从静态到动态词向量:一项调查
需积分: 0 146 浏览量
更新于2024-06-30
收藏 1.17MB PDF 举报
"这篇论文是关于词向量表示的研究进展,从静态到动态的转变,主要探讨了在自然语言处理(NLP)中如何通过动态词嵌入来解决多义词问题,以及词嵌入的主要评估指标和应用,并讨论了跨语言场景下词嵌入的发展。关键词包括词表示、静态嵌入、动态嵌入和跨语言嵌入。"
在自然语言处理(NLP)领域,词的表示方法一直是研究的核心问题。传统的词向量,也称为静态词嵌入,如Word2Vec、GloVe等,它们通过学习大量文本数据,将词汇转化为固定维度的向量,这些向量能够捕捉词汇的语义和统计信息。然而,静态词嵌入存在一个问题,即无法处理同一词汇在不同上下文中的多义性,这对于理解和处理复杂的语言现象是个挑战。
动态词嵌入的出现,旨在解决这个问题。这些模型如Context2Vec、ELMo、BERT等,能够根据上下文信息动态地调整词的表示,使得同一个词在不同的语境中可以有不同的向量表示,从而更好地捕捉词汇的多义性和情境依赖性。例如,BERT(Bidirectional Encoder Representations from Transformers)通过Transformer架构,考虑了词语的前文和后文信息,生成的词向量更具有上下文敏感性。
论文中提到了对这些词嵌入模型的主要评估指标,这通常包括词汇相似度任务、问答系统、情感分析等NLP任务的性能比较。此外,词嵌入的应用广泛,涵盖了机器翻译、文本分类、情感分析、问答系统等多个领域。
在跨语言场景下,词嵌入的发展旨在促进不同语言之间的理解和转换。例如,XNLI(Cross-Lingual Natural Language Inference)这样的任务评估了模型在跨语言推理中的表现。跨语言词嵌入可以通过对齐不同语言的词嵌入空间,实现不同语言间的词汇对应和信息传递。
最后,作者指出了目前的一些开放问题和未来的研究方向。这可能包括如何进一步提高动态词嵌入的效率,优化跨语言表示学习,以及如何在低资源语言环境下有效利用词嵌入等。随着深度学习技术的不断发展,词嵌入的研究将持续深化,为NLP领域的进步提供关键支持。
International Journal of Machine Learning and Cybernetics
1 3
Note that
x =(C(w
t−1
);C(w
t−2
); … ;C(w
t−n+1
))
is the concat-
enation of input distributed vectors. Then the probability of
each output word
w
t
is computed with a softmax function:
The model is trained by maximizing the following penalized
objective function:
where T is the number of training samples,
𝜃
is the overall
parameters (including those of the neural network and the
embedding matrix C) and
R(𝜃)
is a regularization term with
weight
𝜆
.
Following the idea of using distributed representations
from NNLM, a Log-Bilinear Language Model [79] was pro-
posed, where a bilinear function is used to compute the prob-
ability of the next word instead of the feed-forward network
in NNLM. More formally, the unnormalized probability is
computed as follows:
where
W
i
∈ ℝ
d×d
specifies the interaction between
C(w
i
)
and
C(w
t
)
,
𝜎
is the softmax function, and biases are omitted
for simplicity. Later the Hierarchical Log-Bilinear Model
(HLBL) [80] was proposed based on the Log-Bilinear Lan-
guage Model to speed-up its predicting stage.
A major deficiency of NNLM is that the feed-forward
network can only observe a fixed length of context, which
hinders it from exploiting longer context. Therefore, Recur-
rent Neural Networks (RNNs) are then used to replace the
feed-forward network in the Recurrent Neural Network
Language Model (RNNLM), which effectively reduces the
perplexity [73].
