Python下载文件的11种方法概览
6 浏览量
更新于2024-08-28
收藏 585KB PDF 举报
本文主要介绍了Python中下载文件的11种方法,重点讲解了使用requests和wget模块,以及处理重定向、分块下载大文件和并行批量下载等场景。
在Python编程中,下载文件是常见的任务之一。文章首先提到了使用`requests`库的方法,通过`get`函数获取URL内容并将其保存到本地文件。例如,可以这样下载一个文件:
```python
import requests
url = 'http://example.com/file'
response = requests.get(url)
with open('myfile', 'wb') as f:
f.write(response.content)
```
接着,文章介绍了`wget`模块,这是Python的一个包,可以直接调用`wget.download()`来下载文件。在安装了wget模块之后,可以像这样下载Python的logo图片:
```python
import wget
url = 'http://example.com/python_logo.png'
wget.download(url, 'path/to/save/image')
```
对于会重定向的URL,`requests`库提供了处理重定向的功能。通过将`allow_redirects`参数设置为`True`,可以确保在重定向后仍能正确下载文件:
```python
url = 'http://example.com/redirected_file'
response = requests.get(url, allow_redirects=True)
with open('myfile', 'wb') as f:
f.write(response.content)
```
对于大文件,为了避免一次性加载到内存中,可以采用分块下载。通过设置`stream=True`,然后逐块写入文件:
```python
url = 'http://example.com/large_file'
response = requests.get(url, stream=True)
chunk_size = 1024 # 1KB
with open('large_file', 'wb') as f:
for chunk in response.iter_content(chunk_size):
f.write(chunk)
```
最后,文章提到了如何并行下载多个文件,这通常用于提高效率。可以利用`concurrent.futures.ThreadPoolExecutor`来创建线程池并发执行下载任务:
```python
from concurrent.futures import ThreadPoolExecutor
import os
import time
def download_file(url, save_path):
response = requests.get(url)
with open(save_path, 'wb') as f:
f.write(response.content)
urls = [('file1', 'http://example.com/file1'), ('file2', 'http://example.com/file2')] # 二维列表,包含文件名和URL
start_time = time.time()
