"中科大2022年信息检索与数据挖掘课程作业答案及布尔查询合并算法的时间复杂度"
需积分: 5 114 浏览量
更新于2024-01-11
1
收藏 1.74MB PDF 举报
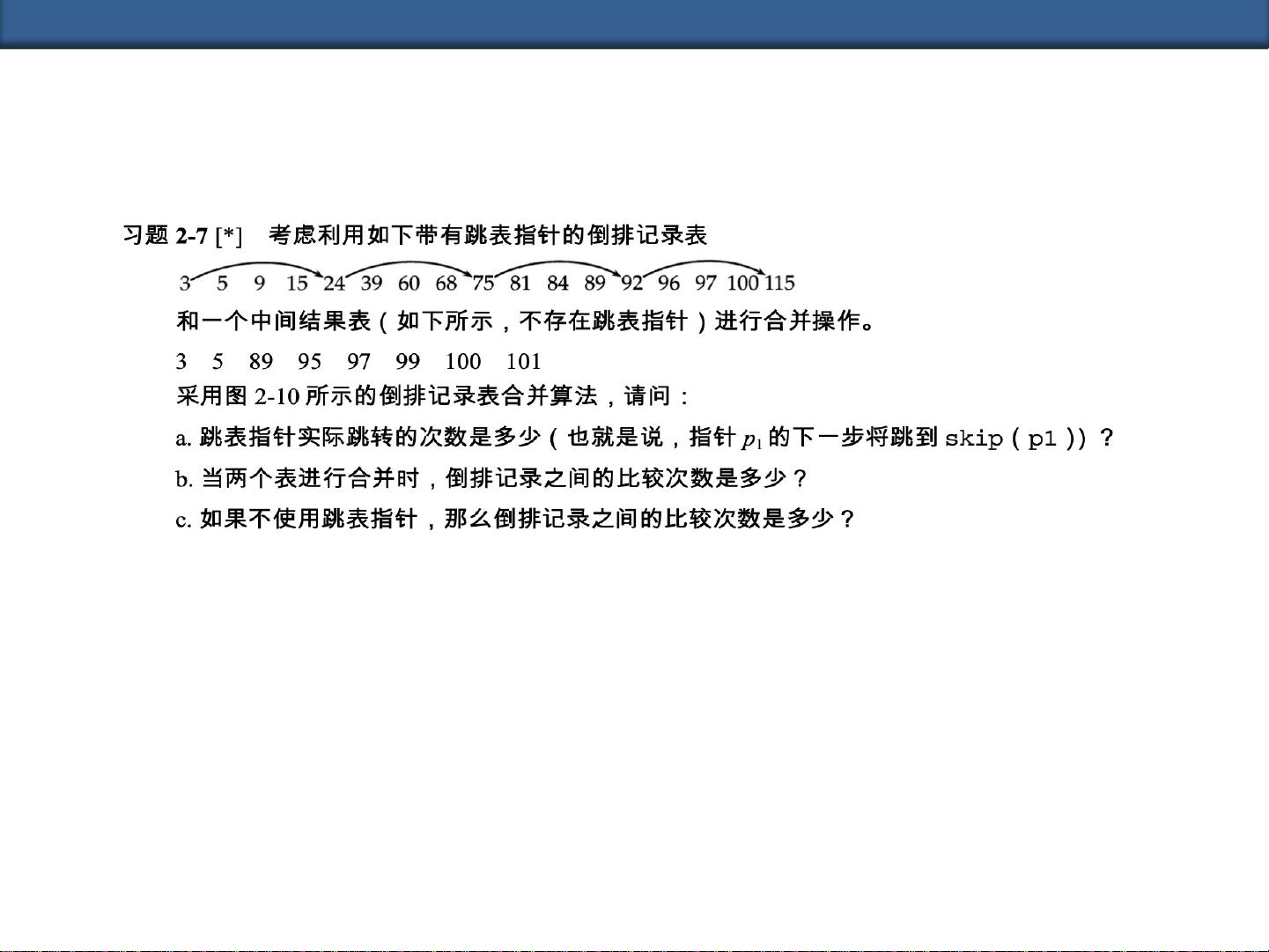
本文主要讨论了中科大信息检索与数据挖掘课程作业中关于倒排索引的合并算法的推广和复杂度问题。具体而言,该课程作业以布尔检索和倒排索引为主题,要求对给定的查询进行合并算法的推广,并讨论时间复杂度和如何改进合并算法。
查询是"(Brutus OR Caesar) AND NOT (Antony OR Cleopatra)",该查询由两个子查询组成,并使用了布尔运算符AND和NOT。
首先,通过布尔检索和倒排索引的知识可以将查询拆分为以下几个步骤进行处理:
1. 将子查询"Brutus OR Caesar"和"Antony OR Cleopatra"根据布尔运算符拆分为两个子子查询:"Brutus"、"Caesar"、"Antony"和"Cleopatra"。
2. 对每个子子查询,使用倒排索引找到相应的倒排记录表,并对每个倒排记录表进行合并。合并算法如下:
```
INTSECT p1, p2
1 answer = ∅
2 while p1 ≠ NULL and p2 ≠ NULL
3 if docID(p1) == docID(p2)
4 ADD(answer, docID(p1))
5 p1 = next(p1)
6 p2 = next(p2)
7 else if docID(p1) < docID(p2)
8 p1 = next(p1)
9 else
10 p2 = next(p2)
11 Return answer
```
在合并算法的过程中,通过比较倒排记录表中的docID来进行合并,具体步骤是首先将两个倒排记录表的指针指向第一个元素,然后通过比较docID来判断是否相等,并根据比较结果移动指针。如果docID相等,则将docID添加到答案结果中,并同时向后移动两个指针;如果docID不相等,则将较小的docID对应的指针向后移动一位。直到其中一个指针为NULL为止。
根据合并算法的特点可以得知,合并算法的操作次数取决于两个倒排记录表的长度,标记为x和y,并且合并算法的时间复杂度为𝑂(x+y)。