2.2.2 SENNA
In all the works introduced above, distributed representa-
tions are only regarded as by-products of language mod-
els. Aiming at making use of the strong capability of such
embeddings to facilitate more NLP tasks, a Semantic Extrac-
tion using a Neural Network Architecture (SENNA) system
was proposed [20], where distributed embeddings are trained
in a language model with a large amount of unlabeled data,
and then used as input to downstream tasks including POS
tagging, chunking, Named Entity Recognition (NER) and
Semantic Role Labeling (SRL).
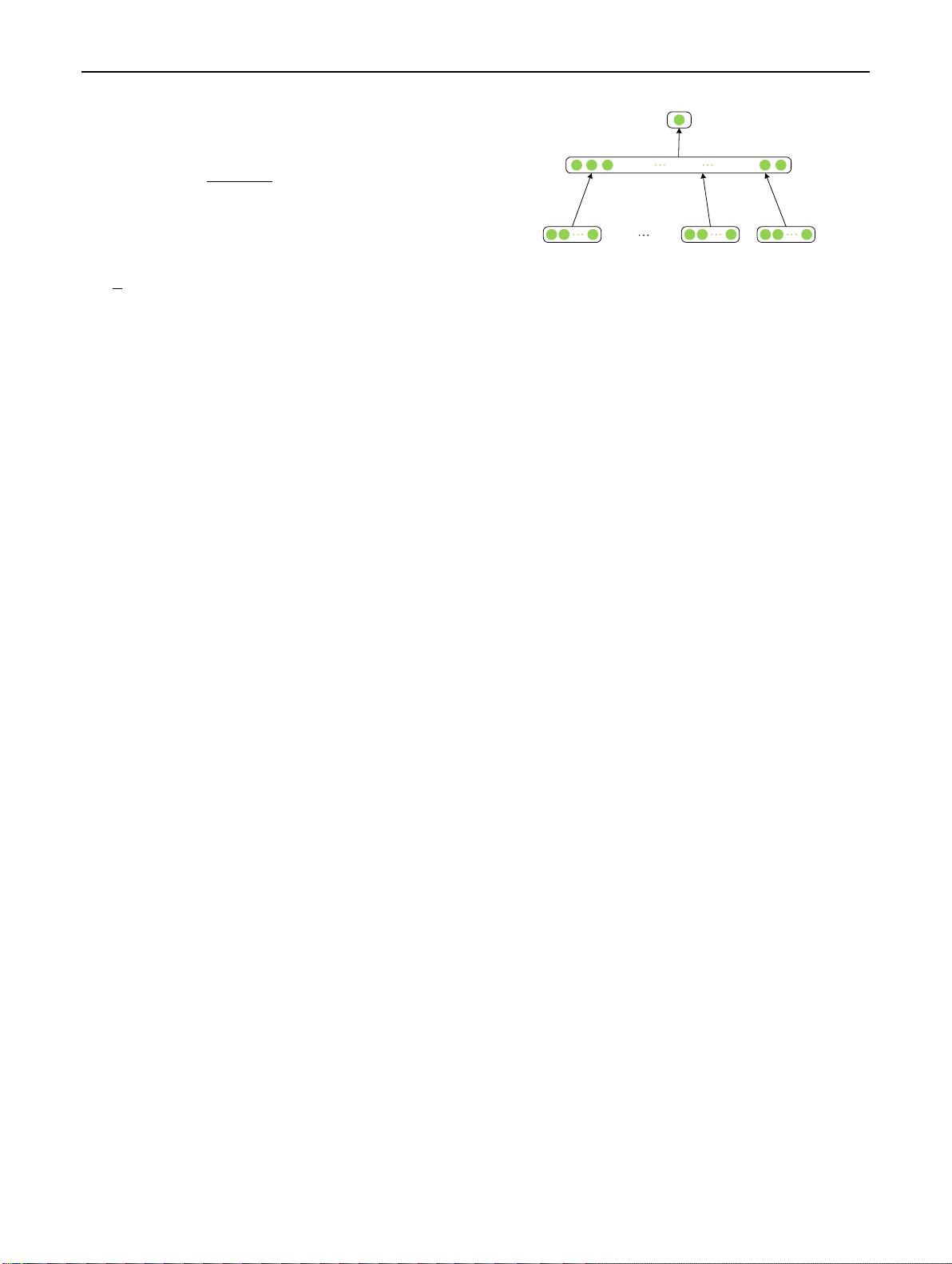
As depicted in Figure2, SENNA makes use of a neu-
ral network to train the language model which is similar to
P
(w
t
�
w
t−n+1∶t−1
)=
exp(y
t
)
∑
i
exp(
y
i
)
.
