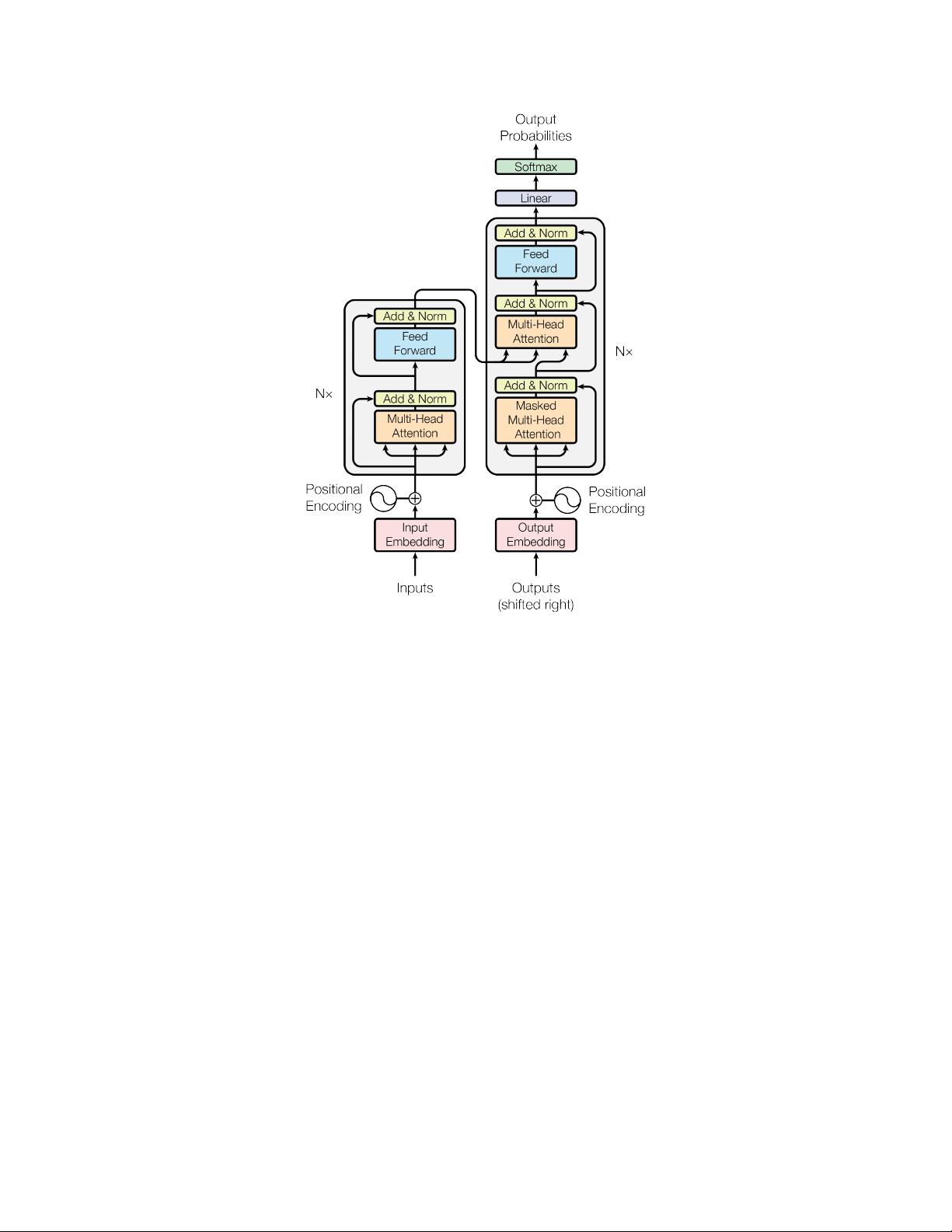
Figure 1: The Transformer - model architecture.
3.1 Encoder and Decoder Stacks
Encoder:
The encoder is composed of a stack of
N = 6
identical layers. Each layer has two
sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-
wise fully connected feed-forward network. We employ a residual connection [
11
] around each of
the two sub-layers, followed by layer normalization [
1
]. That is, the output of each sub-layer is
LayerNorm(x + Sublayer(x))
, where
Sublayer(x)
is the function implemented by the sub-layer
itself. To facilitate these residual connections, all sub-layers in the model, as well as the embedding
layers, produce outputs of dimension d
model
= 512.
Decoder:
The decoder is also composed of a stack of
N = 6
identical layers. In addition to the two
sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head
attention over the output of the encoder stack. Similar to the encoder, we employ residual connections
around each of the sub-layers, followed by layer normalization. We also modify the self-attention
sub-layer in the decoder stack to prevent positions from attending to subsequent positions. This
masking, combined with fact that the output embeddings are offset by one position, ensures that the
predictions for position i can depend only on the known outputs at positions less than i.
3.2 Attention
An attention function can be described as mapping a query and a set of key-value pairs to an output,
where the query, keys, values, and output are all vectors. The output is computed as a weighted sum
of the values, where the weight assigned to each value is computed by a compatibility function of the
query with the corresponding key.
3
剩余14页未读,继续阅读
相关推荐





方案互联
- 粉丝: 18
 我的内容管理
展开
我的内容管理
展开







最新资源
- 全面详实的大学生电工实习报告汇总
- 利用极光推送实现App间的消息传递
- 基于JavaScript的节点天气网站开发教程
- 三星贴片机1+1SMT制程方案详细介绍
- PCA与SVM结合的机器学习分类方法
- 钱能版C++课后习题完整答案解析
- 拼音检索ListView:实现快速拼音排序功能
- 手机mp3音量提升神器:mp3Trim使用指南
- 《自动控制原理第二版》习题答案解析
- 广西移动数据库脚本文件详解
- 谭浩强C语言与C++教材PDF版下载
- 汽车电器及电子技术实验操作手册下载
- 2008通信定额概预算教程:快速入门指南
- 流行的表情打分评论特效:实现QQ风格互动
- 使用Winform实现GDI+图像处理与鼠标交互
- Python环境配置教程:安装Tkinter和TTk