with ThreadPoolExecutor() as executor:
for file_name, url in urls:
executor.submit(download_file, url, os.path.join('downloads', file_name))
print(f"下载完成,总耗时:{time.time() - start_time}秒")
```
以上就是Python中下载文件的一些基本技巧,涵盖了单个文件下载、重定向处理、大文件分块下载以及多文件并行下载的实现方法。这些方法在实际开发中非常实用,可以根据具体需求选择合适的方式。
Python下载的下载的11种姿势种姿势(小结小结)
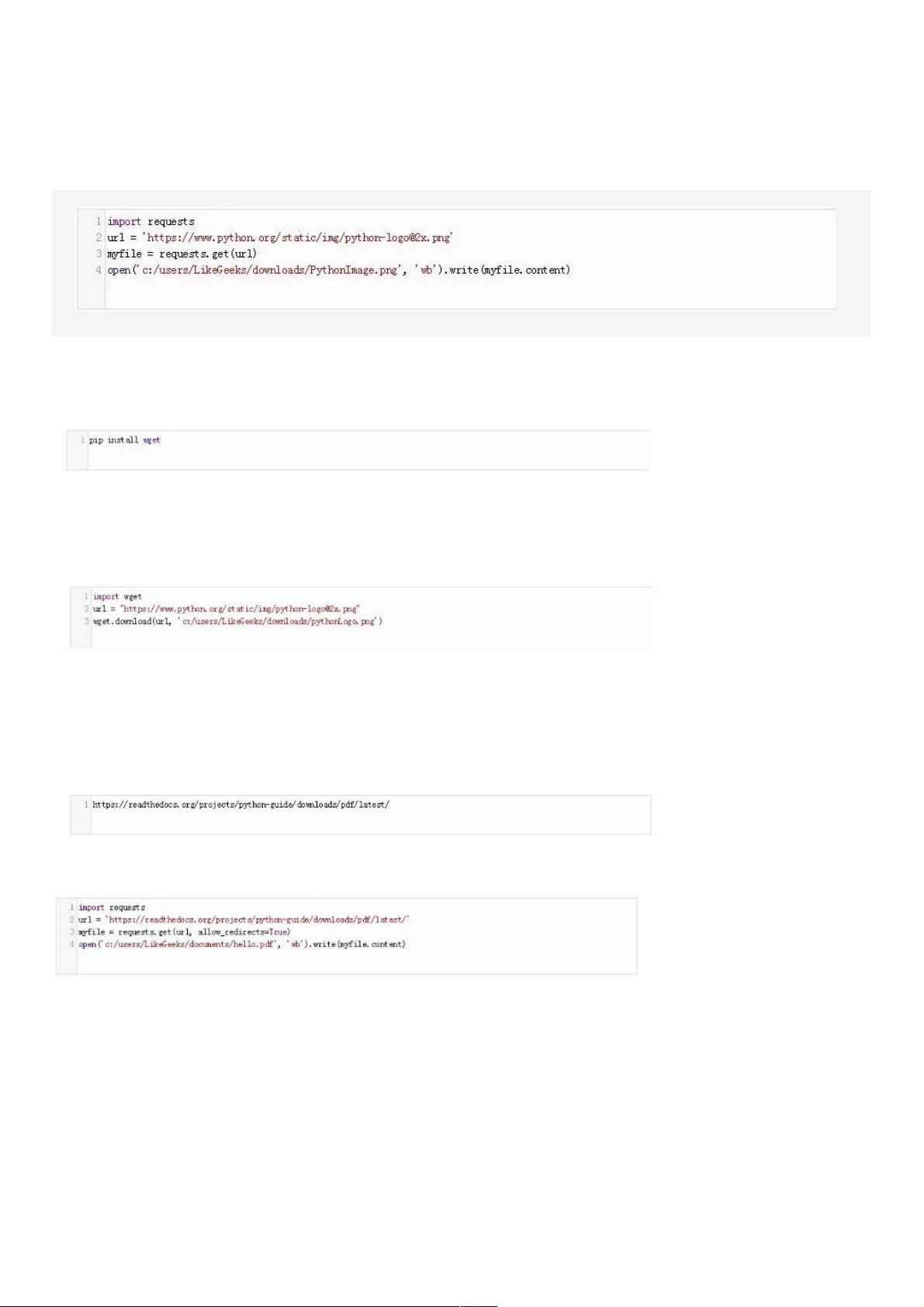
1、使用、使用requests
你可以使用requests模块从一个URL下载文件。
考虑以下代码:
你只需使用requests模块的get方法获取URL,并将结果存储到一个名为“myfile”的变量中。然后,将这个变量的内容写入文件。
2、使用、使用wget
你还可以使用Python的wget模块从一个URL下载文件。你可以使用pip按以下命令安装wget模块:
考虑以下代码,我们将使用它下载Python的logo图像。
在这段代码中,URL和路径(图像将存储在其中)被传递给wget模块的模块的download方法。方法。
3、下载重定向的文件、下载重定向的文件
在本节中,你将学习如何**使用requests从一个URL下载文件,**该URL会被重定向到另一个带有一个.pdf文件的URL。该URL看起
来如下:
要下载这个pdf文件,请使用以下代码:
在这段代码中,我们第一步指定的是URL。然后,我们使用我们使用request模块的模块的get方法来获取该方法来获取该URL。。在在get方法中,我们将方法中,我们将
allow_redirects设置为设置为True,这将允许,这将允许URL中的重定向中的重定向,并且重定向后的内容将被分配给变量myfile。
最后,我们打开一个文件来写入获取的内容。
4、分块下载大文件、分块下载大文件
考虑下面的代码考虑下面的代码:
下载后可阅读完整内容,剩余6页未读,立即下载
2022-04-27 上传
972 浏览量
731 浏览量

weixin_38546024
- 粉丝: 6
- 资源: 939
 我的内容管理
展开
我的内容管理
展开







最新资源
- 俄罗斯RTSD数据集实现交通标志实时检测
- 易语言开发的文件批量改名工具使用Ex_Dui美化界面
- 爱心援助动态网页教程:前端开发实战指南
- 复旦微电子数字电路课件4章同步时序电路详解
- Dylan Manley的编程投资组合登录页面设计介绍
- Python实现H3K4me3与H3K27ac表观遗传标记域长度分析
- 易语言开源播放器项目:简易界面与强大的音频支持
- 介绍rxtx2.2全系统环境下的Java版本使用
- ZStack-CC2530 半开源协议栈使用与安装指南
- 易语言实现的八斗平台与淘宝评论采集软件开发
- Christiano响应式网站项目设计与技术特点
- QT图形框架中QGraphicRectItem的插入与缩放技术
- 组合逻辑电路深入解析与习题教程
- Vue+ECharts实现中国地图3D展示与交互功能
- MiSTer_MAME_SCRIPTS:自动下载MAME与HBMAME脚本指南
- 前端技术精髓:构建响应式盆栽展示网站