对于给定的查询"(Brutus OR Caesar) AND NOT (Antony OR Cleopatra)",可以看出,在合并操作中至少需要对4个倒排记录表进行合并,因此合并的操作次数为𝑂(4𝑥+4𝑦)。
从合并算法的时间复杂度的角度来看,合并操作需要线性地访问两个倒排记录表,并且最坏情况下需要遍历整个倒排记录表的所有元素。因此,线性是指对倒排记录表的整体遍历和比较操作。
为了提高合并算法的效率,可以考虑以下几个改进措施:
1. 对于较短的倒排记录表,可以首先遍历该表并使用散列索引将其存储到哈希表中。这样可以减少每次合并操作的比较次数。
2. 在合并操作中使用跳表等高效的数据结构来代替线性搜索,从而减少操作次数。
3. 对于倒排记录表,可以通过使用压缩编码和压缩存储等技术减少存储空间和提高读取速度。
综上所述,中科大信息检索与数据挖掘课程作业中关于倒排索引的合并算法的推广和复杂度问题讨论了布尔查询的合并算法推广、时间复杂度以及如何改进合并算法的效率。该作业通过布尔检索和倒排索引的知识,对给定的查询进行了拆分和合并操作,并讨论了合并算法的时间复杂度和可能的改进方法。


748 浏览量
504 浏览量
点击了解资源详情
253 浏览量
470 浏览量
点击了解资源详情

Hannibal.
- 粉丝: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android PRDownloader库:支持文件下载暂停与恢复功能
- Xilinx FPGA开发实战教程(第2版)精解指南
- Aprilstore常用工具库的Java实现概述
- STM32定时开关模块DXP及完整项目资源下载指南
- 掌握IHS与PCA加权图像融合技术的Matlab实现
- JSP+MySQL+Tomcat打造简易BBS论坛及配置教程
- Volley网络通信库在Android上的实践应用
- 轻松清除或修改Windows系统登陆密码工具介绍
- Samba 4 2级免费教程:Ubuntu与Windows整合
- LeakCanary库使用演示:Android内存泄漏检测
- .Net设计要点解析与日常积累分享
- STM32 LED循环左移项目源代码与使用指南
- 中文版Windows Server服务卸载工具使用攻略
- Android应用网络状态监听与质量评估技术
- 多功能单片机电子定时器设计与实现
- Ubuntu Docker镜像整合XRDP和MATE桌面环境
