Apache Kafka:快速、可扩展的分布式消息系统
需积分: 0 76 浏览量
更新于2024-01-27
收藏 2.26MB PDF 举报
Apache Kafka是一种快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统,它能够高效地传递消息并适用于大规模消息处理应用程序。Kafka使用Scala与Java语言编写,并相比传统的消息中间件具有许多优势,如高吞吐量、内置分区、支持消息副本和高容错性。
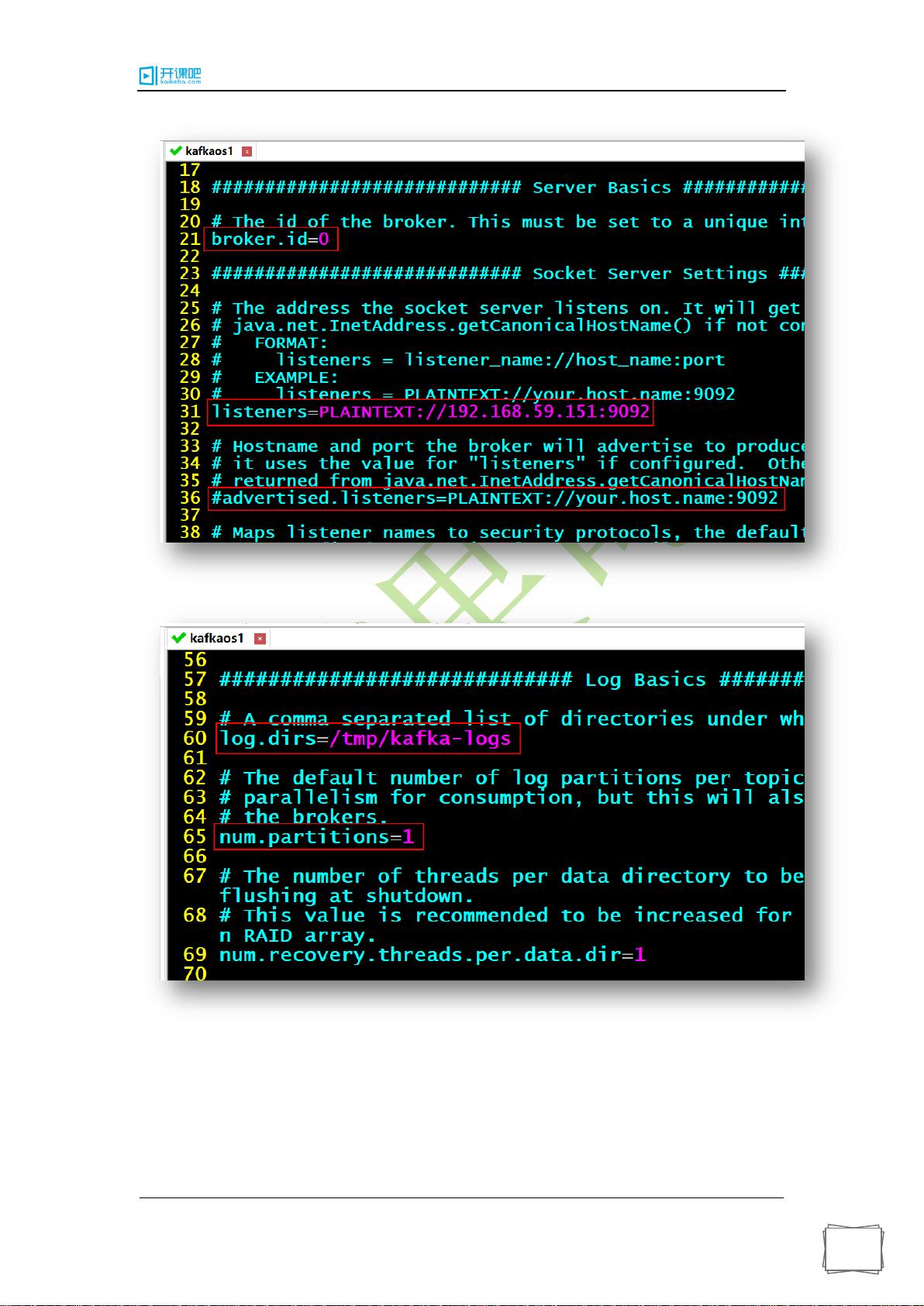
Kafka的系统架构包括以下几个核心组件:生产者(Producer)、消费者(Consumer)和代理服务器(Broker)。生产者负责向Kafka发送消息,而消费者负责订阅并处理这些消息。代理服务器则是消息的中转站,负责接收生产者发送的消息并将其存储在分布式集群中,同时将消息传送给消费者。
Kafka采用了流处理的思想,即将数据处理过程建模为一系列的事件流,并且能够实现实时处理。这种特性使得Kafka非常适用于诸如活动追踪、实时监测和日志收集等场景。例如,在用户的活动追踪场景中,用户在网站的不同活动消息会被发布到不同的主题中心,通过Kafka可以方便地对这些消息进行实时监测和分析。
Kafka提供了一种分布式的、高可靠性的消息传递机制。它通过将消息分割为多个分区并将其保存在不同的分布式存储节点上,实现了数据的高可用性和容错性。此外,Kafka还支持消息的副本功能,即可以将消息复制到不同的分布式存储节点上,以防止数据丢失。
Kafka还具有良好的可扩展性和高吞吐量的特点。它通过分布式存储和负载均衡的策略,能够在大规模数据处理场景下处理海量的消息。Kafka还支持水平扩展,可以根据需求添加更多的代理服务器和存储节点,以满足高吞吐量的需求。
总之,Apache Kafka是一种快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统,它通过高吞吐量、内置分区、支持消息副本和高容错性等特性,非常适合大规模消息处理应用程序。无论是在活动追踪、实时监测还是日志收集等场景下,Kafka都能够提供高效、可靠的消息传递机制,并能够满足高吞吐量的需求。对于开发人员来说,掌握Kafka这种分布式消息系统的使用和原理,将会对构建可靠、高效的大规模数据处理应用程序有很大的帮助。
分布式消息系统 Kafka
主讲:Reythor 雷
5
剩余28页未读,继续阅读
2020-08-20 上传
2023-04-24 上传
2020-02-18 上传
2020-01-22 上传
2022-04-06 上传
2022-04-19 上传
2022-12-23 上传

Java码库
- 粉丝: 1937
- 资源: 6100
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