L
=
1
T
∑
t
log P(w
t
|
w
t−n+1∶t−1
;𝜃)+𝜆 ⋅ R(𝜃)
,
P
(w
t
|
w
t−n+1∶t−1
)=𝜎(C(w
t
)
⊤
t−1
∑
i=t−n+1
W
i
C(w
i
))
,
NNLM. But instead of estimating the probability of a word
given the previous words, it computes scores describing the
acceptability of a piece of text. This is because computing
the normalization term of the probability with large diction-
ary size is extremely demanding, and sophisticated approxi-
mations are required. Therefore, in SENNA they instead use
a pairwise ranking approach, seeking a network that assigns
higher scores to legal phrases than to incorrect ones.
Formally, let
f
𝜃
(c)
be the output score given a window of
text
c =(w
1
, w
2
, … , w
n
)
, then the language model is trained
by minimizing a hinge loss with respect to parameters
𝜃
in
the network:
where
T
is the set of all possible text windows with n words,
D
is the word dictionary, and
c
(w)
represents a text window
obtained by randomly replacing the central word of c with
word w.
Practically, n was set to 11 in the paper, and it took 7
weeks to train the embeddings on a large amount of unla-
beled data. These embeddings are then used as input to four
supervised tasks (i.e. POS tagging, chunking, NER and
SRL) in a similar network, where significant improvements
have been observed.
2.2.3 CBOW andSkip‑gram
SENNA innovatively applied the distributed representation
to a bunch of NLP tasks other than language modeling, and
demonstrated its capability of capturing textual information
from unlabeled data to facilitate downstream tasks. How-
ever, the training of it is extremely time-consuming. Later,
two prominent architectures, namely Continuous Bag-of-
Words (CBOW) model and Skip-gram model [74], were pro-
posed where the computational complexity is substantially
reduced by simplifying the network architecture.
Concretely, the CBOW model predicts a word given its
context. Fig.3 shows its architecture, which is similar to
L
=
∑
c∈
T
∑
w∈
D
max{0, 1 − f
𝜃
(c)+f
𝜃
(c
(w)
)}
,
C(w
n-1
)C(w
1
) C(w
n
)
hard tanh
acceptability score
W, b
Fig. 2 Neural network architecture of SENNA
剩余19页未读,继续阅读
2023-06-02 上传
2023-06-02 上传
2023-07-28 上传
2023-03-31 上传
2024-05-31 上传
2023-09-28 上传
2023-05-18 上传

李多田
- 粉丝: 484
- 资源: 333
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端面试必问:真实项目经验大揭秘
- 永磁同步电机二阶自抗扰神经网络控制技术与实践
- 基于HAL库的LoRa通讯与SHT30温湿度测量项目
- avaWeb-mast推荐系统开发实战指南
- 慧鱼SolidWorks零件模型库:设计与创新的强大工具
- MATLAB实现稀疏傅里叶变换(SFFT)代码及测试
- ChatGPT联网模式亮相,体验智能压缩技术.zip
- 掌握进程保护的HOOK API技术
- 基于.Net的日用品网站开发:设计、实现与分析
- MyBatis-Spring 1.3.2版本下载指南
- 开源全能媒体播放器:小戴媒体播放器2 5.1-3
- 华为eNSP参考文档:DHCP与VRP操作指南
- SpringMyBatis实现疫苗接种预约系统
- VHDL实现倒车雷达系统源码免费提供
- 掌握软件测评师考试要点:历年真题解析
- 轻松下载微信视频号内容的新工具介绍
